重要
このページの日本語コンテンツは古くなっている可能性があります。最新の英語版コンテンツをご覧になるには、こちらをクリックしてください。
Confluent Cloud の MySQL CDC ソース(Debezium)コネクター¶
注釈
- MariaDB は現在サポートされていません。詳細については、Debezium のドキュメント を参照してください。
- Confluent Platform 用にコネクターをローカルにインストールする場合は、「Debezium MySQL Source Connector for Confluent Platform」を参照してください。
Confluent Cloud の Kafka Connect MySQL 変更データキャプチャー(CDC)ソース(Debezium)コネクターは、MySQL データベースの既存データのスナップショットを取得し、そのデータに対してそれ以降に発生する行レベルの変更をすべてモニタリングして記録することができます。このコネクターは、Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)の出力データフォーマットをサポートします。テーブルごとにすべてのイベントが個別の Apache Kafka® トピックに記録されます。そのため、アプリケーションやサービスでイベントを簡単に消費することができます。削除されたレコードはキャプチャーされないことに注意してください。
機能¶
MySQL CDC ソース(Debezium)コネクターには、以下の機能があります。
- トピックの自動作成: このコネクターは、命名規則
<database.server.name>.<schemaName>.<tableName>を使用して自動的に Kafka トピックを作成します。テーブルの作成にはtopic.creation.default.partitions=1プロパティおよびtopic.creation.default.replication.factor=3プロパティが使用されます。詳細については、「最大メッセージサイズ」を参照してください。 - 対象に含めるデータベース と 対象から除外するデータベース: データベースの変更をモニタリングするかどうかを設定します。デフォルトでは、コネクターはサーバー上のデータベースをすべてモニタリングします。
- 対象に含めるテーブル と 対象から除外するテーブル: テーブルの変更をモニタリングするかどうかを設定できます。
- 出力フォーマット: このコネクターでは、Kafka 出力レコード値フォーマット として Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)がサポートされます。また、出力レコードキーフォーマット として Avro、JSON スキーマ、Protobuf、JSON(スキーマレス)、String がサポートされます。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
- コネクターあたりのタスク数: 組織では複数のコネクターを実行できますが、コネクターあたり 1 つのタスク(
"tasks.max": "1")という制限があります。 - スナップショットモード: スナップショットを実行する条件を指定します。
- 削除時のトゥームストーン: delete イベントの後に tombstone イベントを生成するかどうかを設定します。デフォルトは
trueです。 - データベースの認証: パスワード認証を使用します。
- SSL のサポート: 一方向 SSL をサポートします。
- データフォーマット: Avro、JSON スキーマ、Protobuf、または JSON(スキーマレス)の出力データをサポートします。スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
注釈
database.server.id には、5400 から 6400 までの範囲の乱数が設定されます。
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
制限¶
以下の情報を確認してください。
- コネクターの制限事項については、MySQL CDC Source Connector (Debezium) の制限事項を参照してください。
- 1 つ以上の Single Message Transforms(SMT)を使用する場合は、「SMT の制限」を参照してください。
- Confluent Cloud Schema Registry を使用する場合は、「スキーマレジストリ Enabled Environments」を参照してください。
最大メッセージサイズ¶
このコネクターはトピックを自動的に作成します。トピックの作成時に、内部コネクター構成プロパティ max.message.size が次のように設定されます。
- ベーシッククラスター:
2 MB - スタンダードクラスター:
2 MB - 専用クラスター:
20 MB
Confluent Cloud クラスターの詳細については、「クラスタータイプごとの Confluent Cloud の機能と制限」を参照してください。
クイックスタート¶
このクイックスタートを使用して、MySQL CDC ソース(Debezium)コネクターの利用を開始することができます。このクイックスタートでは、コネクターを選択してから、MySQL データベースの既存データのスナップショットを取得して、それ以降に発生する行レベルの変更をすべてモニタリングして記録するようにコネクターを構成するための基本的な方法について説明します。
- 前提条件
アマゾンウェブサービス (AWS)、Microsoft Azure (Azure)、または Google Cloud Platform (GCP)上の Confluent Cloud クラスターへのアクセスを許可されていること。
Confluent CLI がインストールされ、クラスター用に構成されていること。「Confluent CLI のインストール」を参照してください。
スキーマレジストリ ベースのフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Schema Registry を有効にしておく必要があります。詳細については、「スキーマレジストリ Enabled Environments」を参照してください。
データベースにパブリックアクセスが必要になる場合があります。詳細については、「ネットワークアクセス」を参照してください。以下の例は、MySQL データベースをセットアップするときの AWS 管理コンソールを示しています。
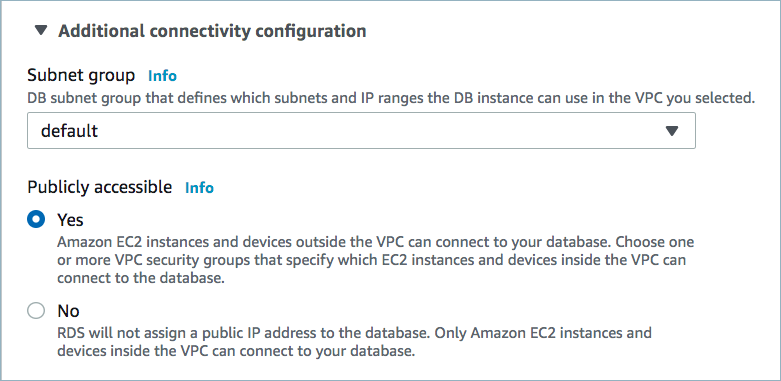
パブリックアクセスを有効にする¶
ネットワークに関する考慮事項については、「Networking and DNS Considerations」を参照してください。静的なエグレス IP を使用する方法については、「静的なエグレス IP アドレス」を参照してください。以下の例は、VPC にセキュリティグループルールをセットアップするときの AWS 管理コンソールを示しています。

インバウンドトラフィックを開く¶
注釈
VPC にセキュリティルールを構成する方法については、ご使用のクラウドプラットフォームのドキュメントを参照してください。
Kafka クラスターの認証情報。次のいずれかの方法で認証情報を指定できます。
- 既存の サービスアカウント のリソース ID を入力する。
- コネクター用の Confluent Cloud サービスアカウント を作成します。「サービスアカウント」のドキュメントで、必要な ACL エントリを確認してください。一部のコネクターには固有の ACL 要件があります。
- Confluent Cloud の API キーとシークレットを作成する。キーとシークレットを作成するには、confluent api-key create を使用するか、コネクターのセットアップ時に Cloud Console で直接 API キーとシークレットを自動生成します。
MySQL データベースで以下の設定をアップデートします。
データベースのバックアップを有効にします。
新しいパラメーターグループを作成し、以下のパラメーターを設定します。
binlog_format=ROW binlog_row_image=full
新しいパラメーターグループをデータベースに適用します。
データベースを再起動します。
以下の例の画面は Amazon RDS のものです。



Confluent Cloud Console の使用¶
ステップ 1: Confluent Cloud クラスターを起動します。¶
インストール手順については、「Quick Start for Confluent Cloud」を参照してください。
ステップ 2: コネクターを追加します。¶
左のナビゲーションメニューの Data integration をクリックし、Connectors をクリックします。クラスター内に既にコネクターがある場合は、+ Add connector をクリックします。
ステップ 4: 接続をセットアップします。¶
以下を実行して、Continue をクリックします。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- アスタリスク( * )は必須項目であることを示しています。
コネクターの 名前 を入力します。
Kafka Cluster credentials で Kafka クラスターの認証情報の指定方法を選択します。サービスアカウントのリソース ID を選択するか、API キーとシークレットを入力できます(または、Cloud Console でこれらを生成します)。
データベース接続の詳細情報を追加します。
重要
接続の hostname プロパティには
jdbc:xxxx://を含めないでください。以下にホストアドレスの例を示します。
デフォルトの SSL mode は
preferredです。preferredが有効になっている場合、コネクターは、データベースサーバーに対して暗号化された接続の使用を試みます。オプションpreferredおよびrequiredでは、セキュアな(暗号化された)接続が使用されます。セキュアな接続を確立できない場合、コネクターは失敗します。これらのモードでは、認証機関(CA)検証は行われません。Database details に情報を追加します(省略可)。
- Databases included: このコネクターでモニタリングするデータベースの完全修飾識別子をコンマ区切りにしたリストを入力します。デフォルトでは、コネクターはサーバー上のデータベースを "すべて" モニタリングします。完全修飾データベース名のフォームは、
<database-name>です。ここで指定したデータベースを Databases excluded で使用することはできません。 - Databases excluded: このコネクターで "無視" するデータベースの完全修飾識別子をコンマ区切りにしたリストを入力します。デフォルトでは、コネクターはサーバー上のデータベースを "すべて" モニタリングします。完全修飾データベース名のフォームは、
<database-name>です。ここで指定したデータベースを Databases included で使用することはできません。 - Connection timezone: データベースの場所とサーバー接続の有効なタイムゾーン ID を入力します。詳細については、「ZoneID」を参照してください。
- Tables included: このコネクターでモニタリングするテーブルの完全修飾識別子をコンマ区切りにしたリストを入力します。デフォルトでは、コネクターはシステムテーブル以外のテーブルをすべてモニタリングします。完全修飾テーブル名のフォームは、
schemaName.tableNameです。ここで指定したテーブルを Tables excluded で使用することはできません。 - Propagate Source Types by Data Type: データベース固有の データ型 に一致する正規表現のコンマ区切りリストを入力します。このプロパティでは、出力された変更レコードの対応するフィールドスキーマに、データ型の元の型と元の長さが(パラメーターとして)追加されます。
- Tables excluded: このコネクターで無視するテーブルの完全修飾識別子をコンマ区切りにしたリストを入力します。完全修飾テーブル名のフォームは、
schemaName.tableNameです。ここで指定したテーブルを Tables included で使用することはできません。 - Snapshot mode: コネクターの起動時にデータベーススナップショットを実行する条件を指定します。
- デフォルトオプションは、
initialです。選択すると、コネクターは、キャプチャー対象テーブルの構造およびデータのスナップショットを取得します。これは、コネクターの起動時にキャプチャー対象テーブルの完全なデータ表現をトピックに取り込む必要がある場合に便利です。 never: コネクターでスナップショットを一切実行しないこと、また、コネクターを最初に起動するときには前回終了した位置から読み取りを開始することを指定します。schema_only: コネクターは、スキーマのスナップショットを完了します。データは含まれません。このオプションは、トピックにデータの整合スナップショットを含める必要はなくとも、コネクター起動後の変更のみ含める必要がある場合に便利です。schema_only_recovery: 既に変更をキャプチャーしているコネクターのリカバリオプション。コネクターは、破損または紛失したデータベース履歴トピックを再起動時にリカバリします。このオプションを定期的に使用して、想定外に大きくなっているデータベース履歴トピックをクリーンアップできます。データベース履歴トピックは、無限のデータ保持が要求されます。"when_needed"は、コネクターが、スナップショットを必要だと判断した場合にスナップショットを実行することを指定します。
- デフォルトオプションは、
- Snapshot locking mode: スナップショット実行時にグローバルな読み取りロックを保持する長さを制御できます。デフォルトは
minimalです。コネクターは、グローバルな読み取りロック(あらゆるアップデートを防止)をスナップショットの最初の部分についてのみ保持します。データベーススキーマとその他のメタデータは読み取り可能です。スナップショットの残りの処理には、各テーブルのすべての行の選択が含まれます。この処理は、読み取りロックがオフで他の操作によってデータベースが更新中であっても、REPEATABLE READトランザクションを使用して完了されます。(Percona サーバーの場合はminimal_perconaを使用します)。場合によっては、スナップショットが完了するまですべての書き込みをブロックすることが望ましいことがあります。このような場合は、このプロパティをextendedに設定します。オプションnoneでは、コネクターがスナップショット中にテーブルロックを実行するのを防止します。この設定はすべてのスナップショットモードで使用できますが、スナップショット実行中にスキーマが変更されない場合にのみ使用することをおすすめします。MyISAM エンジンで定義されたテーブルの場合は、MyISAM がテーブルロックを取得するので、このプロパティの設定に関係なくテーブルはロックされます。この動作は、InnoDB エンジンとは異なります。こちらは行レベルのロックを取得します。 - Tombstones on delete: delete イベントの後に tombstone イベントを生成するかどうかを構成します。デフォルトは
trueです。 - Columns Excluded: 変更イベントレコードの値から除外する列の完全修飾名に一致する正規表現のリスト(省略可能)。コンマ区切りで指定します。列の完全修飾名は、
databaseName.tableName.columnNameという形式になります。
- Databases included: このコネクターでモニタリングするデータベースの完全修飾識別子をコンマ区切りにしたリストを入力します。デフォルトでは、コネクターはサーバー上のデータベースを "すべて" モニタリングします。完全修飾データベース名のフォームは、
Connection details に情報を追加します(省略可)。
- Poll interval (ms): 各反復でコネクターが新しい変更イベントの出現を待機するミリ秒数を入力します。デフォルト値は
1000ミリ秒(1 秒)です。 - Max batch size: 各反復でコネクターがバッチで処理するイベントの最大数を入力します。デフォルト値は
1000件です。 - Event processing failure handling mode: binlog イベントを処理する際の例外へのコネクターによる対応方法を指定します。デフォルト値は
failです。イベントをスキップする場合や警告を発行する場合は、それぞれskipまたはwarnを選択します。 - Heartbeat interval (ms): コネクターが Kafka トピックに送信するハートビートメッセージの間隔をミリ秒単位で設定します。デフォルト値は
0で、コネクターがハートビートメッセージを送信しないことを示します。 - Skip unparseable DDL: これを
trueに設定すると、正しくない形式または不明なデータベースステートメントが無視されます。これらの問題を修正できるように処理を停止するには、falseに設定します。デフォルトはfalseです。解析不能なステートメントを無視するには、これをtrueに設定することを検討してください。 - Event deserialization failure handling mode: binlog イベントを逆シリアル化する際の例外へのコネクターによる対応方法を指定します。デフォルト値は
failです。イベントをスキップする場合や警告を発行する場合は、それぞれskipまたはwarnを選択します。 - Inconsistent schema handling mode: 内部スキーマ表現に含まれていないテーブルに属する binlog イベントへの、コネクターによる対応方法を指定します。デフォルト値は
failです。イベントをスキップする場合や警告を発行する場合は、それぞれskipまたはwarnを選択します。
- Poll interval (ms): 各反復でコネクターが新しい変更イベントの出現を待機するミリ秒数を入力します。デフォルト値は
Connector details に情報を追加します(省略可)。
- Provide transaction metadata: トランザクションメタデータ を有効にするかどうかを選択します。トランザクションメタデータは、専用の Kafka トピックに保存されます。デフォルトは
falseです。 - Decimal handling mode: 変更イベントでの
DECIMAL列とNUMERIC列の表現方法を指定します。precise(デフォルト値)を指定すると、値の表現に java.math.BigDecimal が使用されます。変更イベントでは、バイナリ表現と Connect の org.apache.kafka.connect.data.Decimal データ型を使用して値がエンコードされます。string 型を使用して値を表すには、stringを選択します。doubleを選択すると、Java のdoubleデータ型を使用して値が表現されます。doubleでは精度が低下する可能性がありますが、コンシューマーでの使いやすさは大幅に向上します。 - Binary handling mode: 変更イベントでのバイナリ(blob、binary)列の表現方法を指定します。バイナリデータをバイト配列形式で表現するには、
bytes(デフォルト値)を選択します。バイナリデータを base64 でエンコードされた文字列形式で表現するには、base64を選択します。バイナリデータを 16 進(base16)でエンコードされた文字列形式で表現するには、hexを選択します。 - Time precision mode: 時間、日付、タイムスタンプは、さまざまな種類の精度で表現できます。
adaptive_time_microsecondsは、マイクロ秒の精度が使用されるすべてのTIMEフィールドでの adaptive 精度に似ています。connect:(デフォルト)時刻、日付、タイムスタンプ値の表現には常に、Connect に組み込まれている Time、Date、および Timestamp の表現が使用されます。connectを選択した場合は、データベース列に使用されている精度に関係なく、精度としてミリ秒が使用されます。詳細については、「Temporal types」を参照してください。 - Topic cleanup policy: トピック保持クリーンアップポリシー を設定します。古いトピックを破棄するには、
delete(デフォルト値)を選択します。トピックでの ログ圧縮 を有効にするには、compactを選択します。 - Bigint Unsigned handling mode: 変更イベントにおける、符号なしの
BIGINT列の表現方法を指定します。データ型long(デフォルト)またはpreciseを選択できます。preciseを指定すると、値の表現に java.math.BigDecimal が使用されます。変更イベントでは、バイナリ表現と Connect の org.apache.kafka.connect.data.Decimal データ型を使用して値がエンコードされます。 - Enable time adjuster: 年の値の変換をコネクターで調整する(
true)か、データベースに委任する(false)かを指定します。デフォルト値はtrueです。
- Provide transaction metadata: トランザクションメタデータ を有効にするかどうかを選択します。トランザクションメタデータは、専用の Kafka トピックに保存されます。デフォルトは
以下の Output プロパティについて、値を選択します。
Output Kafka record value フォーマット: コネクターから送られるデータのフォーマットを AVRO、JSON(スキーマレス)、JSON_SR(JSON スキーマ)、または PROTOBUF から選択します。スキーマベースのレコードフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
After-state only:(省略可)デフォルトでは true となり、Kafka レコードは、適用された変更イベントからのレコードステートのみを持ちます。false を選択すると、変更イベントの適用後も以前のレコードステートが維持されます。
Output Kafka record key format: コネクターから送られるデータのフォーマットを AVRO、JSON(スキーマレス)、JSON_SR(JSON スキーマ)、PROTOBUF、または String から選択します。スキーマベースのレコードフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、有効なスキーマが Schema Registry に存在する必要があります。
JSON output decimal format:(省略可)デフォルトでは BASE64 です。
このコネクターで使用する タスク の数を入力します。組織では複数のコネクターを実行できますが、コネクターあたり 1 つのタスク(
"tasks.max": "1")という制限があります。Transforms and Predicates: 詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
See 構成プロパティ for all properties and definitions.
ステップ 5: コネクターを起動します。¶
接続の詳細情報を確認し、Launch をクリックします。
ステップ 6: コネクターのステータスを確認します。¶
コネクターのステータスが Provisioning から Running に変わります。ステータスが変わるまで数分かかる場合があります。
ステップ 7: Kafka トピックを確認します。¶
コネクターが実行中になったら、メッセージが Kafka トピックに取り込まれていることを確認します。
注釈
A topic named dbhistory.<database.server.name>.<connect-id> is
automatically created for database.history.kafka.topic with one partition.
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。

Confluent CLI の使用¶
以下の手順に従うと、Confluent CLI を使用してコネクターをセットアップし、実行できます。
注釈
- すべての 前提条件 を満たしていることを確認してください。
- コマンド例では Confluent CLI バージョン 2 を使用しています。詳細については、「Confluent CLI v2 への移行」を参照してください。
ステップ 2: コネクターの必須の構成プロパティを表示します。¶
以下のコマンドを実行して、コネクターの必須プロパティを表示します。
confluent connect plugin describe <connector-catalog-name>
例:
confluent connect plugin describe MySqlCdcSource
出力例:
Following are the required configs:
connector.class: MySqlCdcSource
name
kafka.auth.mode
kafka.api.key
kafka.api.secret
database.hostname
database.user
database.server.name
output.data.format
tasks.max
ステップ 3: コネクターの構成ファイルを作成します。¶
コネクター構成プロパティを含む JSON ファイルを作成します。以下の例は、コネクターの必須プロパティを示しています。
{
"connector.class": "MySqlCdcSource",
"name": "MySqlCdcSourceConnector_0",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "****************",
"kafka.api.secret": "****************************************************************",
"database.hostname": "database-2.<host-ID>.us-west-2.rds.amazonaws.com",
"database.port": "3306",
"database.user": "admin",
"database.password": "**********",
"database.server.name": "mysql",
"database.whitelist": "employee",
"table.includelist":"employees.departments,
"snapshot.mode": "initial",
"output.data.format": "AVRO",
"tasks.max": "1"
}
以下のプロパティ定義に注意してください。
"connector.class": コネクターのプラグイン名を指定します。"name": 新しいコネクターの名前を設定します。
"kafka.auth.mode": 使用するコネクターの認証モードを指定します。オプションはSERVICE_ACCOUNTまたはKAFKA_API_KEY(デフォルト)です。API キーとシークレットを使用するには、構成プロパティkafka.api.keyとkafka.api.secretを構成例(前述)のように指定します。サービスアカウント を使用するには、プロパティkafka.service.account.id=<service-account-resource-ID>に リソース ID を指定します。使用できるサービスアカウントのリソース ID のリストを表示するには、次のコマンドを使用します。confluent iam service-account list
例:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"database.ssl.mode":database.ssl.modeがコネクター構成に追加されない場合は、デフォルトオプションのpreferが有効になります。preferが有効の場合、コネクターは、データベースサーバーに対して暗号化された接続の使用を試みます。オプションpreferおよびrequireでは、セキュアな(暗号化された)接続を使用します。セキュアな接続を確立できない場合、コネクターは失敗します。これらのモードでは、認証機関(CA)検証は行われません。"table.whitelist":(オプション)コネクターでモニタリングするテーブルの完全修飾識別子をコンマ区切りにしたリストを入力します。デフォルトでは、コネクターはシステムテーブル以外のテーブルを "すべて" モニタリングします。完全修飾テーブル名のフォームは、schemaName.tableNameです。"column.exclude.list":(省略可能)変更イベントレコードの値から除外する列の完全修飾名に一致する正規表現のリスト。コンマ区切りで指定します。列の完全修飾名は、databaseName.tableName.columnNameという形式になります。"snapshot.mode":(省略可能)コネクターの起動時にデータベーススナップショットを実行する条件を指定します。- デフォルトオプションは、
initialです。選択すると、コネクターは、キャプチャー対象テーブルの構造およびデータのスナップショットを取得します。これは、コネクターの起動時にキャプチャー対象テーブルの完全なデータ表現をトピックに取り込む必要がある場合に便利です。 never: コネクターでスナップショットを一切実行しないこと、また、コネクターを最初に起動するときには前回終了した位置から読み取りを開始することを指定します。when_needed: コネクターがスナップショットが必要であると判断した場合にスナップショットを実行することを指定します。schema_only: コネクターがスキーマのスナップショットを実行する際にデータは含めないことを指定します。このオプションは、トピックにデータの整合スナップショットを含める必要はなくとも、コネクター起動後の変更のみ含める必要がある場合に便利です。schema_only_recovery: 既に変更をキャプチャーしているコネクターのリカバリオプション。コネクターは、破損または紛失したデータベース履歴トピックを再起動時にリカバリします。このオプションを定期的に使用して、想定外に大きくなっているデータベース履歴トピックをクリーンアップできます。
- デフォルトオプションは、
"snapshot.locking.mode":(オプション)スナップショット実行時にグローバルな読み取りロックを保持する長さを制御できます。デフォルトはminimalです。コネクターは、グローバルな読み取りロック(あらゆるアップデートを防止)をスナップショットの最初の部分についてのみ保持します。データベーススキーマとその他のメタデータは読み取り可能です。スナップショットの残りの処理には、各テーブルのすべての行の選択が含まれます。この処理は、読み取りロックがオフで他の操作によってデータベースが更新中であっても、REPEATABLE READトランザクションを使用して完了されます。(Percona サーバーの場合はminimal_perconaを使用します)。場合によっては、スナップショットが完了するまですべての書き込みをブロックすることが望ましいことがあります。このような場合は、このプロパティをextendedに設定します。オプションnoneでは、コネクターがスナップショット中にテーブルロックを実行するのを防止します。この設定はすべてのスナップショットモードで使用できますが、スナップショット実行中にスキーマが変更されない場合にのみ使用することをおすすめします。MyISAM エンジンで定義されたテーブルの場合は、MyISAM がテーブルロックを取得するので、このプロパティの設定に関係なくテーブルはロックされます。この動作は、InnoDB エンジンとは異なります。こちらは行レベルのロックを取得します。"output.data.format": Kafka 出力レコード値のフォーマット(コネクターから送られるデータ)を設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのレコードフォーマット(Avro、JSON_SR(JSON スキーマ)、Protobuf など)を使用するには、Confluent Cloud Schema Registry を構成しておく必要があります。after.state.only:(省略可)デフォルトでは true となり、Kafka レコードは、適用された変更イベントからのレコードステートのみを持ちます。false と入力すると、変更イベントの適用後も以前のレコードステートが維持されます。"json.output.decimal.format":(省略可)デフォルトでは BASE64 です。次の 2 つのリテラル値を取る Connect DECIMAL 論理型の値の JSON/JSON_SR シリアル化フォーマットを指定します。- BASE64 では、DECIMAL 論理型を base64 でエンコードされたバイナリデータとしてシリアル化します。
- NUMERIC では、JSON または JSON_SR の Connect DECIMAL 論理型の値を、10 進数の値を表す数字としてシリアル化します。
"tasks.max": このコネクターで使用する タスク の数を入力します。組織では複数のコネクターを実行できますが、コネクターあたり 1 つのタスク("tasks.max": "1")という制限があります。
Single Message Transforms: CLI を使用する SMT の追加の詳細については、Single Message Transforms(SMT) のドキュメントを参照してください。
See 構成プロパティ for all properties and definitions.
ステップ 4: プロパティファイルを読み込み、コネクターを作成します。¶
以下のコマンドを入力して、構成を読み込み、コネクターを起動します。
confluent connect create --config <file-name>.json
例:
confluent connect create --config mysql-cdc-source.json
出力例:
Created connector MySqlCdcSourceConnector_0 lcc-ix4dl
ステップ 5: コネクターのステータスを確認します。¶
以下のコマンドを入力して、コネクターのステータスを確認します。
confluent connect list
出力例:
ID | Name | Status | Type
+-----------+-----------------------------+---------+-------+
lcc-ix4dl | MySqlCdcSourceConnector_0 | RUNNING | source
ステップ 6: Kafka トピックを確認します。¶
コネクターが実行中になったら、メッセージが Kafka トピックに取り込まれていることを確認します。
注釈
A topic named dbhistory.<database.server.name>.<connect-id> is
automatically created for database.history.kafka.topic with one partition.
Connect 用の Confluent Cloud API の使用に関する詳細とサンプルについては、「Confluent Cloud API for Connect」セクションを参照してください。
構成プロパティ¶
このコネクターでは、以下のコネクター構成プロパティを使用します。
データへの接続方法(How should we connect to your data?)¶
nameコネクターの名前を設定します。
- 型: string
- 指定可能な値: 最大 64 文字の文字列
- 重要度: 高
Kafka クラスターの認証情報(Kafka Cluster credentials)¶
kafka.auth.modeKafka の認証モード。KAFKA_API_KEY または SERVICE_ACCOUNT を指定できます。デフォルトは KAFKA_API_KEY モードです。
- 型: string
- デフォルト: KAFKA_API_KEY
- 指定可能な値: KAFKA_API_KEY、SERVICE_ACCOUNT
- 重要度: 高
kafka.api.key- 型: password
- 重要度: 高
kafka.service.account.idKafka クラスターとの通信用の API キーを生成するために使用されるサービスアカウント。
- 型: string
- 重要度: 高
kafka.api.secret- 型: password
- 重要度: 高
データベースへの接続方法(How should we connect to your database?)¶
database.hostnameMySQL サーバーのアドレス。
- 型: string
- 重要度: 高
database.portMySQL サーバーのポート番号。
- 型: int
- 指定可能な値: [0,...,65535]
- 重要度: 高
database.user必要な認可を持つ MySQL サーバーユーザーの名前。
- 型: string
- 重要度: 高
database.password必要な認可を持つ MySQL サーバーユーザーのパスワード。
- 型: password
- 重要度: 高
database.server.nameMySQL サーバークラスターの論理名。この論理名は 1 つの名前空間を形成し、すべての Kafka トピック名および Kafka Connect スキーマ名で使用されます。また、Avro データフォーマットが使用される場合、論理名は、対応する Avro スキーマの名前空間でも使用されます。Kafka トピックは、プレフィックス
database.server.nameを付加して作成する必要があります(そのように作成されます)。英数字、アンダースコア、ハイフン、ドットのみを使用できます。- 型: string
- 重要度: 高
database.ssl.modeデータベースへの接続に使用する必要がある SSL モードを指定します。デフォルトの preferred オプションでは、サーバーがセキュアな接続をサポートしている場合に、暗号化された接続を確立します。サーバーがセキュアな接続をサポートしていない場合は、非暗号化接続にフォールバックします。required オプションでは、暗号化された接続を確立します。なんらかの理由で暗号化された接続を確立できない場合はエラーになります。
- 型: string
- デフォルト: preferred
- 重要度: 低
データベースの詳細(Database details)¶
signal.data.collectionFully-qualified name of the data collection that needs to be used to send signals to the connector. Use the following format to specify the fully-qualified collection name:
databaseName.tableName- 型: string
- 重要度: 中
database.include.listモニタリング対象のデータベース名に一致する文字列のリスト(省略可能)。コンマ区切りで指定します。リストに含まれないデータベース名はすべて、モニタリング対象から除外されます。デフォルトでは、すべてのデータベースがモニタリング対象です。database.exclude.list と一緒に使用することはできません。
- 型: list
- 重要度: 中
database.exclude.listモニタリング対象から除外するデータベース名に一致する文字列のリスト(省略可能)。コンマ区切りで指定します。リストに含まれないデータベース名はすべて、モニタリング対象となります。database.include.list と一緒に使用することはできません。
- 型: list
- 重要度: 中
table.include.listモニタリング対象のテーブルの完全修飾識別子と一致する文字列のコンマ区切りのリスト(省略可)。この構成プロパティに含まれていないテーブルはすべて、モニタリング対象から除外されます。各識別子は、
schemaName.tableNameという形式になります。デフォルトでは、コネクターはモニタリング対象の各スキーマのすべての非システムテーブルをモニタリングします。"Table excluded" と一緒に使用することはできません。- 型: list
- 重要度: 中
database.connectionTimeZone値は有効な ZoneId である必要があります。
- 型: string
- 重要度: 低
table.exclude.listモニタリング対象から除外するテーブルの完全修飾識別子と一致する文字列のコンマ区切りのリスト(省略可)。この構成プロパティに含まれていないテーブルはすべて、モニタリングの対象になります。各識別子は、
schemaName.tableNameという形式になります。"Table included" と一緒に使用することはできません。- 型: list
- 重要度: 中
datatype.propagate.source.typeデータベース固有のデータ型名と一致する正規表現のコンマ区切りのリスト。出力された変更レコードの対応するフィールドスキーマに、データ型の元の型と元の長さがパラメーターとして追加されます。
- 型: list
- 重要度: 低
snapshot.modeコネクターの起動時にスナップショットを実行する基準を指定します。デフォルトの設定は initial であり、この設定では、論理サーバー名で記録されたオフセットがない場合にのみコネクターがスナップショットを実行できます。when_needed オプションを指定すると、コネクターの起動時に必要な場合は、スナップショットを実行します。必要な場合とは通常、オフセットを使用できない場合、または、以前記録されたオフセットで、サーバーでは利用できない binlog の場所または GTID が指定されている場合です。never オプションを指定すると、コネクターでスナップショットが一切使用されません。また、論理サーバー名を指定してコネクターが起動された場合、コネクターは binlog を先頭から読み取ります。never オプションは、binlog にデータベースの全履歴が含まれていることが保証されている場合にのみ有効であるため、使用には注意が必要です。schema_only オプションでは、スキーマのスナップショットが実行されますがデータのスナップショットは実行されません。この設定は、トピックにデータの整合スナップショットを含める必要はなくとも、コネクター起動後の変更のみ含める必要がある場合に便利です。schema_only_recovery オプションは、既に変更をキャプチャーしているコネクターのリカバリ設定です。コネクターを再起動した場合、この設定によって、破損または紛失したデータベース履歴トピックのリカバリが有効になります。これを定期的に設定して、想定外に大きくなっているデータベース履歴トピックを "クリーンアップ" できます。データベース履歴トピックは、無限のデータ保持が要求されます。
- 型: string
- デフォルト: initial
- 指定可能な値: initial、never、schema_only、schema_only_recovery、when_needed
- 重要度: 低
snapshot.locking.modeスナップショット実行時にグローバルな読み取りロックを保持する長さを制御できます。デフォルトは minimal です。コネクターは、スナップショットの最初の部分についてのみグローバルな読み取りロックを保持します(これにより更新が防止されます)が、データベーススキーマおよびその他のメタデータは読み取り可能になります。スナップショットの残りの処理には、各テーブルのすべての行の選択が含まれます。この処理は、読み取りロックが解除され、他の操作によってデータベースが更新中であっても、REPEATABLE READ トランザクションを使用して完了されます。ただし、場合によっては、スナップショットが完了するまで、すべての書き込みをブロックすることが望ましいことがあります。このような場合は、このプロパティを extended に設定します。値として none を使用すると、スナップショットの処理中にコネクターがテーブルロックを取得できなくなります。この設定はすべてのスナップショットモードで使用できますが、スナップショット実行中にスキーマが変更されない場合にのみ使用することをお勧めします。
- 型: string
- デフォルト: minimal
- 指定可能な値: extended、minimal、minimal_percona、none
- 重要度: 低
tombstones.on.deletedelete イベントの後に tombstone イベントを生成するかどうかを制御します。
trueに設定すると、削除操作は delete イベント、およびそれに続く tombstone イベントで表されます。falseに設定すると、delete イベントだけが送信されます。tombstone イベントの実行(デフォルトの動作)により、Kafka はソースレコードが削除されてから特定のキーに関連したすべてのイベントを完全に削除できるようになります。- 型: boolean
- デフォルト: true
- 重要度: 高
column.exclude.list変更イベントから除外する列と一致する正規表現。
- 型: list
- 重要度: 中
接続の詳細(Connection details)¶
poll.interval.ms各反復処理中にコネクターが新しい変更イベントの出現を待機するミリ秒数を指定する正の整数値。デフォルトは 1000 ミリ秒(1 秒)です。
- 型: int
- デフォルト: 1000(1 秒)
- 指定可能な値: [1,...]
- 重要度: 低
max.batch.sizeこのコネクターの各反復処理中に処理されるイベントの各バッチの最大サイズを指定する正の整数値。
- 型: int
- デフォルト: 1000
- 指定可能な値: [1,...,5000]
- 重要度: 低
event.processing.failure.handling.modebinlog イベントの処理中にコネクターが例外に対応する方法を指定します。
- 型: string
- デフォルト: fail
- 指定可能な値: fail、skip、warn
- 重要度: 低
heartbeat.interval.msコネクターがハートビートメッセージを Kafka トピックに送信する頻度を制御します。デフォルト値 0 の動作では、コネクターはハートビートメッセージを送信しません。
- 型: int
- デフォルト: 0
- 指定可能な値: [0,...]
- 重要度: 低
database.history.skip.unparseable.ddl形式に誤りがある、または不明なデータベースステートメントが見つかった場合の対応を指定するブール値。コネクターで、それらを無視する(true)か、人間が問題を修正できるように処理を停止する(false)かを指定します。デフォルトは false です。解析不能なステートメントを無視するには、これを true に設定することを検討してください。
- 型: boolean
- デフォルト: false
- 重要度: 低
event.deserialization.failure.handling.modebinlog イベントの逆シリアル化中の例外にコネクターが対応する方法を指定します。
- 型: string
- デフォルト: fail
- 指定可能な値: fail、skip、warn
- 重要度: 中
inconsistent.schema.handling.mode内部スキーマ表現に含まれていないテーブルに属する binlog イベントへの、コネクターによる対応方法を指定します。
- 型: string
- デフォルト: fail
- 指定可能な値: fail、skip、warn
- 重要度: 中
コネクターの詳細(Connector details)¶
provide.transaction.metadataトランザクションメタデータの情報を専用トピックに保存し、イベントのカウントとともにトランザクションメタデータを抽出できるようにします。
- 型: boolean
- デフォルト: false
- 重要度: 低
decimal.handling.mode変更イベントでの DECIMAL 列と NUMERIC 列の表現方法を指定します。「precise」(デフォルト)の場合、java.math.BigDecimal を使用して値が表現されます。この値は変更イベントでバイナリ表現と Kafka Connect の「org.apache.kafka.connect.data.Decimal」型を使用してエンコードされます。「string」の場合、文字列を使用して値が表現されます。「double」の場合、Java の「double」を使用して値が表現されます。この場合、精度が低下する可能性がありますが、コンシューマーでの使いやすさは大幅に向上します。
- 型: string
- デフォルト: precise
- 指定可能な値: double、precise、string
- 重要度: 中
binary.handling.mode変更イベントでのバイナリ列(blob、binary など)の表現方法を指定します。「bytes」(デフォルト)の場合、バイナリデータがバイト配列で表現されます。「base64」の場合、バイナリデータが base64 でエンコードされた文字列で表現されます。「hex」の場合、バイナリデータが 16 進エンコードされた(base16)文字列で表現されます。
- 型: string
- デフォルト: bytes
- 指定可能な値: base64、bytes、hex
- 重要度: 低
time.precision.mode時間、日付、タイムスタンプは、さまざまな種類の精度で表現することができます。「adaptive_time_microseconds」では、TIME フィールドで常にマイクロ秒の精度が使用されます。「connect」(デフォルト)の場合、時刻、日付、タイムスタンプ値の表現には常に、Kafka Connect に組み込まれている Time、Date、および Timestamp の表現が使用されます。つまり、データベースの列の精度に関係なく、ミリ秒の精度が使用されます。
- 型: string
- デフォルト: connect
- 指定可能な値: adaptive_time_microseconds、connect
- 重要度: 中
cleanup.policyトピッククリーンアップポリシーを設定します。
- 型: string
- デフォルト: delete
- 指定可能な値: compact、delete
- 重要度: 中
bigint.unsigned.handling.mode変更イベントでの BIGINT UNSIGNED 列の表現方法を指定します。
- 型: string
- デフォルト : long
- 指定可能な値: long、precise
- 重要度: 中
enable.time.adjuster年の値の変換をコネクターで調整するか、データベースに委任するかを指定します。
- 型: boolean
- デフォルト: true
- 重要度: 中
出力メッセージ(Output messages)¶
output.data.formatKafka 出力レコード値のフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、または JSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください。
- 型: string
- 重要度: 高
output.key.formatKafka 出力レコードキーのフォーマットを設定します。指定可能なエントリは、AVRO、JSON_SR、PROTOBUF、STRING、または JSON です。スキーマベースのメッセージフォーマット(AVRO、JSON_SR、PROTOBUF など)を使用する場合は、Confluent Cloud Schema Registry を構成しておく必要がある点に注意してください
- 型: string
- デフォルト: JSON
- 指定可能な値: AVRO、JSON、JSON_SR、PROTOBUF、STRING
- 重要度: 高
after.state.only生成された Kafka レコードに変更イベント適用後のステートのみを含めるかどうかを制御します。
- 型: boolean
- デフォルト: true
- 重要度: 低
json.output.decimal.format次の 2 つのリテラル値を取る Connect DECIMAL 論理型の値の JSON/JSON_SR シリアル化フォーマットを指定します。
BASE64 では、DECIMAL 論理型を base64 でエンコードされたバイナリデータとしてシリアル化します。
NUMERIC では、JSON/JSON_SR の Connect DECIMAL 論理型の値を、10 進数の値を表す数字としてシリアル化します。
- 型: string
- デフォルト: BASE64
- 重要度: 低
このコネクターのタスク数(Number of tasks for this connector)¶
tasks.max- 型: int
- 指定可能な値: [1,…,1]
- 重要度: 高
次のステップ¶
参考
フルマネージド型の Confluent Cloud コネクターが Confluent Cloud ksqlDB でどのように動作するかを示す例については、「Cloud ETL のデモ」を参照してください。この例では、Confluent CLI を使用して Confluent Cloud のリソースを管理する方法についても説明しています。