重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
水平スケーリング¶
以降のセクションでは、水平スケーリングについて説明します。
タスクの例¶
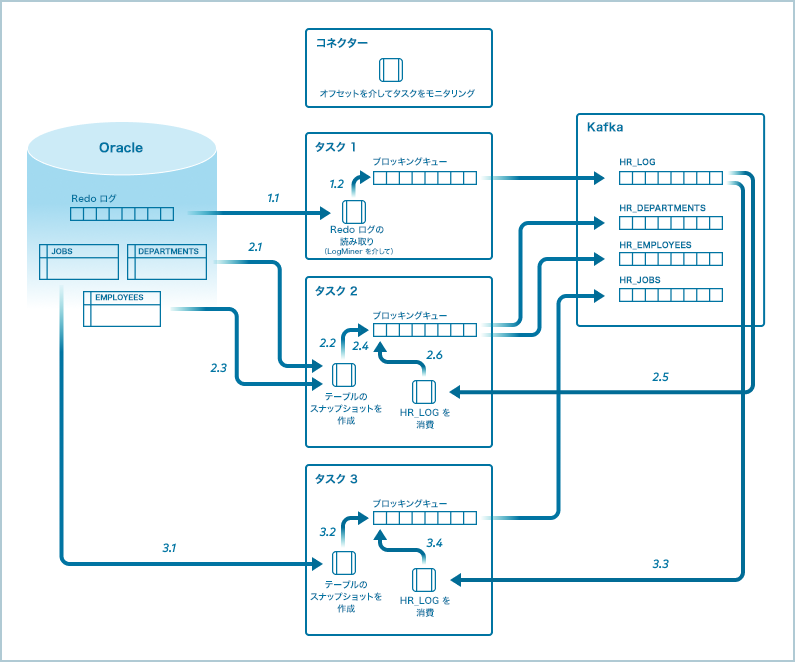
Oracle CDC Source Connector は、既存の Kafka Connect フレームワークを使用して水平スケーリングを行います。以下の図では、3 つのタスクを持つコネクターが構成されています。
- タスク 1: Oracle Database Redo ログからレコードを読み取り、それらのレコードを Apache Kafka® の redo ログトピックに書き込みます。
- タスク 2: DEPARTMENTS テーブルと EMPLOYEES テーブルのスナップショットを作成します。
- タスク 3: JOBS テーブルのスナップショットを作成します。
スナップショット作成によってタスク 2 とタスク 3 が完了したら、Oracle Database の Redo ログトピックではなく、Kafka の Redo ログトピックからレコードを読み取ります。それ以後、3 つのタスクにより、スナップショットからのテーブル固有のトピックが Kafka に自動入力されます。
ちなみに
多数のテーブルのスナップショットを作成する必要がある場合は、さらに多くのタスクを追加して、スナップショットのパフォーマンスを高めることができます。
水平スケーリング例¶
テーブルパーティションスナップショット¶
コネクターは Oracle でパーティション化された大きなテーブルのスナップショットを並列に実行し、これらのテーブルパーティションスナップショットをすべてのタスクに配信します。これを実行するには、コネクターのプロパティ start.from=snapshot と snapshot.by.table.partitions を使用します。
たとえば、コネクターに start.from=snapshot が構成されている場合、プロパティ snapshot.by.table.partitions=true を設定して、1 つのテーブルに 2 つ以上のタスクを割り当てることができます(テーブルがパーティション化されている場合)。これによりタスク数がリニアにスケーリングされるため、より多くのスナップショットがより多くのタスクで並列に実行されます。たとえば、コネクターは、多数のテーブルパーティション(たとえば、P=20)を含む 1 つの大きなテーブル(N=1)を、最大 P+1 個のタスクを使用して取り込み、スナップショットを作成できます。これにより、タスク数を増やすことで、スナップショットの実行に必要な全体の時間が短縮されます。
snapshot.by.table.partitions=true でコネクターを実行する場合は、事前にテーブル固有のトピックを作成します。テーブル固有のトピックを事前に作成しないと、パーティション化されたテーブルに割り当てられた一部のタスクが失敗します。