
Tables and Topics in Confluent Cloud for Apache Flink
Apache Flink® and the Table API use the concept of dynamic tables to facilitate the manipulation and processing of streaming data. Dynamic tables represent an abstraction for working with both batch and streaming data in a unified manner, offering a flexible and expressive way to define, modify, and query structured data. In contrast to the static tables that represent batch data, dynamic tables change over time. But like static batch tables, systems can execute queries over dynamic tables.
Confluent Cloud for Apache Flink® implements ANSI-Standard SQL and has the familiar concepts of catalogs, databases, and tables. Confluent Cloud maps a Flink catalog to an environment and vice-versa. Similarly, Flink databases and tables are mapped to Apache Kafka® clusters and topics. For more information, see Metadata mapping between Kafka cluster, topics, schemas, and Flink.
Dynamic tables and continuous queries
Every table in Flink is equivalent to a stream of events that describe the changes to that table. A stream of changes like this is a changelog stream. Essentially, a stream is the changelog of a table, and a stream backs every table. This is also the case for regular database tables.
Querying a dynamic table yields a continuous query. A continuous query never terminates and produces dynamic results – another dynamic table. The query continuously updates its dynamic result table to reflect changes on its dynamic input tables. Essentially, a continuous query on a dynamic table is similar to a query that defines a materialized view.
The output of a continuous query is always equivalent to the result of the same query executed in batch mode on a snapshot of the input tables.
Append-only table
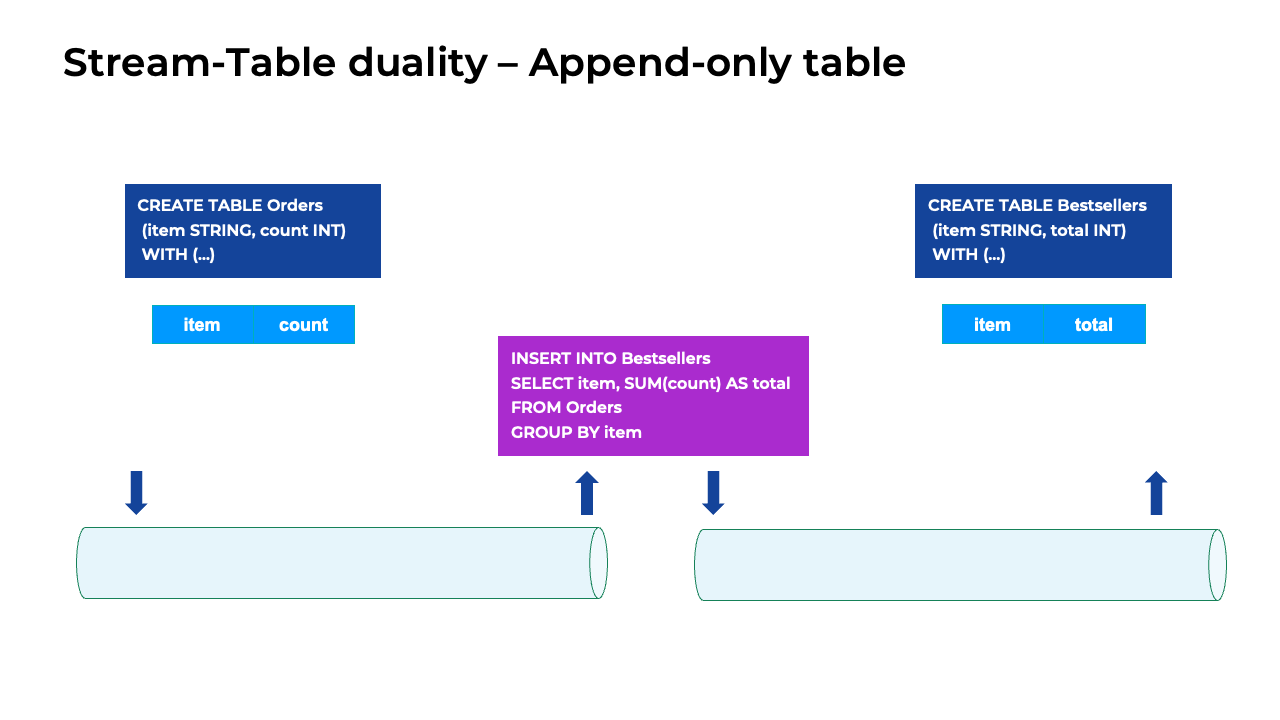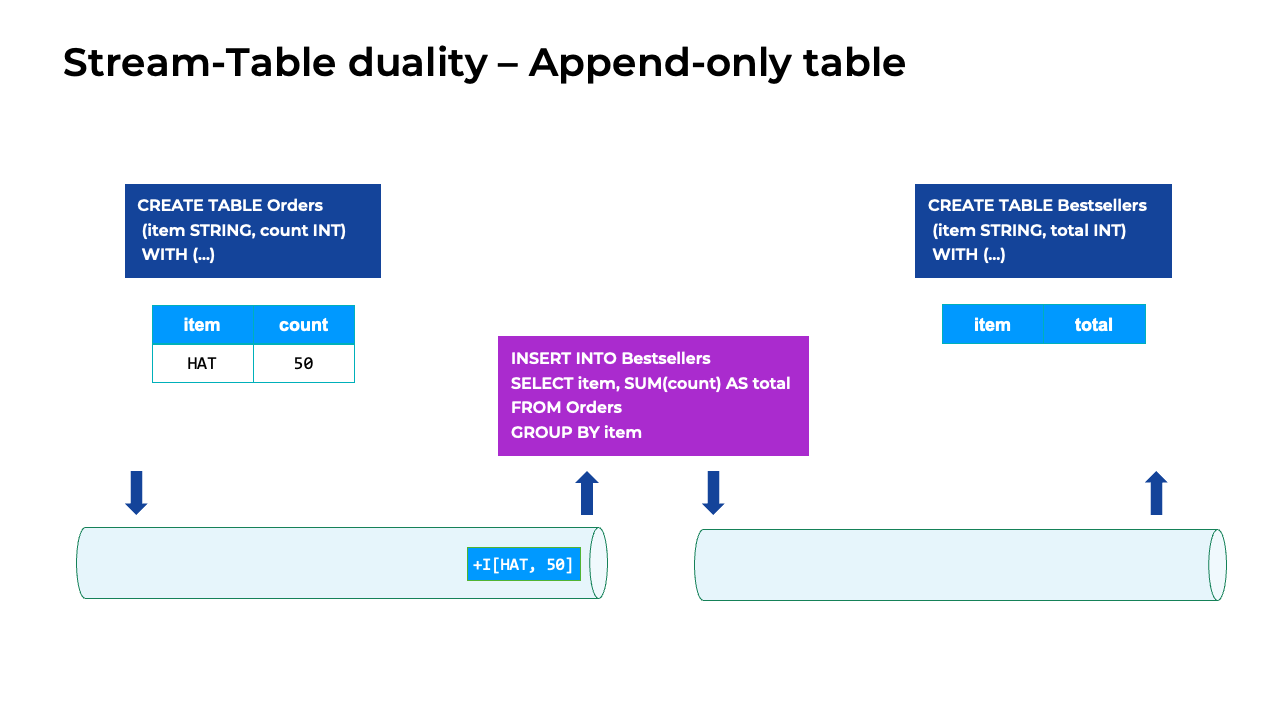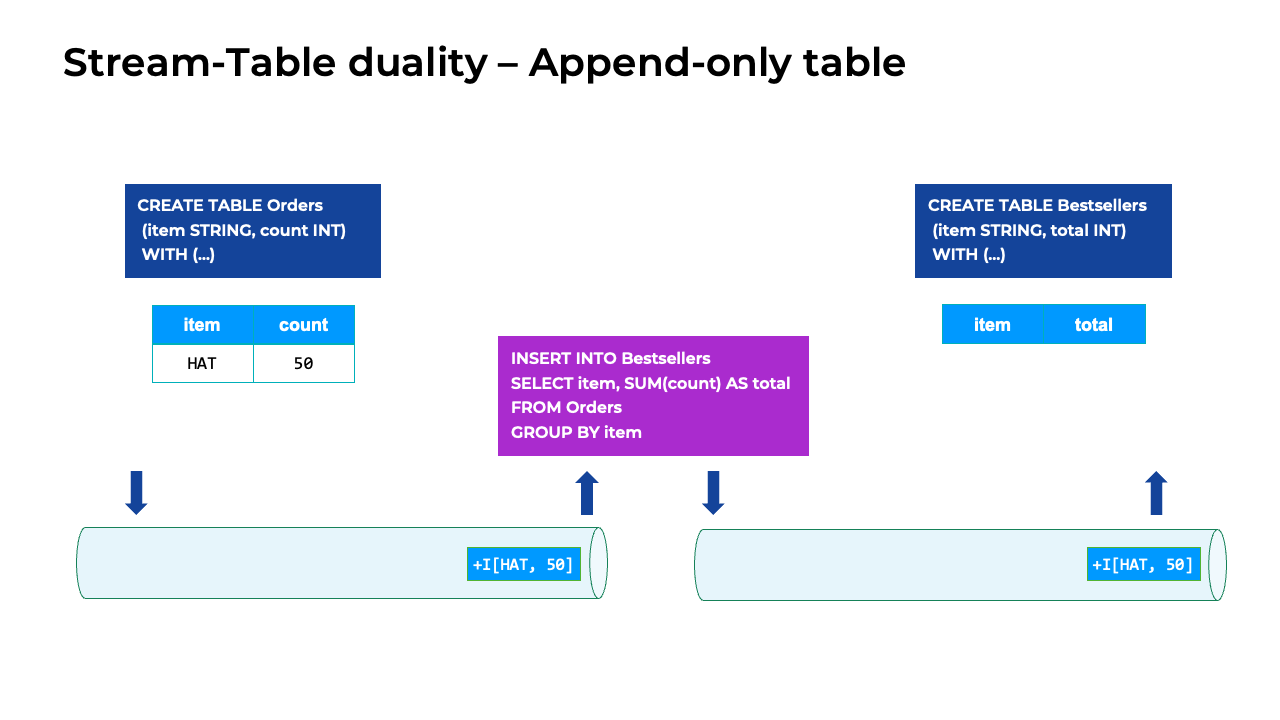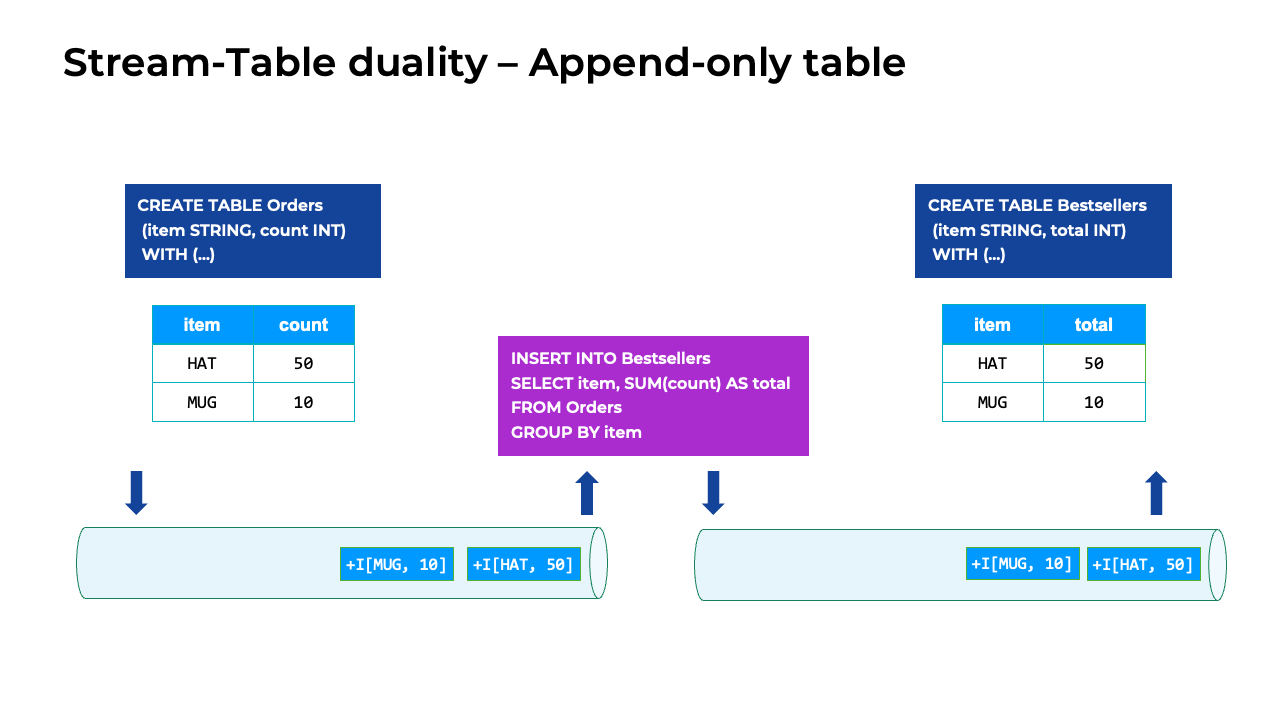
Stream-table table duality for an append-only table
In this animation, the only changes happening to the Orders table are the new orders being appended to the end of the table. The corresponding changelog stream is just a stream of INSERT events. Adding another order to the table is the same as adding another INSERT statement to the stream, as shown below the table. This is an example of an append-only or insert-only table.
Updating table
Not all tables are append-only tables. Tables can also contain events that modify or delete existing rows. The changelog stream used by Flink SQL contains three additional event types to accommodate different ways that tables can be updated. Besides the regular Insertion event, Update Before and Update After are a pair of events that work together to update an earlier result. The Delete event has the effect you would expect, removing a record from the table.
Stream-table table duality for an updating table
This animation has the same starting point as the previous example that showed the append-only table. But this time, the user canceled an order, and the item in that order didn’t sell. As a result, the Bestsellers table is updated, rather than receiving another insert. The update starts with another order appended to the append-only/insert-only Orders table, which the changelog stream registers as an INSERT event.
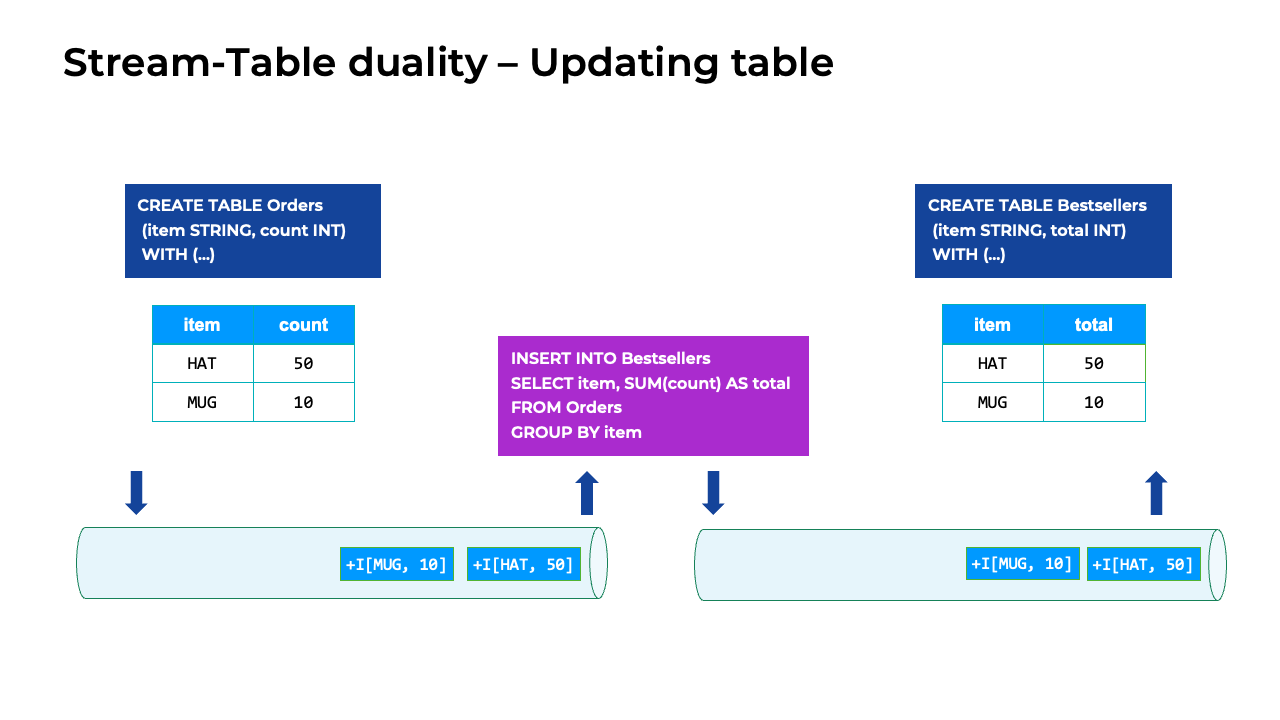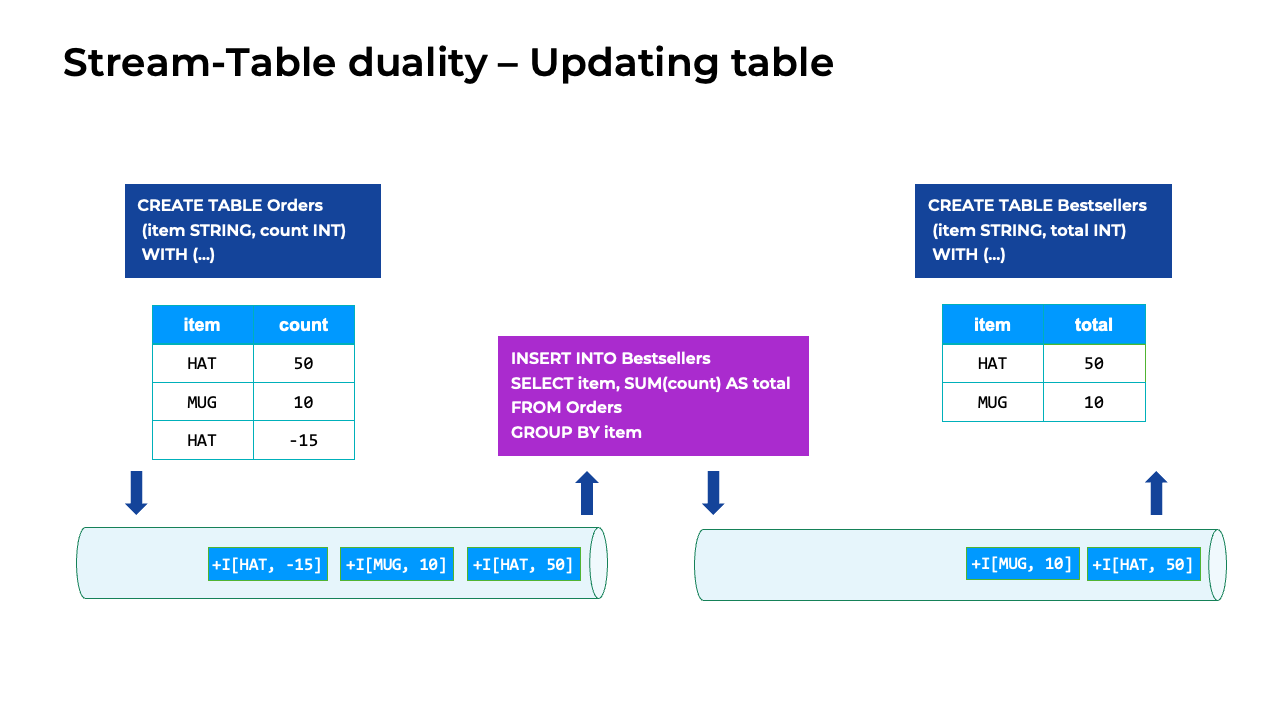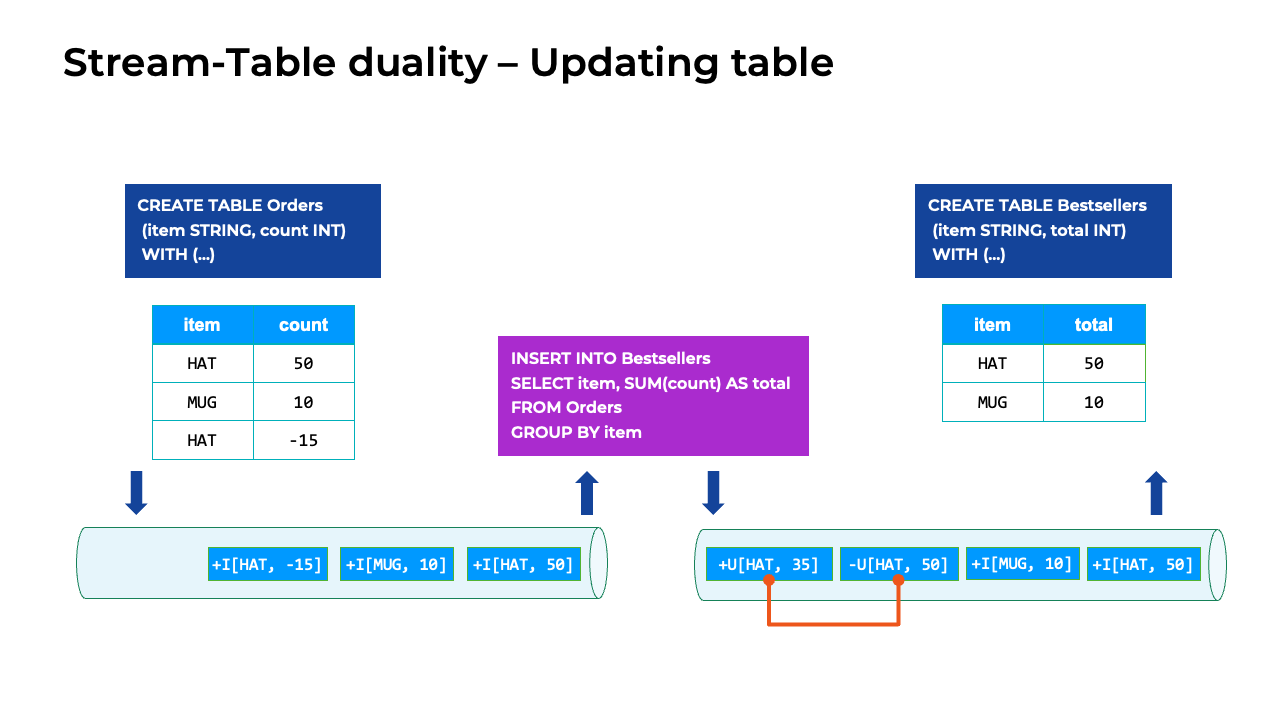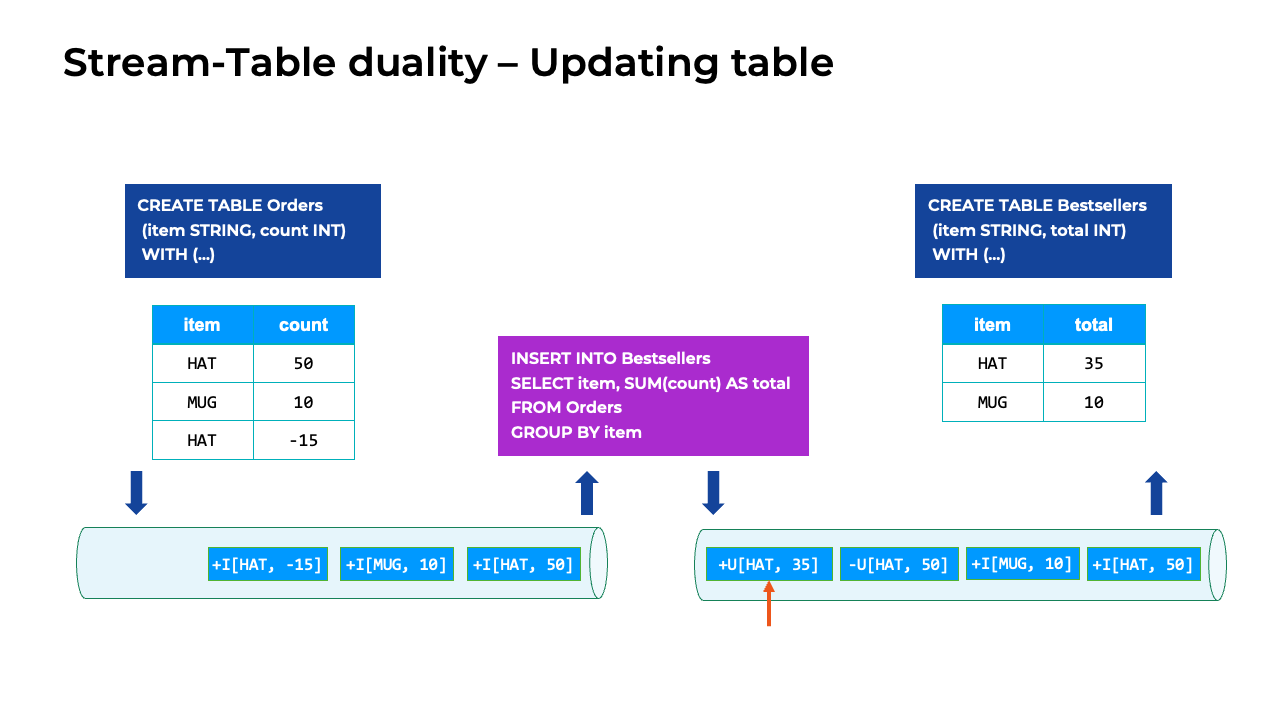
Because the SQL statement does grouping, the result is an updating table instead of an append-only/insert-only table. In this example, the user cancels an order for 15 hats. To process the event with the 15-hat order cancellation, the query produces two update events:
The first is an UPDATE_BEFORE event that retracts the current result that showed 50 hats as the bestselling item.
The second is an UPDATE_AFTER event that replaces the old entry with a new one that shows 35 hats.
Conceptually, Confluent Cloud for Apache Flink processes the UPDATE_BEFORE event first, which removes the old entry from the Bestsellers table. Then, the sink processes the UPDATE_AFTER event, which inserts the updated results.
The following figure visualizes the relationship of streams, dynamic tables, and continuous queries:
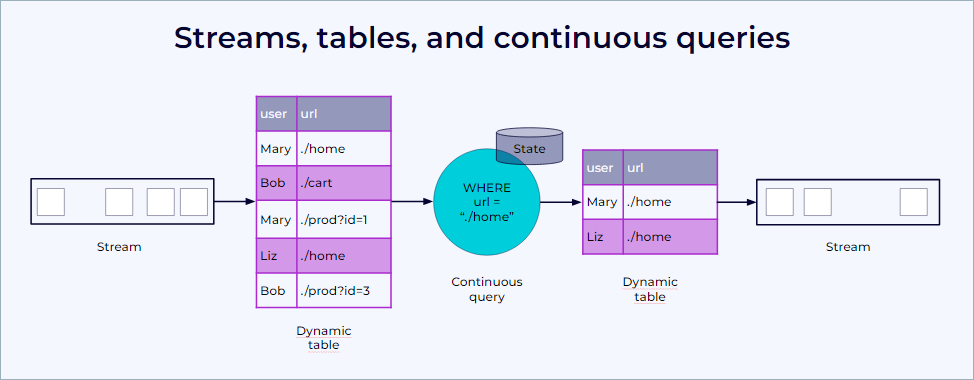
Confluent Cloud for Apache Flink converts a stream into a dynamic table.
Confluent Cloud for Apache Flink evaluates a continuous query on the dynamic table, yielding a new dynamic table.
Confluent Cloud for Apache Flink converts the resulting dynamic table back into a stream.
Dynamic tables are a logical concept. The Flink SQL runtime materializes only the state strictly necessary to produce correct results for the specific query that runs. For example, the previous diagram shows a query that executes a simple filter. This requires no state, so the runtime materializes nothing.
Changelog entries
Flink provides four different types of changelog entries:
Short name | Long name | Semantics |
|---|---|---|
+I | Insertion | Records only the insertions that occur. |
-U | Update Before | Retracts a previously emitted result. Update Before is an update operation with the previous content of the updated row. This kind occurs together with Update After (+U) for modeling an update that must retract the previous row first. It is useful in cases of a non-idempotent update, which is an update of a row that is not uniquely identifiable by a key. |
+U | Update After | Updates a previously emitted result. Update After is an update operation with new content for the updated row. This kind can occur together with Update Before (-U) for modeling an update that must retract the previous row first, or it can describe an idempotent update, which is an update of a row that is uniquely identifiable by a key. |
-D | Delete | Deletes the last result. |
The - character always indicates row removal.
If the downstream system supports upserting, you should use a primary key in Confluent Cloud for Apache Flink to avoid the need to use Update Before.
Depending on the combination of source, sink, and business logic applied, you can end up with the following types of changelog streams.
Changelog stream types | Stream category | Changelog entry types |
|---|---|---|
Appending stream | Append stream | Contains only +I |
Upserting streams | Update stream | +I, +U, -D (never contains -U but can contain +U and/or -D) |
Retracting stream | Update stream | +I, +U, -U, -D (contains +I and can contain -U and/or -D) |
All streams can have +I / inserts.
Both retract and upsert streams can have -D / deletes and +U / upserts (upsert afters).
Only retract streams can have -U.
The internal changelog versus a changelog you own
The changelog described above is the internal changelog: Flink’s own representation of how a table changes over time, expressed as the +I, -U, +U, and -D row kinds. Flink produces and consumes it automatically. When Flink writes a table to a Apache Kafka® topic, the table’s changelog mode (append, upsert, or retract) decides how each row kind is encoded on that topic so that Flink can read it back later.
This is different from a changelog that another system owns, which this documentation calls a custom changelog. In a custom changelog, the operation is stated explicitly in a field that you define, for example a change data capture (CDC) record with an op field set to c, u, or d. Flink doesn’t interpret that field natively, and a non-Flink consumer doesn’t interpret Flink’s internal row kinds either. To read a custom changelog into Flink, or to produce one for a downstream consumer, use the FROM_CHANGELOG and TO_CHANGELOG built-in functions. For a step-by-step guide, see Read and write custom changelog formats.
Some CDC formats are an exception. Flink natively understands a set of standard changelog formats, including Debezium, so even though a Debezium record carries an explicit operation, Flink decodes it for you and you don’t need FROM_CHANGELOG. A changelog is custom in the sense used here only when Flink has no built-in format for it. For the formats Flink recognizes, see changelog formats.