重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Cluster Linking によるデータ移行¶
Looking for Confluent Platform Cluster Linking docs? You are currently viewing Confluent Cloud documentation. If you are looking for Confluent Platform docs, check out Cluster Linking on Confluent Platform.
概要¶
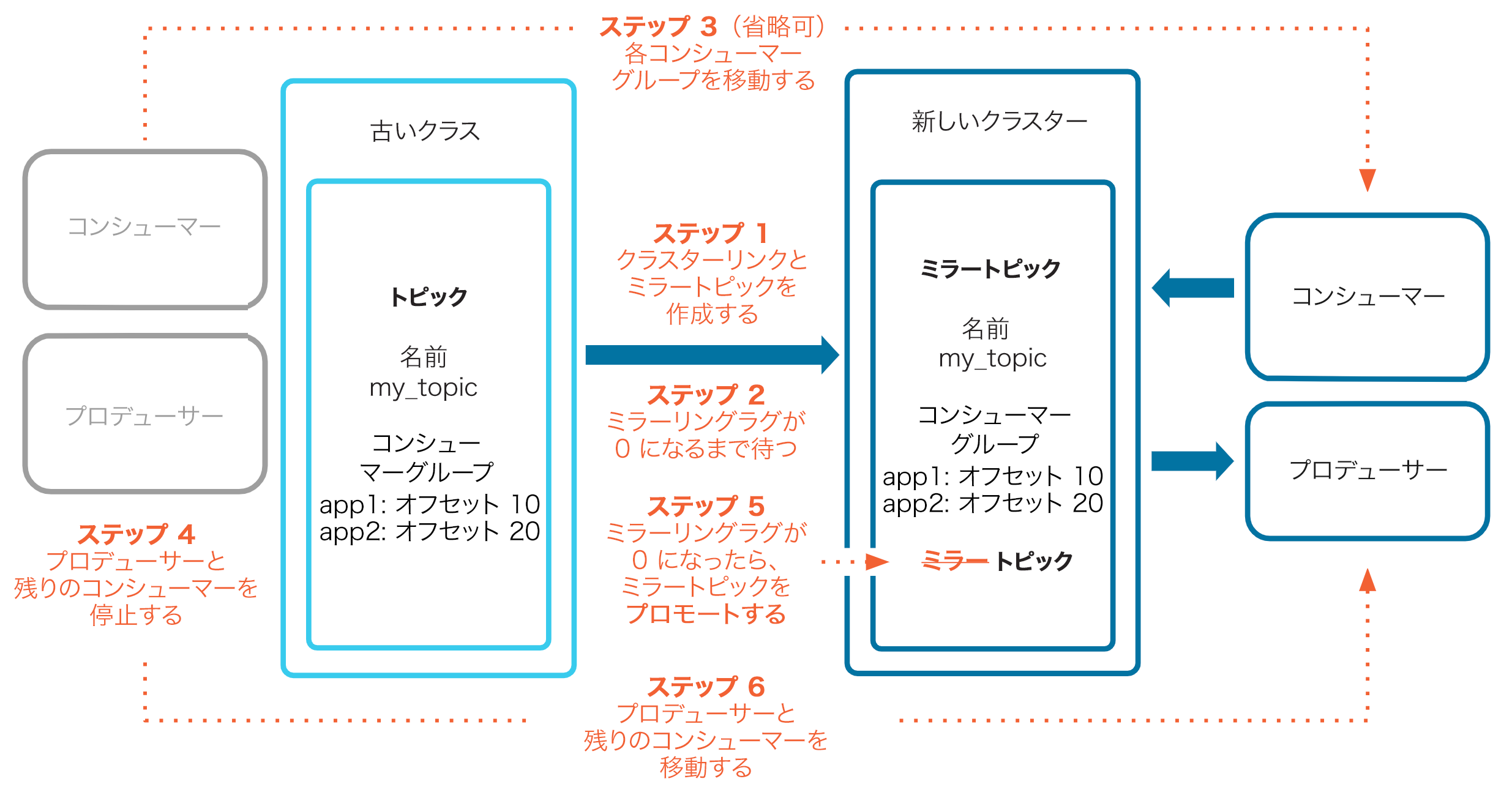
古いクラスターから新しいクラスターにデータを移行するときに、Cluster Linking はトピックの同一コピーを新しいクラスターに作成します。このため、ダウンタイムが少なく、データ損失なしでデータ移動を簡単に行うことができます。
Cluster Linking では以下を実行できます。
- 同じ構成を持った、一致する "mirror" トピックを自動的に作成するので、手動でトピックを再作成する必要がありません
- すべての履歴データと新規データを既存のトピックから新しいミラートピックに同期します
- コンシューマーオフセットを同期するので、コンシューマーはメッセージを欠落させたり、重複して消費したりすることなく、中断したところから正確に再開することができます
- コンシューマーを古いクラスターから新しいクラスターに個別に移動します
- プロデューサーを古いクラスターから新しいクラスターにトピックごとに移動します
成功事例¶
Cluster Linking を使用した移行の成功事例について詳しく読む:
- Wealthsimple の Maker Stories で公開された「New Kafka Tier, No Kafka Tears」では、移行に Cluster Linking を使用した既存の Kafka システムのスケールアップについて説明しています
- Confluent Sets Data in Motion Across Hybrid and Multicloud Environments for Real-Time Connectivity Everywhere details SAS's success migrating large Kafka clusters with Cluster Linking under the subheading "Cluster Linking: Seamlessly Connect Applications and Data Systems Across Hybrid and Multicloud Architectures"
- 具体的には、「Everywhere: Cloud Cluster Linking」内のデータ移行プロジェクトをサブトピック「Simplify geo-replication and multi-cloud data movement with Cluster Linking」で説明してます。
Cluster Linking による標準的な移行¶
以下のセクションでは、Cluster Linking を使用して、あるクラスターから別のクラスターにデータを移行する一般的な手順を説明します。
ステップ 1: 2 つのクラスター間にクラスターリンクを作成する¶
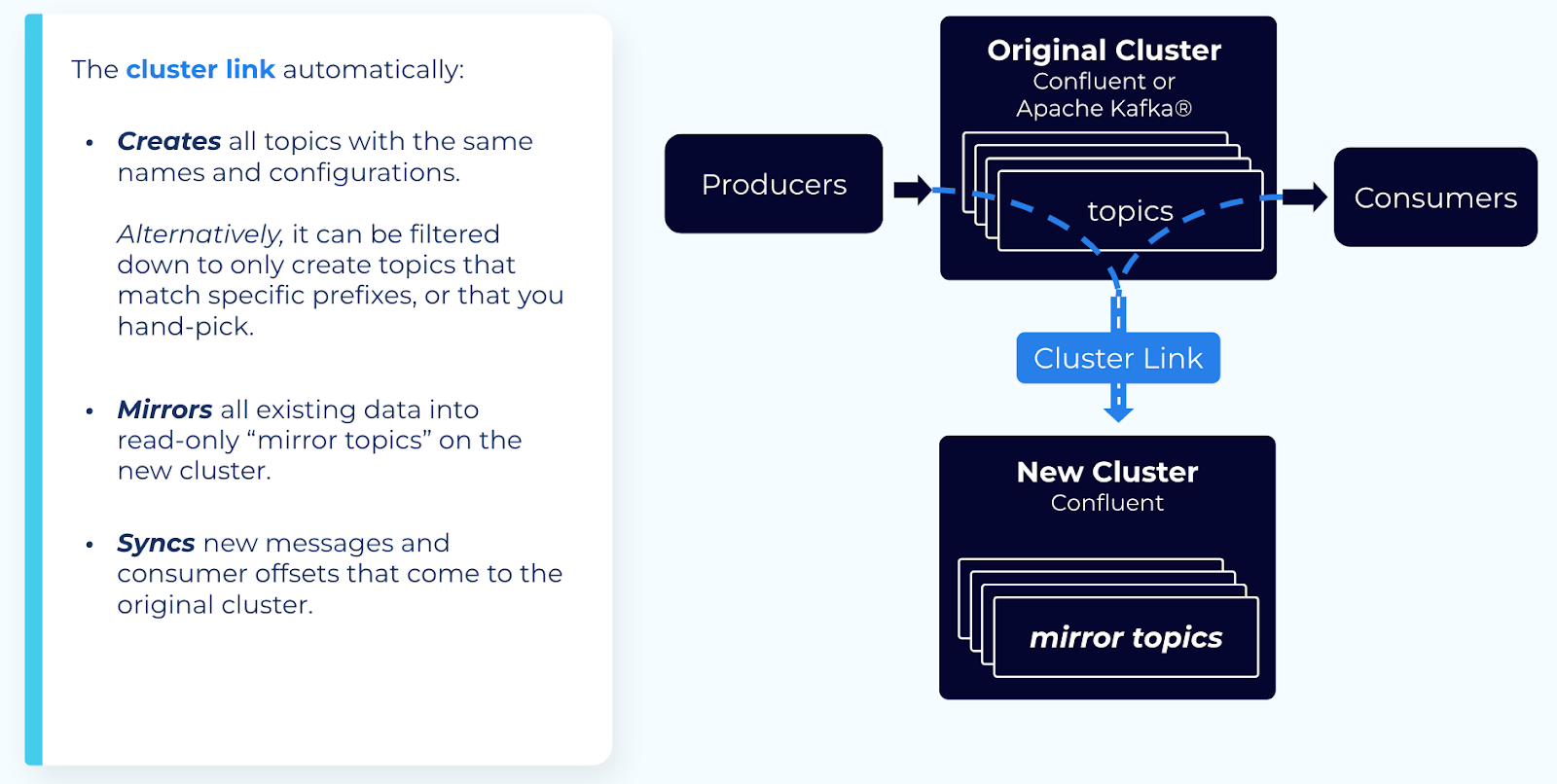
次の構成を使用してクラスターリンクを作成します。
ミラートピックの自動作成 を有効にします。
これによって、Cluster Linking は古いクラスター上の既存のすべてのトピックについて、新しいクラスター上にミラートピックを自動的に作成します。必要に応じて特定のプレフィックスでフィルター処理できます。
または、クラスターリンクを作成した後に、CLI または REST API によってミラートピックを個々に作成することもできます。
consumer offset syncを有効にします(「クラスターリンクの動作の構成」のコンシューマーオフセット構成を参照)。これにより、古いクラスターから新しいクラスターへのコンシューマーオフセットが同期されます。必要に応じて特定のコンシューマーグループでフィルター処理できます。
デフォルトでは、同期は 30 秒ごとに発生します。古いクラスターから新しいクラスターへの切り替え時にコンシューマーダウンタイムを最小化するために、この秒数を最小の 1 秒に設定できます。コンシューマーオフセットはクラスターリンクがミラーリングするデータの一部です。つまり、同期を頻繁に行うほど、データの高スループットが犠牲になります。Confluent Cloud でのデータの合計スループットは、「メトリクスとモニタリング」の「ミラーリングスループット」で示すメトリクスを使用してモニタリングできます。
2 つの Confluent Cloud クラスター間、または同じセキュリティシステムを持つ 2 つの Confluent Platform / Apache Kafka® クラスター間での移行の場合、ACL 同期 を有効にします。必要に応じて、特定のリソースやプリンシパルなどでフィルター処理できます。
ちなみに
これは、別のプラットフォームから Confluent Cloud への移行には役立ちません。Confluent Cloud では独自の認証システムが使用されるからです。
ステップ 2: ミラーリングラグがゼロ(0)に近づくまで待つ¶
ミラーリングラグ がほとんどゼロ(0)になったら、トピックの既存のデータが新しいクラスターにミラーリングされたことを意味します。
これにより、最小のダウンタイムでコンシューマーとプロデューサーを切り替えることができます。
特定のトピックを他のトピックよりも先に準備する場合は、他のトピックに対するミラーリングを一時停止して、それら特定のトピックを優先することができます。このようにすると、より多くのスループットが優先したトピックに割り振られます。
着信データの処理に関してクラスターリンクが追いつかず、ミラーリングラグを 0 に近づけることができない場合、他のトピックのミラーリングを一時停止して特定のトピックを優先する必要があるかもしれません。
(省略可)ステップ 3: コンシューマーグループを古いクラスターから新しいクラスターに移動する¶
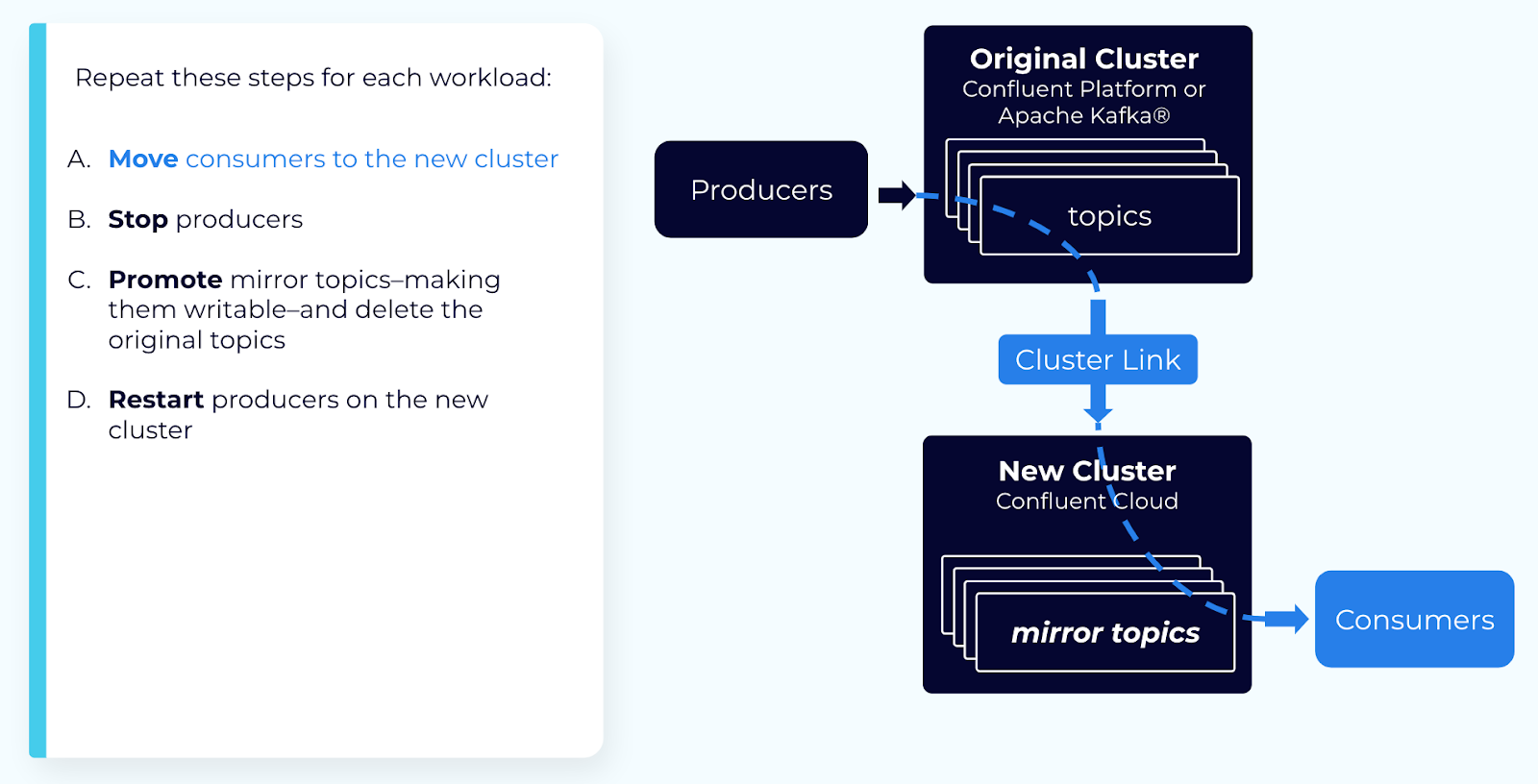
必要であれば、各コンシューマーグループを個別に移動できます。コンシューマーオフセットは同期されるため、コンシューマーは中止した同じポイントから再開します。コンシューマーグループを移動するには、以下の手順を実行します。
古いクラスターのコンシューマーグループを停止します。
少なくとも
consumer.offset.sync.ms(デフォルトは 30 秒)待って、最新のオフセットが同期されるようにします。consumer.offset.group.filters設定で、クラスターリンクからコンシューマーグループの名前を除外します。コンシューマーグループが属するトピックオフセットがミラートピックに同期されたことを確認します。
これは、該当のコンシューマーラグ、ミラーリングラグの順に表示させて確認できます。
新しいクラスターでコンシューマーを開始する前に、コンシューマーのいるオフセットがミラートピックにミラーリングされたことを確認する必要があります。コンシューマーがミラーリングよりも先に開始した場合、そのオフセットはトピック内の最新のオフセットにリセットされ、二重に消費されます。
たとえば、コンシューマーがあるパーティションのオフセット 100 にいるのに、ミラートピックがまだオフセット 90 のときにコンシューマーを開始した場合、コンシューマーはトピックの最後から消費を開始し、メッセージ 90 ~ 100 を再消費することになります。
新クラスターのコンシューマーグループを再開します。
ステップ 4: プロデューサーとコンシューマーを停止する¶
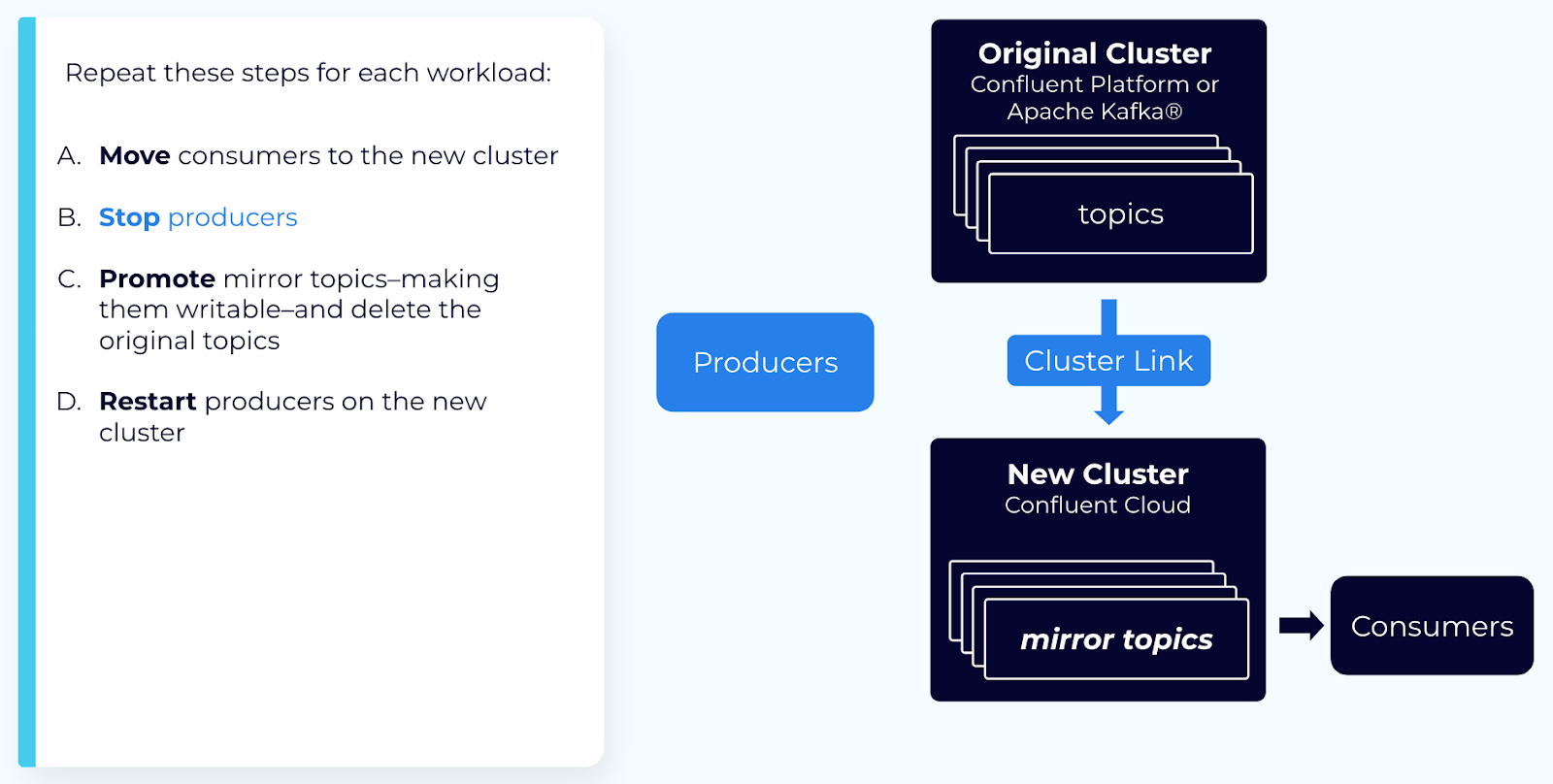
すべてのプロデューサーと、残っているコンシューマーをすべて停止します。これにより、クラスターリンクは新規メッセージを受信することなく、"追いつく" 機会を得ることができます。
ステップ 5: ミラートピックをプロモートする¶
注意
Make sure that you’ve stopped all producers and consumers on the source topic on your original cluster. After you call promote, mirroring and consumer offset sync stop permanently. After promote, if any producers produce messages to the source topic on the original cluster, those messages will not be migrated. After promote, if any consumers consume messages from the source topic on the original cluster, their offsets will not be synced, and they will consume duplicates when they move to the new cluster.
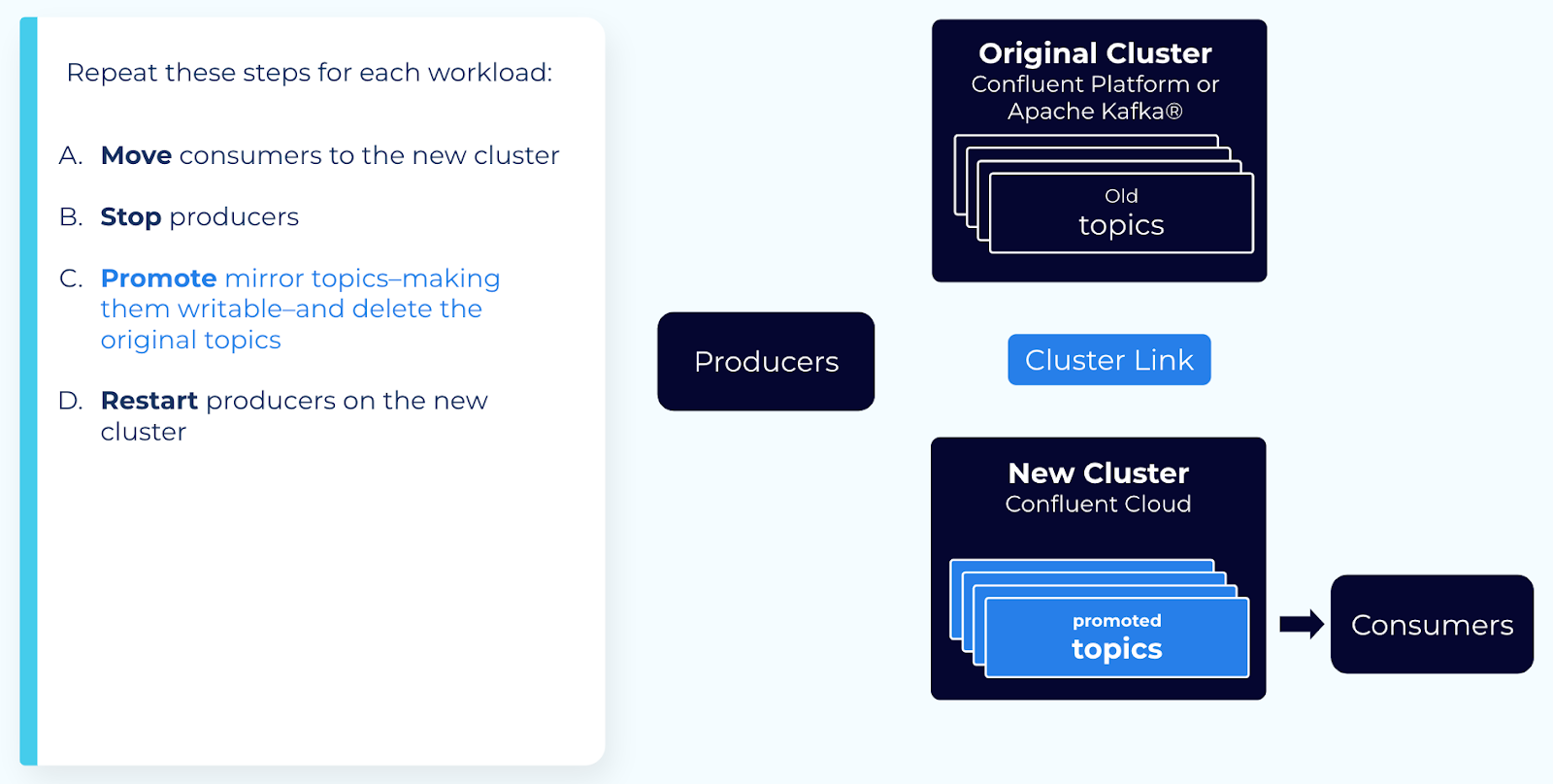
ミラーリングラグが 0 になったら、ミラートピックで promote Cluster Linking API を呼び出します。
これにより、ミラートピックが、通常の書き込み可能なトピックに変換されます。
ミラーリングラグがゼロ(0)になるのを待って、すべてのメッセージが新しいクラスターにレプリケートされたことを確認する必要があります。promote コマンドは、続行する前にトピックが遅延していないことを確認しますが、ユーザーもまた、ミラーリングラグメトリックを確認する必要があります。
ステップ 6: プロデューサーとコンシューマーを再開する¶
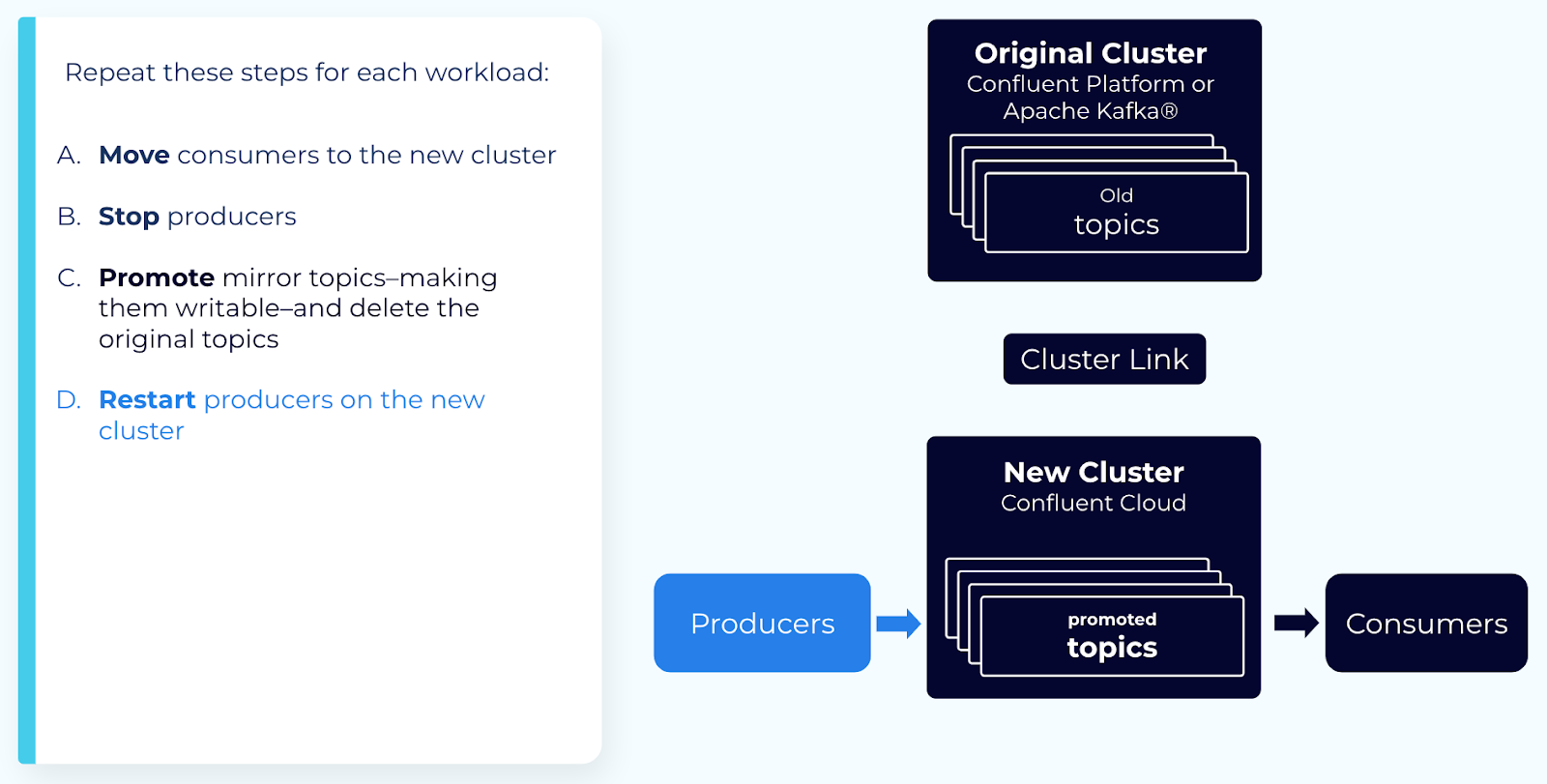
プロデューサーと残りのコンシューマーを新しいクラスターで再起動します。
これでトピック、プロデューサー、コンシューマーが新しいクラスターに移動されました。
Step 7: Extra steps when leaving some consumers on the original cluster¶
If you want to leave some of your consumer groups on your original cluster, you must take some extra steps. You will need to get mirroring flowing in the reverse direction: from your new cluster back to your original cluster.
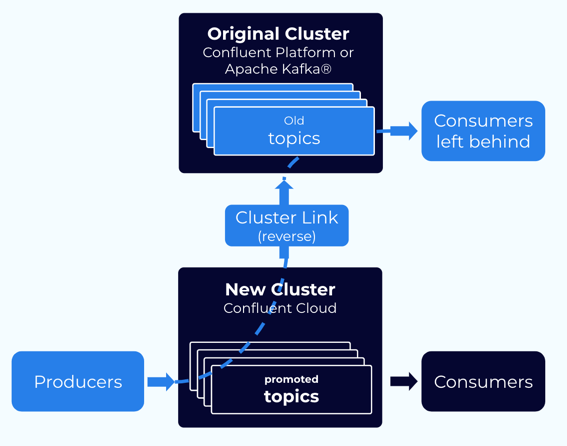
注釈
- A given consumer group should only consume from one cluster. A consumer group cannot be “stretched” between two clusters.
- This strategy is only available for Confluent clusters, not for Apache Kafka® clusters, as Cluster Linking cannot move data to an Apache Kafka® cluster.
- Make sure that the cluster link you used for migration was mirroring these consumer group offsets too; even though the consumers won’t move. The consumer offsets will temporarily be on the new cluster.
- Make sure that your consumer group(s) have stopped consuming (in step 4, above).
- Delete the original topics on the original cluster.
- Create a cluster link in the reverse direction: from the new cluster to the original cluster. Have this cluster link sync the consumer offsets for these consumer groups. This will move the consumer offsets back to the original cluster.
- Create mirror topic(s) on the original cluster. This will start data flowing from the new cluster to the original cluster.
- Once the mirror topic has mirrored up to the offsets where the consumer group(s) were, exclude those consumer group(s) from the cluster link’s consumer offset sync. This will stop the cluster link from syncing their consumer offsets.
- Restart the consumer group(s) on the original cluster. (See the caveats in step 3, above.)
Using an Apache Kafka® or Confluent Platform Source Cluster¶
To use an Apache Kafka® or Confluent Platform source cluster, your source cluster must be either:
- Accessible through public IPs for Confluent Cloud to reach out to, with the following requirements:
- You will need to know your source cluster’s bootstrap server and cluster ID in order to use it.
You can find the source cluster ID with the command-line tool
kafka-cluster cluster-idthat comes with Confluent Platform and Apache Kafka®. Your cluster’s administrator will know its bootstrap server. - If your source cluster is set up with security, you will need to provide security credentials to your cluster link’s configuration, as described in Confluent Platform と Kafka の送信元クラスターに対するセキュリティ認証情報の構成.
- You will need to know your source cluster’s bootstrap server and cluster ID in order to use it.
You can find the source cluster ID with the command-line tool
Or,
- Running Confluent Platform 7.1+, using source-initiated cluster links, and have access to the Confluent Cloud destination cluster. To learn more about this configuration, see ハイブリッドクラウドとクラウドへのブリッジ.
代替の移行戦略¶
特定のトピックについて同時にすべてのプロデューサーを移動できない場合は、2 つの代替方法を検討できます。いずれも Cluster Linking を使用した標準的な移行方式よりも多くの手間がかかります。
Cluster Linking を使用した双方向¶
ミラートピックは読み取り専用です。したがって、一部のプロデューサーを移行し、他のプロデューサーを移行しない場合、それらのプロデューサーが新しいクラスターのミラートピックに書き込むことはできません。そうしたイベントを書き込む別のトピックが必要になり、それらのイベントは、まだ移動していないコンシューマーのために、古いクラスターに再度同期する必要があります。また、コンシューマーに対して一部変更を行い、両方のクラスターに生成されたイベントを取得できるようにする必要もあります。
特定のトピックに対して、3 つの新規トピックを設定できます。
新しいクラスターに、同じ名前で新しい定期的なトピックを追加する。このトピックは新しいクラスターに対して生成される新規イベントを受信します。
新しいクラスター上のミラートピック。このトピックは履歴データおよび古いクラスターに対して生成された新しいイベントをミラーリングします。このトピックには、書き込み可能なトピックと競合しないように、プレフィックスを付けます。
ちなみに
Confluent Cloud でのプレフィックス使用は 2022 年第 2 四半期初頭に可能になります。
古いクラスター上のミラートピック。このトピックは新しいクラスターからの書き込み可能なトピックをミラーリングします。これによって、新しいイベントは残っているコンシューマーのために古いクラスターに再度書き込まれます。
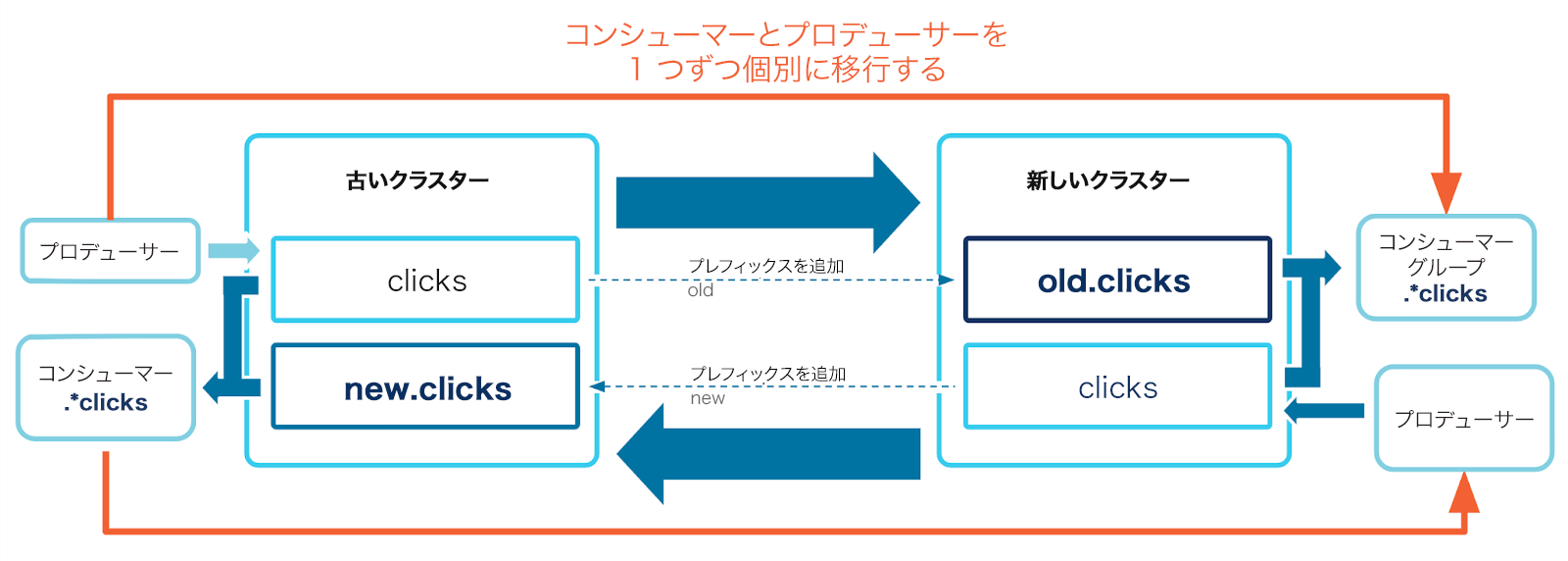
これが機能するためには、コンシューマーに対していくつかの変更を行う必要があります。
- コンシューマーは、トピック名の代わりに、両方のトピックを取得する正規表現パターンから消費する必要があります。たとえばトピックの名前が
clicksの場合、コンシューマーはパターン.*clicksから消費して、clicksトピックとプレフィックストピックの両方から消費することができます。 - コンシューマーグループを移動するときには、書き込み可能トピックの場合は新しいクラスターでオフセットを手動で設定する必要があります。これは "上流" への移動であるため、クラスターリンクはコンシューマーオフセットを古いクラスターのミラートピックから同期しません。
- コンシューマーは 2 つの異なるトピックから消費しているので、順序付けのためにパーティションを使用することはできません。特定のキーを持つメッセージは、古いクラスターの 1 つのパーティションと、新しいクラスターの別のパーティションに生成されます。同じキーを持つ 2 つのメッセージは、別々のコンシューマーによって異なる順序で読み出される可能性があります。したがって、コンシューマーはタイムスタンプなど、メッセージの順序を決定する何か別のものを使用する必要があります。
Replicator を使用した双方向¶
Confluent Replicator は、Confluent Cloud コミットメント契約のお客様には無料ライセンスでご利用いただけます。これは、仮想マシンや Kubernetes クラスターで実行できるソフトウェアです。2 つの異なるクラスターのトピック間でメッセージを同期します。
双方向レプリケーションを実現するために、Replicator の 2 つのデプロイをセットアップできます。Replicator は循環ループが作成されないようにします。つまり、同じメッセージは、それが生成された元のクラスターに再度レプリケートされることはありません。
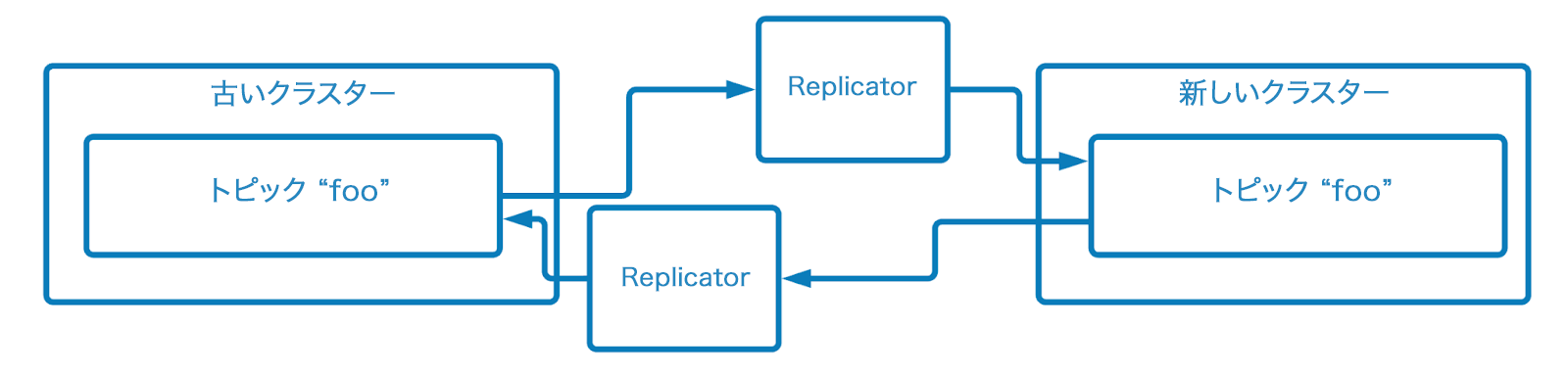
ただし、これらの 2 つのトピック間の順序は同じにはなりません。つまり、コンシューマーが `古い` クラスターから `新しい` クラスターに移動し、停止した同じスポットで再開することはできません。コンシューマーは次のいずれかを選択する必要があります。
- メッセージの欠落がないようにするために、以前のオフセットに巻き戻します。ただし、こうするとコンシューマーが一部のメッセージを二重に消費することになります。または、
- トピックの最後で消費を開始します。こうした場合、直近で生成されたメッセージが欠落することになります。