重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Elasticsearch Service Sink Connector for Confluent Cloud¶
注釈
Confluent Platform 用にコネクターをローカルにインストールする場合は、「Elasticsearch Service Sink Connector for Confluent Platform」を参照してください。
Kafka Connect Elasticsearch Service Sink Connector for Confluent Cloud を使用すると、Apache Kafka® のデータを Elasticsearch に移動できます。このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)フォーマットの Apache Kafka® トピックのデータの出力をサポートします。このコネクターは、Kafka のトピックのデータを、Elasticsearch のインデックス に書き込みます。Elasticsearch は、テキストクエリや分析によく使用されます。キー値ストアとしても使用されます。
このコネクターは、分析とキー値ストアの両方のユースケースに対応しています。分析 ユースケースでは、Kafka の各メッセージはイベントとして処理されます。コネクターでは、イベントの一意の識別子として topic+partition+offset が使用され、イベントは Elasticsearch の一意のドキュメントに変換されます。
キー値ストア ユースケースでは、コネクターで Kafka メッセージのキーを Elasticsearch のドキュメント ID として使用でき、また、キーへのアップデートを Elasticsearch に順番に書き込む構成が用意されています。どちらのユースケースでも、Elasticsearch の冪等性のある書き込みセマンティクスにより、「厳密に 1 回」のデリバリーが確実に実行されます。
Elasticsearch では、トピックのすべてのデータは型が同じです。これにより、さまざまなトピックのデータに対して個別のスキーマ進化を使用できます。Elasticsearch ではマッピングに対する強制が 1 つであるため、スキーマ進化は簡素化されます。つまり、同じインデックス内の同じ名前を持つすべてのフィールドは、マッピングの型 が同じである必要があります。
機能¶
Elasticsearch Service Sink Connector は、Kafka レコードを Elasticsearch のインデックスに挿入します(挿入のみがサポートされます)。
注釈
- このコネクターは、Elastic Cloud の Elasticsearch Service にのみ使用できます。
- このコネクターは、Elasticsearch バージョン 7.1 以降との接続をサポートしています。ただし、Elasticsearch バージョン 8.x はサポートしていません。
このコネクターには、以下の機能があります。
- データベースの認証: ユーザー名とパスワードによる認証を使用します。
- 入力データフォーマット: このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)の入力データフォーマットをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- 厳選された構成プロパティ: コネクターの動作とパフォーマンスを微調整できるように、オプションの構成プロパティがいくつか用意されています。これらのプロパティについて、以下で説明します。
key.ignore: Elasticsearch ドキュメント ID を生成するためにレコードキーを無視するかどうかを指定します。これをtrueに設定した場合、ドキュメント ID は、トピック名、パーティション、オフセット(topic+partition+offset)から作成されます。schema.ignore: インデックスの作成時にスキーマを無視するかどうかを指定します。このプロパティをtrueに設定すると、レコードスキーマは無視され、Elasticsearch はデータからマッピングを推測します。このためには、Elasticsearch の 動的マッピング を有効にしておく必要があります。JSON(スキーマレス)では、このプロパティを false(デフォルト)の設定のままにする必要があることに注意してください。compact.map.entries: レコード値に文字列キーが含まれるマップエントリを JSON に書き込む方法を定義します。このプロパティをtrueに設定すると、これらのエントリは`"entryKey": "entryValue"としてコンパクトに書き込まれます。それ以外の場合、文字列キーを含むマップエントリは、ネストされたドキュメント({"key": "entryKey", "value": "entryValue"})として書き込まれます。behavior.on.null.values: null 以外のキーと null 値を含むレコード(Kafka tombstone レコード)を処理する方法。有効なオプションは、ignore、delete、failです。デフォルトはignoreです。drop.invalid.message: Kafka メッセージを出力メッセージに変換できない場合にドロップするかどうかを指定します。デフォルトはfalseです。batch.size: Elasticsearch に書き込む際にバッチとして処理するレコードの数。この値のデフォルトは2000です。linger.ms: バッチ処理のための待機時間(ミリ秒)。リクエストの送信から次の送信までに到着したレコードは、batch.size構成に基づいて 1 つの一括インデックス作成リクエストにまとめられます。通常、これは、負荷がかかった状況、つまり、レコードを送信できるよりも速くレコードが到着している場合にのみ行われます。ただし、一括インデックス作成の利点を活用するために、負荷が軽い状況でもリクエストの数を減らすことができます。つまり、待機中のバッチが満杯でなければ、リクエストをすぐに送信するのではなく、指定された時間までタスクが待機します。これによって、他のレコードを追加して 1 回のリクエストでまとめて処理することができます。この値のデフォルトは1000ミリ秒(1 秒)です。flush.timeout.ms: 定期的なフラッシュを行う場合に使用するタイムアウト(単位: ミリ秒)、およびレコードの追加時に完了済みのリクエストによってバッファスペースが利用可能になるのを待機する場合に使用するタイムアウト(単位: ミリ秒)。このタイムアウトを経過すると、タスクは失敗します。この値のデフォルトは10000ミリ秒です。connection.compression: ElasticSearch への HTTP 接続で Gzip 圧縮を使用するかどうかを指定します。この設定を有効にするには、Elasticsearch ノードでhttp.compression設定をtrueに設定する必要があります。Elasticsearch の HTTP プロパティについて詳しくは、『Elasticsearch HTTP Settings』を参照してください。デフォルトはfalseです。auto.create.indices.at.start: 起動時に Elasticsearch のインデックスを自動的に作成します。これは、インデックスが Kafka トピックから直接マップされるときに役立ちます。デフォルトはtrueです。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、Elasticsearch Service Sink Connector の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
クイックスタート¶
このクイックスタートを使用して、Confluent Cloud Elasticsearch Service Sink Connector の利用を開始することができます。このクイックスタートでは、コネクターを選択し、Elasticsearch デプロイにイベントをストリームするようにコネクターを構成するための基本的な方法について説明します。
注釈
このコネクターは、Elastic Cloud の Elasticsearch Service にのみ使用できます。
- 前提条件
アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへのアクセスを許可されていること。
Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
ネットワークに関する考慮事項については、「Networking and DNS Considerations」を参照してください。静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。
Elasticsearch Service のデプロイは、Confluent Cloud のデプロイと同じリージョンに存在している必要があります。
Elasticsearch Service の有効なユーザー名とパスワードをコネクター構成に追加します。これらは、Elastic のデプロイを作成するときに確認できます。以下に例を示します。
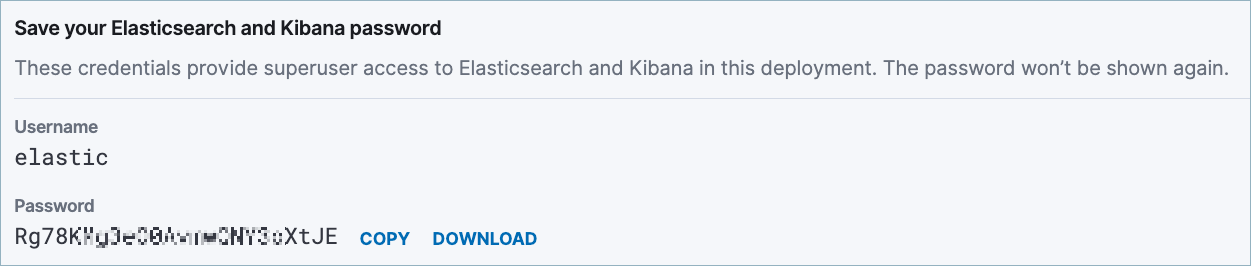
- Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: コネクターの詳細情報を入力します。¶
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク( * )は必須項目であることを示しています。
At the Add Elasticsearch Service Sink Connector screen, complete the following:
既に Kafka トピックを用意している場合は、Topics リストから接続するトピックを選択します。
新しいトピックを作成するには、+Add new topic をクリックします。
- Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。以下のいずれかのオプションを選択できます。
- Global Access: コネクターは、ユーザーがアクセス権限を持つすべての対象にアクセスできます。グローバルアクセスの場合、コネクターのアクセス権限は、ユーザーのアカウントにリンクされます。このオプションは本稼働環境では推奨されません。
- Granular access: コネクターのアクセスが制限されます。コネクターのアクセス権限は サービスアカウント から制御できます。本稼働環境にはこのオプションをお勧めします。
- Use an existing API key: 保存済みの API キーおよびシークレット部分を入力できます。API キーとシークレットを入力するか Cloud Console でこれらを生成することもできます。
- Continue をクリックします。
- Elasticsearch 接続の詳細情報を入力します。
- Connection URI: Elasticsearch Service の接続 URI。
- Connection user: Elasticsearch Service での認証に使用するユーザー名。
- Connection password: Elasticsearch Service での認証に使用するパスワード。
- Enable SSL Security: Sets authentication support. Set this to SSL if you want to enable PKI authentication with SSL support. If not set to SSL, the connector ignores all SSL configuration properties. Note that the connector will use SSL if HTTPS is used.
- Continue をクリックします。
注釈
Cloud Console に表示されない構成プロパティでは、デフォルト値が使用されます。すべてのプロパティの値と定義については、「 構成プロパティ」を参照してください。
Input Kafka record value で、Kafka 入力レコード値(Kafka トピックから送られるデータ)を AVRO、JSON_SR(JSON スキーマ)、PROTOBUF、または JSON(スキーマレス)から選択します。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
Show advanced configurations
Key ignore: Whether to ignore the record key for the purpose of forming the Elasticsearch document ID. When this is set to
true, document IDs are created from the topic name, partition, and offset (for example,topic+partition+offset).Topics for 'Ignore Key' mode: A list of topics where the key is ignored when forming the Elasticsearch document ID. Used when Key ignore is set to
true. If no topics are listed in this property, the connector ignores keys when processing all records.Schema ignore: Whether to ignore schemas during indexing. When this property is set to
true, the record schema is ignored and Elasticsearch infers the mapping from the data. For this to work, Elasticsearch dynamic mapping must be enabled. Note that this property must stay set to false (default) for JSON (schemaless).Topics for 'Ignore Schema' mode: A list of topics where the record schema is ignored. Used when Schema ignore is set to
true. If no topics are listed in this property, the connector ignores the schema when processing all records.Compact map entries: Defines how map entries with string keys in record values should be written to JSON. When this property is set to
true, the entries are written compactly as`"entryKey": "entryValue". Otherwise, map entries with string keys are written as a nested document ({"key": "entryKey", "value": "entryValue"}).Write Method: The method the connector uses to write data to Elasticsearch. Options are
INSERTorUPSERT. WhenINSERT(the default) is used, the connector constructs a document from the record value and inserts the document into Elasticsearch, completely replacing any existing document with the same ID. WhenUPSERTis used, the connector creates a new document if one with the specified ID does not exist. If the document exists, the connector updates the document with the same ID by adding or replacing only those fields present in the record value. TheUPSERTmethod may require additional Elasticsearch time and resources, so consider increasing the Read Timeout and decreasing the Batch size configuration properties.Behavior on null values: null 以外のキーと null 値を含むレコード(Kafka tombstone レコードなど)を処理する方法。オプションは、delete、fail、ignore (デフォルト)です。
Behavior on malformed documents: インデックスマッピングの競合、無効な文字を含むフィールド名、ID がないレコードなど、ドキュメント自体の形式に誤りがあるために Elasticsearch によって拒否されたレコードの処理方法。
ignoreの場合、不正なレコードがスキップされます。failの場合、コネクターがエラーになります。Drop invalid message: Kafka メッセージを出力メッセージに変換できない場合にドロップするかどうかを指定します。デフォルトは false です。
Batch size:: Elasticsearch に書き込む際にバッチとして処理するレコードの数。この値のデフォルトは 2000 です。
Linger (ms): バッチ処理のための待機時間(ミリ秒)。リクエストの送信から次の送信までに到着したレコードは、Batch size 値に基づいて 1 つの一括インデックス作成リクエストにまとめられます。通常、これは、負荷がかかった状況、つまり、レコードを送信できるよりも速くレコードが到着している場合にのみ行われます。ただし、一括インデックス作成の利点を活用するために、負荷が軽い状況でもリクエストの数を減らすことができます。つまり、待機中のバッチが満杯でなければ、リクエストをすぐに送信するのではなく、指定された時間までタスクが待機します。これによって、他のレコードを追加して 1 回のリクエストでバッチ処理できます。この値のデフォルトは 1000 ミリ秒(1 秒)です。
Flush timeout (ms): 定期的なフラッシュを行う場合に使用するタイムアウト(ミリ秒)、およびレコードの追加時に完了済みのリクエストによってバッファスペースが利用可能になるのを待機する場合に使用するタイムアウト(ミリ秒)。このタイムアウトを経過すると、タスクは失敗します。この値のデフォルトは 10000 ミリ秒です。
Flush synchronously?: Sets whether or not flushes wait for background processing to finish. Defaults to
true. This has a throughput penalty and makes the connector less responsive, but allows the use of topic-mutating SMTs (for example, RegexRouter or TimestampRouter).Connection.compression: ElasticSearch への HTTP 接続で Gzip 圧縮を使用するかどうかを指定します。この設定を有効にするには、Elasticsearch ノードで
http.compression設定をtrueに設定する必要があります。Elasticsearch の HTTP プロパティについて詳しくは、Elasticsearch の「HTTP」 を参照してください。Read Timeout: How long to wait in milliseconds (ms) for the Elasticsearch server to send a response. The task fails if any read operation times out. Defaults to
15000ms (15 seconds).Data Stream Type: データストリームに書き込まれるデータを表す汎用的な型です。デフォルトは
NONEです。Data Stream Dataset: データストリームへ書き込むときに取り込まれるデータとその構造を表す一般名です。
Data Stream Timestamp Field: All documents sent to a data stream need a
timestampfield with values of typedateordata_nanos. Otherwise, the document won't be sent.
変換と述語については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
Continue をクリックします。
選択するトピックのパーティション数に基づいて、推奨タスク数が表示されます。
- 推奨されたタスク数を変更するには、Tasks フィールドに、コネクターで使用する タスク の数を入力します。
- Continue をクリックします。
接続の詳細情報を確認します。
Launch をクリックします。
コネクターのステータスが Provisioning から Running に変わります。

ステップ 5: Elasticsearch で結果を確認します。¶
新しいレコードが Elasticsearch デプロイにシンクされていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI を使用する場合¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe ElasticsearchSink
出力例:
Following are the required configs:
connector.class: ElasticsearchSink
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
topics
input.data.format
connection.url
connection.username
connection.password
type.name
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
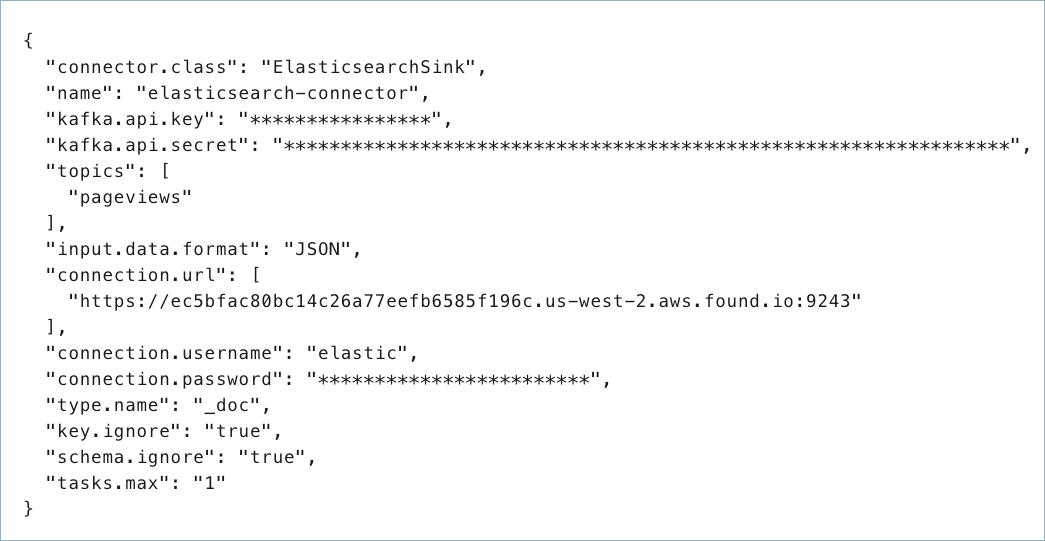
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティとオプションのプロパティを示しています。
{
"connector.class": "ElasticsearchSink",
"name": "elasticsearch-connector",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key",
"kafka.api.secret": "<my-kafka-api-secret",
"topics": "<topic1>, <topic2>"
"input.data.format": "JSON",
"connection.url": "<elasticsearch-URI>",
"connection.user": "<elasticsearch-username>",
"connection.password": "<elasticsearch-password>",
"type.name": "<type-name>",
"key.ignore": "true",
"schema.ignore": "true",
"tasks.max": "1"
}
以下のプロパティ定義に注意してください。
"connector.class": コネクターのプラグイン名を指定します。"name": 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"input.data.format": Kafka 入力レコード値のフォーマット(Kafka トピックから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(たとえば、Avro、JSON_SR(JSON スキーマ)、および Protobuf)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。"connection.url": 接続 URI を入力します。これは、Elasticsearch デプロイコンソールからコピーできる Elasticsearch エンドポイントです。入力する URI は、https://ec5bfac80bc14c26a77eefb6585f196c.us-west-2.aws.found.io:9243のようになります。"connection.user"および"connection.password": Elasticsearch デプロイのユーザー名とパスワードを入力します。Elastic デプロイコンソールにこのユーザー名とパスワードが表示されている例が、「前提条件」に示されています。"type.name": これは、インデックスを作成し、ドキュメントを論理グループに分けるときに Elasticsearch で使用される名前です。これには、任意の名前を選択できます(たとえば、customerやitemなど)。このプロパティおよび一般的なマッピングについて詳しくは、『Elasticsearch Mapping: The Basics, Updates & Examples』を参照してください。
構成に含めることができるオプションプロパティを以下に示します。
key.ignore: Elasticsearch ドキュメント ID を生成するためにレコードキーを無視するかどうかを指定します。これをtrueに設定した場合、ドキュメント ID は、トピック名、パーティション、オフセット(topic+partition+offset)から作成されます。使用しない場合は、falseがデフォルトです。schema.ignore: インデックスの作成時にスキーマを無視するかどうかを指定します。このプロパティをtrueに設定すると、レコードスキーマは無視され、Elasticsearch はデータからマッピングを推測します。このためには、Elasticsearch の 動的マッピング を有効にしておく必要があります。JSON では、このプロパティを false(デフォルト)の設定のままにする必要があることに注意してください。使用しない場合は、falseがデフォルトです。compact.map.entries: レコード値に文字列キーが含まれるマップエントリを JSON に書き込む方法を定義します。このプロパティをtrueに設定すると、これらのエントリは`"entryKey": "entryValue"としてコンパクトに書き込まれます。それ以外の場合、文字列キーを含むマップエントリは、ネストされたドキュメント({"key": "entryKey", "value": "entryValue"})として書き込まれます。使用しない場合は、falseがデフォルトです。behavior.on.null.values: null 以外のキーと null 値を含むレコード(Kafka tombstone レコード)を処理する方法。有効なオプションは、ignore、delete、failです。使用しない場合は、ignoreがデフォルトです。drop.invalid.message: Kafka メッセージを出力メッセージに変換できない場合にドロップするかどうかを指定します。使用しない場合は、falseがデフォルトです。batch.size: Elasticsearch に書き込む際にバッチとして処理するレコードの数。使用しない場合は、この値のデフォルトは2000です。linger.ms: バッチ処理のための待機時間(ミリ秒)。リクエストの送信から次の送信までに到着したレコードは、batch.size構成に基づいて 1 つの一括インデックス作成リクエストにまとめられます。通常、これは、負荷がかかった状況、つまり、レコードを送信できるよりも速くレコードが到着している場合にのみ行われます。ただし、一括インデックス作成の利点を活用するために、負荷が軽い状況でもリクエストの数を減らすことができます。つまり、待機中のバッチが満杯でなければ、リクエストをすぐに送信するのではなく、指定された時間までタスクが待機します。これによって、他のレコードを追加して 1 回のリクエストでまとめて処理することができます。使用しない場合は、この値のデフォルトは1000ミリ秒(1 秒)です。flush.timeout.ms: 定期的なフラッシュを行う場合に使用するタイムアウト(単位: ミリ秒)、およびレコードの追加時に完了済みのリクエストによってバッファスペースが利用可能になるのを待機する場合に使用するタイムアウト(単位: ミリ秒)。このタイムアウトを経過すると、タスクは失敗します。この値のデフォルトは10000ミリ秒です。connection.compression: ElasticSearch への HTTP 接続で Gzip 圧縮を使用するかどうかを指定します。この設定を有効にするには、Elasticsearch ノードでhttp.compression設定をtrueに設定する必要があります。Elasticsearch の HTTP プロパティについて詳しくは、『Elasticsearch HTTP Settings』を参照してください。使用しない場合は、falseがデフォルトです。auto.create.indices.at.start: 起動時に Elasticsearch のインデックスを自動的に作成します。これは、インデックスが Kafka トピックから直接マップされるときに役立ちます。使用しない場合は、trueがデフォルトです。
Single Message Transforms: CLI を使用した SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。このコネクターでサポートされていない SMT のリストについては、「サポートされない変換」を参照してください。
すべてのプロパティの値と定義については、「構成プロパティ」を参照してください。
ステップ 4: 構成ファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config elasticsearch-sink-config.json
出力例:
Created connector elasticsearch-connector lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+----------------------------+---------+------+
lcc-ix4dl | elasticsearch-connector | RUNNING | sink
ステップ 6: Elasticsearch で結果を確認します。¶
新しいレコードが Elasticsearch デプロイに追加されていることを確認します。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
ちなみに
コネクターを起動すると、デッドレターキューのトピックが自動的に生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データの取得元とするトピック(Which topics do you want to get data from?)¶
topics特定のトピック名を指定するか、複数のトピック名をコンマ区切りにしたリストを指定します。
- 型: list
- 重要度: 高
入力メッセージ(Input messages)¶
input.data.formatKafka 入力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
Elasticsearch Service への接続方法(How should we connect to your Elasticsearch Service?)¶
connection.urlElasticsearch Service の接続 URI(例: https://123123.us-east-1.aws.found.io:9243)。
- 型: list
- 重要度: 高
connection.usernameElasticsearch Service での認証に使用されるユーザー名。
- 型: string
- 重要度: 高
connection.passwordElasticsearch Service での認証に使用されるパスワード。
- 型: password
- 重要度: 高
Security¶
elastic.security.protocolThis should be set to SSL if you want to enable PKI auth with SSL support. Otherwise all ssl configs are ignored. Note that the connector will still use SSL if https is used.
- 型: string
- Default: PLAINTEXT
- 重要度: 中
elastic.https.ssl.keystore.fileThe key store file. This is optional for client and can be used for two-way authentication for client.
- 型: password
- 重要度: 中
elastic.https.ssl.key.passwordThe password of the private key in the key store file. This is required for clients only if two-way authentication is configured.
- 型: password
- 重要度: 中
elastic.https.ssl.keystore.passwordThe store password for the key store file. This is optional for client and only needed if 'ssl.keystore.location' is configured. Key store password is not supported for PEM format.
- 型: password
- 重要度: 中
elastic.https.ssl.keystore.typeThe file format of the key store file. This is optional for client.
- 型: string
- Default: JKS
- 重要度: 中
elastic.https.ssl.truststore.fileThe Truststore file with the certificates of the trusted CAs.
- 型: password
- 重要度: 中
elastic.https.ssl.truststore.passwordThe password for the trust store file. If a password is not set, trust store file configured will still be used, but integrity checking is disabled. Trust store password is not supported for PEM format.
- 型: password
- 重要度: 中
elastic.https.ssl.truststore.typeThe file format of the trust store file.
- 型: string
- Default: JKS
- 重要度: 中
elastic.https.ssl.keymanager.algorithmThe algorithm used by key manager factory for SSL connections.
- 型: string
- Default: SunX509
- 重要度: 低
elastic.https.ssl.trustmanager.algorithmThe algorithm used by trust manager factory for SSL connections.
- 型: string
- Default: PKIX
- 重要度: 低
elastic.https.ssl.endpoint.identification.algorithmThe endpoint identification algorithm to validate server hostname using server certificate.
- 型: string
- Default: https
- 重要度: 低
データ変換(Data Conversion)¶
key.ignoreElasticsearch ドキュメント ID を生成するためにレコードキーを無視するかどうかを指定します。これを true に設定した場合、ドキュメント ID はレコードから取得されたトピック+パーティション+オフセットとして生成されます。これを false に設定した場合、レコードキーが Elasticsearch のドキュメント ID として使用されます。
- 型: boolean
- デフォルト: false
- 重要度: 低
topic.key.ignoreList of topics for which
key.ignoreshould betrue.- 型: list
- 重要度: 低
schema.ignoreインデックスの作成中にスキーマを無視するかどうかを指定します。これを true に設定すると、レコードスキーマは、Elasticsearch マッピングを登録する目的では無視されます。Elasticsearch では、データからマッピングが推測されます(動的マッピングはユーザーが有効にする必要があります)。
- 型: boolean
- デフォルト: false
- 重要度: 低
topic.schema.ignoreList of topics for which
schema.ignoreshould betrue.- 型: list
- 重要度: 低
compact.map.entriesレコード値内の文字列キーを含むマップエントリを JSON に書き込む方法を定義します。これを true に設定すると、これらのエントリは "entryKey": "entryValue" としてコンパクトに書き込まれます。それ以外の場合、文字列キーを含むマップエントリは、ネストされたドキュメント {"key": "entryKey", "value": "entryValue"} として書き込まれます。
- 型: boolean
- デフォルト: true
- 重要度: 低
write.methodMethod used for writing data to Elasticsearch, and one of INSERT or UPSERT. The default method is INSERT, in which the connector constructs a document from the record value and inserts that document into Elasticsearch, completely replacing any existing document with the same ID; this matches previous behavior. The UPSERT method will create a new document if one with the specified ID does not yet exist, or will update an existing document with the same ID by adding/replacing only those fields present in the record value. The UPSERT method may require additional time and resources of Elasticsearch, so consider increasing the read.timeout.ms and decreasing the batch.size configuration properties.
- 型: string
- Default: INSERT
- 重要度: 低
エラー処理¶
behavior.on.null.valuesnull 以外のキーと null 値を含むレコード(Kafka tombstone レコードなど)を処理する方法。指定可能なオプションは、ignore、delete、fail です。ignore の場合、レコードがスキップされます。delete の場合、レコードが削除されます。fail の場合、コネクターがエラーになります。
- 型: string
- デフォルト: ignore
- 重要度: 低
behavior.on.malformed.documentsインデックスマッピングの競合、無効な文字を含むフィールド名、ID がないレコードなど、ドキュメント自体の形式に誤りがあるために Elasticsearch によって拒否されたレコードの処理方法。「ignore」の場合、不正なレコードがスキップされます。「fail」の場合、コネクターがエラーになります。
- 型: string
- デフォルト: fail
- 重要度: 低
drop.invalid.messageElasticsearch のドキュメントに変換できない場合にレコードをドロップするかどうかを指定します。
- 型: boolean
- デフォルト: false
- 重要度: 低
接続の詳細(Connection Details)¶
batch.sizeElasticsearch に書き込む際にバッチとして処理するレコードの数。
- 型: int
- デフォルト: 2000
- 指定可能な値: [1、…]
- 重要度: 中
linger.msバッチ処理のための待機時間(単位: ミリ秒)。リクエストの送信から次の送信までに到着したレコードは、batch.size 構成に基づいて 1 つの一括インデックス作成リクエストにまとめられます。通常、この処理が行われるのは、レコードは到着したがまだ送信可能な状態になっていないという、負荷がかかった状況においてのみです。しかし、負荷が軽い状況でもリクエストの数を減らすことが望ましく、一括インデックス作成が効果的な場合があります。この設定を使用すれば、そのような状況に対応できます。待機中のバッチがいっぱいでない場合、タスクはリクエストをすぐに送信するのではなく、指定された時間まで待機し、他のレコードを追加して 1 つのリクエストにまとめられるようにします。
- 型: int
- デフォルト: 1000(1 秒)
- 指定可能な値: [1000、…]
- 重要度: 低
flush.timeout.ms定期的なフラッシュに使用するタイムアウト(単位: ミリ秒)。レコードの追加時に完了済みリクエストがバッファースペースを利用可能にするまで待機する際のタイムアウトでもあります。このタイムアウトを超えると、タスクは失敗します。
- 型: int
- デフォルト: 10000(10 秒)
- 指定可能な値: [1000、…]
- 重要度: 低
flush.synchronouslyTrue if flushes should wait for background processing to finish. This has a throughput penalty and makes the connector less responsive but allows for topic-mutating SMTs (e.g. RegexRouter or TimestampRouter)
- 型: boolean
- デフォルト: true
- 重要度: 低
connection.compressionElasticSearch への HTTP 接続で GZip 圧縮を使用するかどうかを指定します。この設定を有効にするには、使用前に Elasticsearch ノードで http.compression 設定も有効にする必要があります。
- 型: boolean
- デフォルト: false
- 重要度: 低
read.timeout.msHow long to wait in milliseconds for the Elasticsearch server to send a response. The task fails if any read operation times out.
- 型: int
- Default: 15000 (15 seconds)
- Valid Values: [1000,...,60000]
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1、…]
- 重要度: 高
データストリーム(Data Streams)¶
data.stream.typeデータストリームに書き込まれるデータを表す汎用的な型です。デフォルトは NONE で、コネクターは代わりに通常のインデックスに書き込みます。このプロパティを設定すると、その構成が data.stream.dataset とともに使用され、{
`data.stream.type}-{data.stream.dataset}-{topic} の形式でデータストリーム名が形成されます。- 型: string
- デフォルト: none
- 重要度: 低
data.stream.datasetデータストリームへ書き込むときに取り込まれるデータとその構造を表す一般名です。任意の文字列を 100 文字以内で指定できます。すべて小文字とし、スペースや特殊文字(
/\*"<>|,#:-)を含めることはできません。これに従わない場合、値なしとして扱われ、コネクターは代わりに通常のインデックスに書き込みます。このプロパティを設定すると、その構成がdata.stream.typeとともに使用され、{data.stream.type}-{data.stream.dataset}-{topic} の形式でデータストリーム名が形成されます。- 型: string
- デフォルト: ""
- 重要度: 低
data.stream.timestamp.fieldデータストリームに送信されるすべてのドキュメントには、
date型またはdata_nanos型の値を持つ@timestampフィールドが必要です。このようなフィールドがない場合、ドキュメントは送信されません。複数のフィールドが指定されている場合は、レコードにも表示されている最初のフィールドが使用されます。この構成を空のままにすると、すべてのドキュメントでは、Kafka レコードのタイムスタンプが@timestampフィールドの値として使用されます。レコードに既に@timestampフィールドが含まれている場合でも、このフィールドを明示的に指定する必要があることに注意してください。この構成は、data.stream.typeとdata.stream.datasetが指定されている場合にのみ設定できます。- 型: list
- デフォルト: ""
- 重要度: 低
おすすめの記事¶
以下のブログ記事には、Confluent Cloud Elasticsearch Service Sink Connector を使用したデータパイプラインの例が示されています。
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。