
MySQL CDC Source (Debezium) Connector [End of Life] for Confluent Cloud
Important
This connector reached its end of life (EOL) on March 31, 2026. Confluent recommends migrating to MySQL CDC Source V2 (Debezium) connector. For more information, see Deprecated and end of life connectors.
The fully-managed MySQL Change Data Capture (CDC) Source (Debezium) [Deprecated] connector for Confluent Cloud can obtain a snapshot of the existing data in a MySQL database and then monitor and record all subsequent row-level changes to that data. The connector supports Avro, JSON Schema, Protobuf, or JSON (schemaless) output data formats. All of the events for each table are recorded in a separate Apache Kafka® topic. The events can then be easily consumed by applications and services.
Note
MariaDB is not currently supported. For more information, see the Debezium docs.
This Quick Start is for the fully-managed Confluent Cloud connector. If you are installing the connector locally for Confluent Platform, see Debezium MySQL Source connector for Confluent Platform.
If you require private networking for fully-managed connectors, make sure to set up the proper networking beforehand. For more information, see Manage Networking for Confluent Cloud Connectors.
Features
The MySQL CDC Source (Debezium) [Deprecated] connector provides the following features:
Topics created automatically: The connector automatically creates Kafka topics using the naming convention:
<database.server.name>.<schemaName>.<tableName>. The topics are created with the properties:topic.creation.default.partitions=1andtopic.creation.default.replication.factor=3. For more information, see Maximum message size.Databases included and Databases excluded: Sets whether a database is or is not monitored for changes. By default, the connector monitors every database on the server.
Tables included and Tables excluded: Sets whether a table is or is not monitored for changes.
Output formats: The connector supports Avro, JSON Schema, Protobuf, or JSON (schemaless) output Kafka record value format. It supports Avro, JSON Schema, Protobuf, JSON (schemaless), and String output record key format. Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
Tasks per connector: Organizations can run multiple connectors with a limit of one task per connector (that is,
"tasks.max": "1").Snapshot mode: Specifies the criteria for running a snapshot.
Tombstones on delete: Sets whether a tombstone event is generated after a delete event. Default is
true.Database authentication: Uses password authentication.
SSL support: Supports one-way SSL.
Data formats: Supports Avro, JSON Schema, Protobuf, or JSON (schemaless) output data. Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
Incremental snapshot: Supports incremental snapshotting via signaling. However, the
additional-conditionoption for the signaling feature is not supported in v1. If you are using a legacy version of the connector and need this option, upgrade to the latest version of the connector.Offset management capabilities: Supports offset management. For more information, see Manage custom offsets.
Note
database.server.id is set to a random number between 5400 and 6400.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Limitations
Be sure to review the following information.
For connector limitations, see MySQL CDC Source Connector (Debezium) [Legacy] limitations.
If you plan to use one or more Single Message Transformations (SMTs), see SMT Limitations.
If you plan to use one or more Custom SMTs, see Custom SMT limitations.
Maximum message size
This connector creates topics automatically. When it creates topics, the internal connector configuration property max.message.bytes is set to the following:
Basic cluster:
8 MBStandard cluster:
8 MBEnterprise cluster:
8 MBDedicated cluster:
20 MB
For more information about Confluent Cloud clusters, see Kafka Cluster Types in Confluent Cloud.
Log retention during snapshot
When launched, the CDC connector creates a snapshot of the existing data in the database to capture the nominated tables. To do this, the connector executes a “SELECT *” statement. Completing the snapshot can take a while if one or more of the nominated tables is very large.
During the snapshot process, the database server must retain redo logs and transaction logs so that when the snapshot is complete, the CDC connector can start processing database changes that have completed since the snapshot process began. These logs are retained in a binary log (binlog) on the database server.
If one or more of the tables are very large, the snapshot process could run longer than the binlog retention time set on the database server (that is, expire_logs_days = <number-of-days>). To capture very large tables, you should temporarily retain the binlog for longer than normal by increasing the expire_logs_days number.
Manage custom offsets
You can manage the offsets for this connector. Offsets provide information on the point in the system from which the connector is accessing data. For more information, see Manage Offsets for Fully-Managed Connectors in Confluent Cloud.
To manage offsets:
Manage offsets using Confluent Cloud APIs. For more information, see Connect offsets API reference.
To get the current offset, make a GET request that specifies the environment, Kafka cluster, and connector name.
GET /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets
Host: https://api.confluent.cloud
Response:
Successful calls return HTTP 200 with a JSON payload that describes the offset.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"server": "server_01"
},
"offset": {
"event": 2,
"file": "mysql-bin.000598",
"pos": 2326,
"row": 1,
"server_id": 1,
"transaction_id": null,
"ts_sec": 1711648627
}
}
],
"metadata": {
"observed_at": "2024-03-28T17:57:48.139635200Z"
}
}
Responses include the following information:
The position of latest offset.
The observed time of the offset in the metadata portion of the payload. The
observed_attime indicates a snapshot in time for when the API retrieved the offset. A running connector is always updating its offsets. Useobserved_atto get a sense for the gap between real time and the time at which the request was made. By default, offsets are observed every minute. Calling get repeatedly will fetch more recently observed offsets.Information about the connector.
To update the offset, make a POST request that specifies the environment, Kafka cluster, and connector name. Include a JSON payload that specifies new offset and a patch type.
POST /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request
Host: https://api.confluent.cloud
{
"type": "PATCH",
"offsets": [
{
"partition": {
"server": "server_01"
},
"offset": {
"event": 2,
"file": "mysql-bin.000598",
"pos": 1423,
"row": 1,
"server_id": 1,
"transaction_id": null,
"ts_sec": 1711648518
}
}
]
}
Considerations:
You can only make one offset change at a time for a given connector.
This is an asynchronous request. To check the status of this request, you must use the check offset status API. For more information, see Get the status of an offset request.
For source connectors, the connector attempts to read from the position defined by the requested offsets.
Response:
Successful calls return HTTP 202 Accepted with a JSON payload that describes the offset.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"server": "server_01"
},
"offset": {
"event": 2,
"file": "mysql-bin.000598",
"pos": 1423,
"row": 1,
"server_id": 1,
"transaction_id": null,
"ts_sec": 1711648518
}
}
],
"requested_at": "2024-03-28T17:58:45.606796307Z",
"type": "PATCH"
}
Responses include the following information:
The requested position of the offsets in the source.
The time of the request to update the offset.
Information about the connector.
To delete the offset, make a POST request that specifies the environment, Kafka cluster, and connector name. Include a JSON payload that specifies the delete type.
POST /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request
Host: https://api.confluent.cloud
{
"type": "DELETE"
}
Considerations:
Delete requests delete the offset for the provided partition and reset to the base state. A delete request is as if you created a fresh new connector.
This is an asynchronous request. To check the status of this request, you must use the check offset status API. For more information, see Get the status of an offset request.
Do not issue delete and patch requests at the same time.
For source connectors, the connector attempts to read from the position defined in the base state.
Response:
Successful calls return HTTP 202 Accepted with a JSON payload that describes the result.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [],
"requested_at": "2024-03-28T17:59:45.606796307Z",
"type": "DELETE"
}
Responses include the following information:
Empty offsets.
The time of the request to delete the offset.
Information about Kafka cluster and connector.
The type of request.
To get the status of a previous offset request, make a GET request that specifies the environment, Kafka cluster, and connector name.
GET /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request/status
Host: https://api.confluent.cloud
Considerations:
The status endpoint always shows the status of the most recent PATCH/DELETE operation.
Response:
Successful calls return HTTP 200 with a JSON payload that describes the result. The following is an example of an applied patch.
{
"request": {
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"server": "server_01"
},
"offset": {
"event": 2,
"file": "mysql-bin.000598",
"pos": 1423,
"row": 1,
"server_id": 1,
"transaction_id": null,
"ts_sec": 1711648518
}
}
],
"requested_at": "2024-03-28T17:58:45.606796307Z",
"type": "PATCH"
},
"status": {
"phase": "APPLIED",
"message": "The Connect framework-managed offsets for this connector have been altered successfully. However, if this connector manages offsets externally, they will need to be manually altered in the system that the connector uses."
},
"previous_offsets": [
{
"partition": {
"server": "server_01"
},
"offset": {
"event": 2,
"file": "mysql-bin.000598",
"pos": 2326,
"row": 1,
"server_id": 1,
"transaction_id": null,
"ts_sec": 1711648627
}
}
],
"applied_at": "2024-03-28T17:58:48.079141883Z"
}
Responses include the following information:
The original request, including the time it was made.
The status of the request: applied, pending, or failed.
The time you issued the status request.
The previous offsets. These are the offsets that the connector last updated prior to updating the offsets. Use these to try to restore the state of your connector if a patch update causes your connector to fail or to return a connector to its previous state after rolling back.
JSON payload
The table below offers a description of the unique fields in the JSON payload for managing offsets of the MySQL Change Data Capture (CDC) Source connector.
Field | Definition | Required/Optional |
|---|---|---|
| The number of rows and events to skip while starting from this file and position. Use | Optional |
| The file from the last processed binlog. Use | Required |
| The position from the last processed binlog. Use | Required |
| The number of rows and events to skip while starting from this file and position. Use | Optional |
| The id of the server from which the event originated. For more information, see MySQL documentation. | Optional |
| Mostly null, provided only when | Optional |
| The timestamp at which the event at this pos was executed in the database. | Optional |
Important
Do not reset the offset to an arbitrary number. Use only offsets found in the binlog file. To find offsets in a binlog file, use the mysqlbinlog utility. Offsets appear in this format: # at <offset>
Quick Start
Use this quick start to get up and running with the MySQL CDC Source (Debezium) [Legacy] connector. The quick start provides the basics of selecting the connector and configuring it to obtain a snapshot of the existing data in a MySQL database and then monitoring and recording all subsequent row-level changes.
- Prerequisites
Authorized access to a Confluent Cloud cluster on Amazon Web Services (AWS), Microsoft Azure (Azure), or Google Cloud.
The Confluent CLI installed and configured for the cluster. See Install the Confluent CLI.
Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
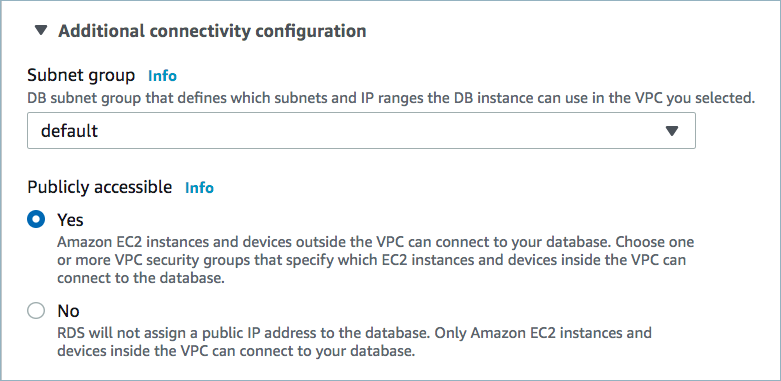
Public access may be required for your database. See Manage Networking for Confluent Cloud Connectors for details. The example below shows the AWS Management Console when setting up a MySQL database.
Public access enabled
For networking considerations, see Networking and DNS. To use a set of public egress IP addresses, see Public Egress IP Addresses for Confluent Cloud Connectors. The example below shows the AWS Management Console when setting up security group rules for the VPC.

Open inbound traffic
Note
See your specific cloud platform documentation for how to configure security rules for your VPC.
Kafka cluster credentials. The following lists the different ways you can provide credentials.
Enter an existing service account resource ID.
Create a Confluent Cloud service account for the connector. Make sure to review the ACL entries required in the service account documentation. Some connectors have specific ACL requirements.
Create a Confluent Cloud API key and secret. To create a key and secret, you can use confluent api-key create or you can autogenerate the API key and secret directly in the Cloud Console when setting up the connector.
Update the following settings for the MySQL database.
Turn on backup for the database.
Create a new parameter group and set the following parameters:
binlog_format=ROW binlog_row_image=full
Apply the new parameter group to the database.
Reboot the database.
The following example screens are from Amazon RDS:



Using the Confluent Cloud Console
Step 1: Launch your Confluent Cloud cluster
To create and launch a Kafka cluster in Confluent Cloud, see Create a kafka cluster in Confluent Cloud.
Step 2: Add a connector
In the left navigation menu, click Connectors. If you already have connectors in your cluster, click + Add connector.
Step 3: Select your connector
Click the MySQL CDC Source (Debezium) [Legacy] connector card.
Step 4: Enter the connector details
Note
Make sure you have all your prerequisites completed.
An asterisk ( * ) designates a required entry.
At the MySQL CDC Source (Debezium) [Legacy] Connector screen, complete the following:
Select the way you want to provide Kafka Cluster credentials. You can choose one of the following options:
My account: This setting allows your connector to globally access everything that you have access to. With a user account, the connector uses an API key and secret to access the Kafka cluster. This option is not recommended for production.
Service account: This setting limits the access for your connector by using a service account. This option is recommended for production.
Use an existing API key: This setting allows you to specify an API key and a secret pair. You can use an existing pair or create a new one. This method is not recommended for production environments.
Note
Freight clusters support only service accounts for Kafka authentication.
Click Continue.
Configure the authentication properties:
Database hostname: The address of the MySQL Server.
Database port: The port number of the MySQL Server.
Database username: The name of the MySQL Server user that has the required authorization.
Database password: The password for the MySQL Server user that has the required authorization.
Database server name: The logical name of the MySQL server cluster. This logical name forms a namespace and is used in all Kafka topic names and Kafka Connect schema names. The logical name is also used for the namespaces of the corresponding Avro schema, if Avro data format is used. Kafka topics must (and will be) created with the prefix
database.server.name. Only alphanumeric characters, underscores, hyphens and dots are allowed.
How should we connect to your database?
SSL mode: The SSL mode to use to connect to your database. The default preferred option establishes an encrypted connection if the server supports secure connections. If the server does not support secure connections, it falls back to an unencrypted connection. The required option establishes an encrypted connection or fails if one cannot be made for any reason.
Click Continue.
Output Kafka record value format: Sets the output Kafka record value format. Valid entries are AVRO, JSON_SR, PROTOBUF, or JSON. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO, JSON_SR, and PROTOBUF.
Output Kafka record key format: Set the output Kafka record key format. Valid values are AVRO, JSON, JSON_SR (JSON Schema), PROTOBUF, or STRING. A valid schema must be available in Confluent Cloud Schema Registry to use a schema-based record format (for example, Avro, JSON_SR, or Protobuf).
Tables included: Enter a comma-separated list of fully-qualified table identifiers for the connector to monitor. By default, the connector monitors all non-system tables. A fully-qualified table name is in the form
schemaName.tableName. This setting cannot be used with Tables excluded.Tables excluded: Enter a comma-separated list of fully-qualified table identifiers for the connector to ignore. A fully-qualified table name is in the form
schemaName.tableName. This setting cannot be used with tables included.
Database details
Databases included: Enter a comma-separated list of fully-qualified database identifiers for the connector to monitor. By default, the connector monitors all databases on the server. A fully-qualified database name is in the form
<database-name>. This setting cannot be used with databases excluded.Databases excluded: Enter a comma-separated list of fully-qualified database identifiers for the connector to ignore. By default, the connector monitors all databases on the server. A fully-qualified database name is in the form
<database-name>. This setting cannot be used with databases included.Connection timezone: Enter a valid time zone ID for the database location and server connection. For more information, see ZoneID.
Show advanced configurations
Schema context: Select a schema context to use for this connector, if using a schema-based data format. This property defaults to the Default context, which configures the connector to use the default schema set up for Schema Registry in your Confluent Cloud environment. A schema context allows you to use separate schemas (like schema sub-registries) tied to topics in different Kafka clusters that share the same Schema Registry environment. For example, if you select a non-default context, a Source connector uses only that schema context to register a schema and a Sink connector uses only that schema context to read from. For more information about setting up a schema context, see What are schema contexts and when should you use them?.
Snapshot mode: Specifies the criteria for performing a database snapshot when the connector starts.
Key Converter Reference Subject Name Strategy: Set the subject reference name strategy for key. Valid entries are DefaultReferenceSubjectNameStrategy or QualifiedReferenceSubjectNameStrategy. Note that the subject reference name strategy can be selected only for PROTOBUF format with the default strategy being DefaultReferenceSubjectNameStrategy.
Signal data collection: Fully-qualified name of the data collection that is used to send signals to the connector. The collection name is of the form
databaseName.tableName. These signals can be used to perform incremental snapshotting.Columns Excluded: Regular expressions matching columns to exclude from change events
Tombstones on delete: Configure whether a tombstone event should be generated after a delete event. The default is
true.
Additional Configs
value.converter.replace.null.with.default: Whether to replace fields that have a default value and that are null to the default value. When set to true, the default value is used, otherwise null is used. Applicable for JSON Converter.
Value Converter Reference Subject Name Strategy: Sets the subject reference name strategy for values. Valid entries are
DefaultReferenceSubjectNameStrategyorQualifiedReferenceSubjectNameStrategy. You can use this strategy only withPROTOBUFformat; the default strategy isDefaultReferenceSubjectNameStrategy.value.converter.schemas.enable: Include schemas within each of the serialized values. Input messages must contain schema and payload fields and may not contain additional fields. For plain JSON data, set this to false. Applicable for JSON Converter.
errors.tolerance: Use this property if you would like to configure the connector’s error handling behavior. WARNING: This property should be used with CAUTION for SOURCE CONNECTORS as it may lead to dataloss. If you set this property to ‘all’, the connector will not fail on errant records, but will instead log them (and send to DLQ for Sink Connectors) and continue processing. If you set this property to ‘none’, the connector task will fail on errant records.
value.converter.ignore.default.for.nullables: When set to true, this property ensures that the corresponding record in Kafka is NULL, instead of showing the default column value. Applicable for AVRO,PROTOBUF and JSON_SR Converters.
Value Converter Decimal Format: Specifies the
JSONorJSON_SRserialization format for ConnectDECIMALlogical type values with two allowed literals:BASE64to serializeDECIMALlogical types as base64 encoded binary data, andNUMERICto serializeDECIMALlogical type values inJSONorJSON_SRas a number representing the decimal value.Key Converter Schema ID Serializer: The class name of the schema ID serializer for keys. This is used to serialize schema IDs in the message headers.
Value Converter Connect Meta Data: Enables the Connect converter to add its metadata to the output schema. Applies to Avro converters.
Value Converter Value Subject Name Strategy: Determines how to construct the subject name under which the value schema is registered with Schema Registry.
Key Converter Key Subject Name Strategy: Determines how to construct the subject name for key schema registration.
Value Converter Schema ID Serializer: The class name of the schema ID serializer for values. This is used to serialize schema IDs in the message headers.
Auto-restart policy
Enable Connector Auto-restart: Enables the auto-restart behavior of the connector and its task in the event of user-actionable errors. Defaults to
true, enabling the connector to automatically restart in case of user-actionable errors. Set this property tofalseto disable auto-restart for failed connectors. If disabled, you must manually restart the connector.
Connection details
Poll interval (ms): Set the time in milliseconds to wait for new change events when no data is returned. Default is
500ms.Max batch size: Enter the maximum number of events the connector batches during each iteration. Defaults to
1000events.Event processing failure handling mode: Specify how the connector reacts to exceptions when processing binlog events. Defaults to
fail. Selectskiporwarnto skip the event or issue a warning, respectively.Heartbeat interval (ms): Set the interval time in milliseconds (ms) between heartbeat messages that the connector sends to a Kafka topic. Defaults to
0, which means the connector does not send heartbeat messages.Skip unparseable DDL: Set this to
trueto have the connector ignore malformed or unknown database statements. Set tofalseto stop processing so these issues can be corrected. Defaults tofalse. Consider setting this totrueto ignore unparseable statements.Event deserialization failure handling mode: Specify how the connector should react to exceptions during deserialization of binlog events.
Inconsistent schema handling mode: Specify how the connector should react to binlog events that belong to a table missing from internal schema representation.
Database details
Snapshot locking mode: Controls how long the connector holds onto the global read lock while it is performing a snapshot. The default is
minimal, which means the connector holds the global read lock (and thus prevents any updates) for just the initial portion of the snapshot, while the database schemas and other metadata are being read. The remaining work in a snapshot involves selecting all rows from each table.Propagate Source Types by Data Type: A comma-separated list of regular expressions matching the database-specific data type names that adds the data type’s original type and original length as parameters to the corresponding field schemas in the emitted change records.
Output messages
After-state only: Defaults to true, which results in the Kafka record having only the record state from change events applied. Select false to maintain the prior record states after applying the change events.
Connector details
Provide transaction metadata: Select whether transaction metadata is enabled. Transaction metadata is stored in a dedicated Kafka topic. Defaults to
false.Decimal handling mode: Specify how
DECIMALandNUMERICcolumns are represented in change events.precise(the default) uses java.math.BigDecimal to represent values. The values are encoded in change events using a binary representation and the Connect org.apache.kafka.connect.data.Decimal data type. Selectstringto use string type to represent values.doublerepresents values using Java’sdoubledata type.doubledoes not provide precision, but is much easier to use in consumers.Binary handling mode: Specify how binary (blob, binary) columns are represented in change events. Select
bytes(the default) to represent binary data in byte array format. Selectbase64to represent binary data in base64-encoded string format. Selecthexto represent binary data in hex-encoded (base16) string format.Time precision mode: Time, date, and timestamps can be represented with different kinds of precision. Select
adaptive(the default) to base the precision for time, date, and timestamp values on the database column’s precision.adaptive_time_microsecondsis essentially the same as adaptive mode, with the exception thatTIMEfields always use microseconds precision.connectalways represents time, date, and timestamp values using Connect’s built-in representations for Time, Date, and Timestamp.connectuses millisecond precision regardless of what precision is used for the database columns. For more information, see Temporal types.BigInt Unsigned handling mode: Specify how BIGINT UNSIGNED columns should be represented in change events.
Topic cleanup policy: Set the topic retention cleanup policy. Select
delete(the default) to discard old topics. Selectcompactto enable log compaction on the topic.Enable time adjuster: Specifies if the year value conversion is adjusted by the connector or delegated to the database.
Store only captured tables DDL: A Boolean value that specifies whether the connector records schema structures from all tables in a schema or database, or only from tables that are designated for capture. Defaults to false. false - During a database snapshot, the connector records the schema data for all non-system tables in the database, including tables that are not designated for capture. It’s best to retain the default setting. If you later decide to capture changes from tables that you did not originally designate for capture, the connector can easily begin to capture data from those tables, because their schema structure is already stored in the schema history topic. true - During a database snapshot, the connector records the table schemas only for the tables from which Debezium captures change events. If you change the default value, and you later configure the connector to capture data from other tables in the database, the connector lacks the schema information that it requires to capture change events from the tables.
Transforms
Single Message Transformations: To add a new SMT, see Add transforms. For more information about unsupported SMTs, see Unsupported transformations.
Processing position
Set offsets: Click Set offsets to define a specific offset for this connector to begin procession data from. For more information on managing offsets, see Manage offsets.
For additional information about the Debezium SMTs ExtractNewRecordState and EventRouter (Debezium), see Debezium transformations.
For all property values and definitions, see Configuration Properties.
Click Continue.
Based on the number of topic partitions you select, you will be provided with a recommended number of tasks.
To change the number of tasks, use the Range Slider to select the desired number of tasks.
Click Continue.
Verify the connection details by previewing the running configuration.
After you’ve validated that the properties are configured to your satisfaction, click Launch.
The status for the connector should go from Provisioning to Running.
Step 5: Check the Kafka topic
After the connector is running, verify that messages are populating your Kafka topic.
Note
A topic named dbhistory.<database.server.name>.<connect-id> is automatically created for database.history.kafka.topic with one partition.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Using the Confluent CLI
Complete the following steps to set up and run the connector using the Confluent CLI.
Note
Make sure you have all your prerequisites completed.
Step 1: List the available connectors
Enter the following command to list available connectors:
confluent connect plugin list
Step 2: List the connector configuration properties
Enter the following command to show the connector configuration properties:
confluent connect plugin describe <connector-plugin-name>
The command output shows the required and optional configuration properties.
Step 3: Create the connector configuration file
Create a JSON file that contains the connector configuration properties. The following example shows the required connector properties.
{
"connector.class": "MySqlCdcSource",
"name": "MySqlCdcSourceConnector_0",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "****************",
"kafka.api.secret": "****************************************************************",
"database.hostname": "database-2.<host-ID>.us-west-2.rds.amazonaws.com",
"database.port": "3306",
"database.user": "admin",
"database.password": "**********",
"database.server.name": "mysql",
"database.whitelist": "employee",
"table.includelist":"employees.departments,
"snapshot.mode": "initial",
"output.data.format": "AVRO",
"tasks.max": "1"
}
Note the following property definitions:
"connector.class": Identifies the connector plugin name."name": Sets a name for your new connector.
"kafka.auth.mode": Identifies the connector authentication mode you want to use. There are two options:SERVICE_ACCOUNTorKAFKA_API_KEY(the default). To use an API key and secret, specify the configuration propertieskafka.api.keyandkafka.api.secret, as shown in the example configuration (above). To use a service account, specify the Resource ID in the propertykafka.service.account.id=<service-account-resource-ID>. To list the available service account resource IDs, use the following command:confluent iam service-account list
For example:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"database.ssl.mode": The default optionpreferis enabled ifdatabase.ssl.modeis not added to the connector configuration. Whenpreferis enabled, the connector attempts to use an encrypted connection to the database server. The optionspreferandrequireuse a secure (encrypted) connection. The connector fails if a secure connection cannot be established. These modes do not do Certification Authority (CA) validation."table.includelist": (Optional) Enter a comma-separated list of fully-qualified table identifiers for the connector to monitor. By default, the connector monitors all non-system tables. A fully-qualified table name is in the formschemaName.tableName."column.exclude.list": (Optional) A comma-separated list of regular expressions that match the fully-qualified names of columns to exclude from change event record values. Fully-qualified names for columns are in the formdatabaseName.tableName.columnName."snapshot.mode": (Optional) Specifies the criteria for performing a database snapshot when the connector starts.The default option is
initial. When selected, the connector takes a snapshot of the structure and data from captured tables. This is useful if you want the topics populated with a complete representation of captured table data when the connector starts.never: Specifies that the connector should never perform snapshots, and that when starting for the first time, the connector starts reading from where it last left off.when_needed: Specifies that the connector performs a snapshot when it considers a snapshot is needed. Note that if the connector cannot find the binlog file mentioned in the offsets, it will take another snapshot and that may lead to duplicate data.schema_only: Specifies that the connector completes a snapshot of the schemas and not the data. This option is useful when you do not need the topics to contain a consistent snapshot of the data, but need them to have only the changes since the connector was started.schema_only_recovery: A recovery option for a connector that has already been capturing changes. When you restart the connector, it recovers a corrupted or lost database history topic. You might use this option periodically to clean up a database history topic that has been growing unexpectedly.
"snapshot.locking.mode": (Optional) Controls how long the connector holds a global read lock as it performs a snapshot. The default isminimal, which means the connector holds the global read lock (preventing any updates) for just the initial portion of the snapshot, while the database schemas and other metadata are being read. The remaining work in a snapshot involves selecting all rows from each table. This is accomplished using aREPEATABLE READtransaction, even when the read lock is off and other operations are updating the database. (Useminimal_perconafor a Percona server.) In some cases it may be desirable to block all writes for the entire duration of the snapshot. In a case like this, set this property toextended. The optionnoneprevents the connector from acquiring any table locks during the snapshot. While this setting is allowed with all snapshot modes, it is safe to use only if no schema changes are happening while the snapshot is running. Note that for tables defined with the MyISAM engine, the tables are locked regardless of this property’s setting, since MyISAM acquires a table lock. This behavior is unlike the InnoDB engine, which acquires row level locks."output.data.format": Sets the output Kafka record value format (data coming from the connector). Valid entries are AVRO, JSON_SR, PROTOBUF, or JSON. You must have Confluent Cloud Schema Registry configured if using a schema-based record format (for example, Avro, JSON_SR (JSON Schema), or Protobuf)."after.state.only": (Optional) Defaults to true, which results in the Kafka record having only the record state from change events applied. Enter false to maintain the prior record states after applying the change events."json.output.decimal.format": (Optional) Defaults to BASE64. Specify the JSON/JSON_SR serialization format for Connect DECIMAL logical type values with two allowed literals:BASE64 to serialize DECIMAL logical types as base64 encoded binary data.
NUMERIC to serialize Connect DECIMAL logical type values in JSON or JSON_SR as a number representing the decimal value.
"signal.data.collection": Fully-qualified name of the data collection that is used to send signals to the connector. The collection name is of the formdatabaseName.tableName. These signals can be used to perform incremental snapshotting."tasks.max": Enter the number of tasks in use by the connector. Organizations can run multiple connectors with a limit of one task per connector (that is,"tasks.max": "1").
SMTs: For details about adding SMTs using the Confluent CLI, see the Single Message Transformations documentation. For additional information about the Debezium SMTs ExtractNewRecordState and EventRouter (Debezium), see Debezium transformations.
See Configuration Properties for all properties and definitions.
Step 4: Load the properties file and create the connector
Enter the following command to load the configuration and start the connector:
confluent connect cluster create --config-file <file-name>.json
For example:
confluent connect cluster create --config-file mysql-cdc-source.json
Example output:
Created connector MySqlCdcSourceConnector_0 lcc-ix4dl
Step 5: Check the connector status
Enter the following command to check the connector status:
confluent connect cluster list
Example output:
ID | Name | Status | Type
+-----------+-----------------------------+---------+-------+
lcc-ix4dl | MySqlCdcSourceConnector_0 | RUNNING | source
Step 6: Check the Kafka topic.
After the connector is running, verify that messages are populating your Kafka topic.
Note
A topic named dbhistory.<database.server.name>.<connect-id> is automatically created for database.history.kafka.topic with one partition.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Configuration Properties
Use the following configuration properties with the fully-managed connector. For self-managed connector property definitions and other details, see the connector docs in Self-managed connectors for Confluent Platform.
How should we connect to your data?
nameSets a name for your connector.
Type: string
Valid Values: A string at most 64 characters long
Importance: high
Kafka Cluster credentials
kafka.auth.modeKafka Authentication mode. It can be one of KAFKA_API_KEY or SERVICE_ACCOUNT. It defaults to KAFKA_API_KEY mode, whenever possible.
Type: string
Valid Values: SERVICE_ACCOUNT, KAFKA_API_KEY
Importance: high
kafka.api.keyKafka API Key. Required when kafka.auth.mode==KAFKA_API_KEY.
Type: password
Importance: high
kafka.service.account.idThe Service Account that will be used to generate the API keys to communicate with Kafka Cluster.
Type: string
Importance: high
kafka.api.secretSecret associated with Kafka API key. Required when kafka.auth.mode==KAFKA_API_KEY.
Type: password
Importance: high
Schema Config
schema.context.nameAdd a schema context name. A schema context represents an independent scope in Schema Registry. It is a separate sub-schema tied to topics in different Kafka clusters that share the same Schema Registry instance. If not used, the connector uses the default schema configured for Schema Registry in your Confluent Cloud environment.
Type: string
Default: default
Importance: medium
How should we connect to your database?
database.hostnameThe address of the MySQL server.
Type: string
Importance: high
database.portPort number of the MySQL server.
Type: int
Valid Values: [0,…,65535]
Importance: high
database.userThe name of the MySQL server user that has the required authorization.
Type: string
Importance: high
database.passwordThe password for the MySQL server user that has the required authorization.
Type: password
Importance: high
database.server.nameThe logical name of the MySQL server cluster. This logical name forms a namespace and is used in all Kafka topic names and Kafka Connect schema names. The logical name is also used for the namespaces of the corresponding Avro schema, if Avro data format is used. Kafka topics must (and will be) created with the prefix
database.server.name. Only alphanumeric characters, underscores, hyphens and dots are allowed.Type: string
Importance: high
database.ssl.modeWhat SSL mode should we use to connect to your database. The default preferred option establishes an encrypted connection if the server supports secure connections. If the server does not support secure connections, it falls back to an unencrypted connection. The required option establishes an encrypted connection or fails if one cannot be made for any reason.
Type: string
Default: preferred
Importance: low
Database details
signal.data.collectionFully-qualified name of the data collection that needs to be used to send signals to the connector. Use the following format to specify the fully-qualified collection name:
databaseName.tableNameType: string
Importance: medium
database.include.listAn optional comma-separated list of strings that match database names to be monitored. Any database name not included in the list is excluded from monitoring. By default all databases are monitored. May not be used with database.exclude.list.
Type: list
Importance: medium
database.exclude.listAn optional comma-separated list of strings that match database names to be excluded from monitoring. Any database name not included in the list is monitored. May not be used with database.include.list.
Type: list
Importance: medium
table.include.listAn optional comma-separated list of strings that match fully-qualified table identifiers for tables to be monitored. Any table not included in this config property is excluded from monitoring. Each identifier is in the form
schemaName.tableName. By default the connector monitors every non-system table in each monitored schema. May not be used with “Table excluded”.Type: list
Importance: medium
database.connectionTimeZoneThe value must be a valid ZoneId.
Type: string
Importance: low
table.exclude.listAn optional comma-separated list of strings that match fully-qualified table identifiers for tables to be excluded from monitoring. Any table not included in this config property is monitored. Each identifier is in the form
schemaName.tableName. May not be used with “Table included”.Type: list
Importance: medium
datatype.propagate.source.typeA comma-separated list of regular expressions matching the database-specific data type names that adds the data type’s original type and original length as parameters to the corresponding field schemas in the emitted change records.
Type: list
Importance: low
snapshot.modeSpecifies the criteria for running a snapshot when the connector starts. The default setting is initial and specifies that the connector can run a snapshot only when no offsets have been recorded for the logical server name. The when_needed option specifies that the connector run a snapshot upon startup whenever necessary; typically when no offsets are available, or when a previously recorded offset specifies a binlog location or GTID that is not available in the server. The never option specifies that the connect should never use snapshots and that when the connector starts with a logical server name, the connector should read from the beginning of the binlog. Use the never option with care, as it is only valid when the binlog is guaranteed to contain the entire history of the database. The schema_only option performs a snapshot of the schemas and not the data. This setting is useful when you do not need the topics to contain a consistent snapshot of the data but need them to have only the changes since the connector was started. The schema_only_recovery option is a recovery setting for a connector that has already been capturing changes. When you restart the connector, this setting enables recovery of a corrupted or lost database history topic. You might set it periodically to “clean up” a database history topic that has been growing unexpectedly. Database history topics require infinite retention.
Type: string
Default: initial
Valid Values: initial, never, schema_only, schema_only_recovery, when_needed
Importance: low
snapshot.locking.modeControls how long the connector holds onto the global read lock while it is performing a snapshot. The default is minimal, which means the connector holds the global read lock (and thus prevents any updates) for just the initial portion of the snapshot, while the database schemas and other metadata are being read. The remaining work in a snapshot involves selecting all rows from each table. This is accomplished using a REPEATABLE READ transaction, even when the lock is no longer held and other operations are updating the database. However, in some cases it may be desirable to block all writes for the entire duration of the snapshot. In this situation, set this property to extended. Using a value of none prevents the connector from acquiring any table locks during the snapshot process. While this setting is allowed with all snapshot modes, it is safe to use if and only if no schema changes are happening while the snapshot is running.
Type: string
Default: minimal
Valid Values: extended, minimal, minimal_percona, none
Importance: low
tombstones.on.deleteControls whether a tombstone event should be generated after a delete event. When set to
true, the delete operations are represented by a delete event and a subsequent tombstone event. When set tofalse, only a delete event is sent. Emitting the tombstone event (the default behavior) allows Kafka to completely delete all events pertaining to the given key, once the source record got deleted.Type: boolean
Default: true
Importance: high
column.exclude.listRegular expressions matching columns to exclude from change events
Type: list
Importance: medium
Connection details
poll.interval.msPositive integer value that specifies the number of milliseconds the connector should wait during each iteration for new change events to appear. Defaults to 1000 milliseconds, or 1 second.
Type: int
Default: 1000 (1 second)
Valid Values: [1,…]
Importance: low
max.batch.sizePositive integer value that specifies the maximum size of each batch of events that should be processed during each iteration of this connector.
Type: int
Default: 1000
Valid Values: [1,…,5000]
Importance: low
event.processing.failure.handling.modeSpecifies how the connector should react to exceptions during processing of binlog events.
Type: string
Default: fail
Valid Values: fail, skip, warn
Importance: low
heartbeat.interval.msControls how frequently the connector sends heartbeat messages to a Kafka topic. The behavior of default value 0 is that the connector does not send heartbeat messages.
Type: int
Default: 0
Valid Values: [0,…]
Importance: low
database.history.skip.unparseable.ddlA Boolean value that specifies whether the connector should ignore malformed or unknown database statements (true), or stop processing so a human can fix the issue (false). Defaults to false. Consider setting this to true to ignore unparseable statements.
Type: boolean
Default: false
Importance: low
event.deserialization.failure.handling.modeSpecifies how the connector should react to exceptions during deserialization of binlog events.
Type: string
Default: fail
Valid Values: fail, skip, warn
Importance: medium
inconsistent.schema.handling.modeSpecifies how the connector should react to binlog events that belong to a table missing from internal schema representation.
Type: string
Default: fail
Valid Values: fail, skip, warn
Importance: medium
Connector details
provide.transaction.metadataStores transaction metadata information in a dedicated topic and enables the transaction metadata extraction together with event counting.
Type: boolean
Default: false
Importance: low
decimal.handling.modeSpecifies how DECIMAL and NUMERIC columns should be represented in change events, including: ‘precise’ (the default) uses java.math.BigDecimal to represent values, which are encoded in the change events using a binary representation and Kafka Connect’s ‘org.apache.kafka.connect.data.Decimal’ type; ‘string’ uses string to represent values; ‘double’ represents values using Java’s ‘double’, which may not offer the precision but will be far easier to use in consumers.
Type: string
Default: precise
Valid Values: double, precise, string
Importance: medium
binary.handling.modeSpecifies how binary (blob, binary, etc.) columns should be represented in change events, including: ‘bytes’ (the default) represents binary data as byte array; ‘base64’ represents binary data as base64-encoded string; ‘hex’ represents binary data as hex-encoded (base16) string.
Type: string
Default: bytes
Valid Values: base64, bytes, hex
Importance: low
time.precision.modeTime, date, and timestamps can be represented with different kinds of precisions, including: ‘adaptive_time_microseconds’ TIME fields always use microseconds precision; ‘connect’ (the default) always represents time, date, and timestamp values using Kafka Connect’s built-in representations for Time, Date, and Timestamp, which uses millisecond precision regardless of the database columns’ precision.
Type: string
Default: connect
Valid Values: adaptive_time_microseconds, connect
Importance: medium
cleanup.policySet the topic cleanup policy
Type: string
Default: delete
Valid Values: compact, delete
Importance: medium
bigint.unsigned.handling.modeSpecifies how BIGINT UNSIGNED columns should be represented in change events.
Type: string
Default: long
Valid Values: long, precise
Importance: medium
enable.time.adjusterSpecifies if the year value conversion is adjusted by the connector or delegated to the database.
Type: boolean
Default: true
Importance: medium
database.history.store.only.captured.tables.ddlA Boolean value that specifies whether the connector records schema structures from all tables in a schema or database, or only from tables that are designated for capture. Defaults to false.
false - During a database snapshot, the connector records the schema data for all non-system tables in the database, including tables that are not designated for capture. It’s best to retain the default setting. If you later decide to capture changes from tables that you did not originally designate for capture, the connector can easily begin to capture data from those tables, because their schema structure is already stored in the schema history topic.
true - During a database snapshot, the connector records the table schemas only for the tables from which Debezium captures change events. If you change the default value, and you later configure the connector to capture data from other tables in the database, the connector lacks the schema information that it requires to capture change events from the tables.
Type: boolean
Default: false
Importance: low
Output messages
output.data.formatSets the output Kafka record value format. Valid entries are AVRO, JSON_SR, PROTOBUF, or JSON. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO, JSON_SR, and PROTOBUF.
Type: string
Default: JSON
Importance: high
output.key.formatSets the output Kafka record key format. Valid entries are AVRO, JSON_SR, PROTOBUF, STRING or JSON. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO, JSON_SR, and PROTOBUF
Type: string
Default: JSON
Valid Values: AVRO, JSON, JSON_SR, PROTOBUF, STRING
Importance: high
after.state.onlyControls whether the generated Kafka record should contain only the state after applying change events.
Type: boolean
Default: true
Importance: low
key.converter.reference.subject.name.strategySet the subject reference name strategy for key. Valid entries are DefaultReferenceSubjectNameStrategy or QualifiedReferenceSubjectNameStrategy. Note that the subject reference name strategy can be selected only for PROTOBUF format with the default strategy being DefaultReferenceSubjectNameStrategy.
Type: string
Default: DefaultReferenceSubjectNameStrategy
Importance: high
Number of tasks for this connector
tasks.maxMaximum number of tasks for the connector.
Type: int
Valid Values: [1,…,1]
Importance: high
Additional Configs
value.converter.connect.meta.dataAllow the Connect converter to add its metadata to the output schema. Applicable for Avro Converters.
Type: boolean
Importance: low
errors.toleranceUse this property if you would like to configure the connector’s error handling behavior. WARNING: This property should be used with CAUTION for SOURCE CONNECTORS as it may lead to dataloss. If you set this property to ‘all’, the connector will not fail on errant records, but will instead log them (and send to DLQ for Sink Connectors) and continue processing. If you set this property to ‘none’, the connector task will fail on errant records.
Type: string
Default: none
Importance: low
key.converter.key.schema.id.serializerThe class name of the schema ID serializer for keys. This is used to serialize schema IDs in the message headers.
Type: string
Default: io.confluent.kafka.serializers.schema.id.PrefixSchemaIdSerializer
Importance: low
key.converter.key.subject.name.strategyHow to construct the subject name for key schema registration.
Type: string
Default: TopicNameStrategy
Importance: low
value.converter.decimal.formatSpecify the JSON/JSON_SR serialization format for Connect DECIMAL logical type values with two allowed literals:
BASE64 to serialize DECIMAL logical types as base64 encoded binary data and
NUMERIC to serialize Connect DECIMAL logical type values in JSON/JSON_SR as a number representing the decimal value.
Type: string
Default: BASE64
Importance: low
value.converter.ignore.default.for.nullablesWhen set to true, this property ensures that the corresponding record in Kafka is NULL, instead of showing the default column value. Applicable for AVRO,PROTOBUF and JSON_SR Converters.
Type: boolean
Default: false
Importance: low
value.converter.reference.subject.name.strategySet the subject reference name strategy for value. Valid entries are DefaultReferenceSubjectNameStrategy or QualifiedReferenceSubjectNameStrategy. Note that the subject reference name strategy can be selected only for PROTOBUF format with the default strategy being DefaultReferenceSubjectNameStrategy.
Type: string
Default: DefaultReferenceSubjectNameStrategy
Importance: low
value.converter.replace.null.with.defaultWhether to replace fields that have a default value and that are null to the default value. When set to true, the default value is used, otherwise null is used. Applicable for JSON Converter.
Type: boolean
Default: true
Importance: low
value.converter.schemas.enableInclude schemas within each of the serialized values. Input messages must contain schema and payload fields and may not contain additional fields. For plain JSON data, set this to false. Applicable for JSON Converter.
Type: boolean
Default: false
Importance: low
value.converter.value.schema.id.serializerThe class name of the schema ID serializer for values. This is used to serialize schema IDs in the message headers.
Type: string
Default: io.confluent.kafka.serializers.schema.id.PrefixSchemaIdSerializer
Importance: low
value.converter.value.subject.name.strategyDetermines how to construct the subject name under which the value schema is registered with Schema Registry.
Type: string
Default: TopicNameStrategy
Importance: low
Auto-restart policy
auto.restart.on.user.errorEnable connector to automatically restart on user-actionable errors.
Type: boolean
Default: true
Importance: medium
Next Steps
For an example that shows fully-managed Confluent Cloud connectors in action with Confluent Cloud for Apache Flink, see the Cloud ETL Demo. This example also shows how to use Confluent CLI to manage your resources in Confluent Cloud.
