
Schemas with Tableflow in Confluent Cloud
Tableflow uses the schema associated with a Kafka topic to materialize that topic into an Apache Iceberg™ table. When a topic is enabled for Tableflow, Tableflow reads the topic’s schema from Schema Registry and applies it to define the structure and format of the resulting Iceberg table. This schema-driven materialization ensures the data is correctly formatted and can be efficiently queried through the Iceberg REST Catalog.
- Type mappings
Table representation of a Kafka topic
It’s important to recognize that Tableflow creates a table representation of a Kafka topic. Tableflow automatically uses the latest schema in Schema Registry to create the associated table schema. Topics and their schemas represent the source of truth for the table representation of the underlying data.
For example, given the following Avro schema in Schema Registry:
{
"fields": [
{
"name": "side",
"type": "string"
},
{
"name": "quantity",
"type": "int"
},
{
"name": "symbol",
"type": "string"
},
{
"name": "price",
"type": "int"
},
{
"name": "account",
"type": "string"
},
{
"name": "userid",
"type": "string"
}
],
"name": "StockTrade",
"type": "record"
}
Tableflow generates the following table DDL:
CREATE TABLE cluster-id.topic_name (
key binary,
side string,
quantity int,
symbol string,
price int,
account string,
userid string,
);
You can use CREATE TABLE statements in Confluent Cloud for Apache Flink® to generate a table-compatible schema in Schema Registry. For example, the following Flink SQL DDL results in the same Avro schema and table schema shown previously:
CREATE TABLE `environment`.`cluster`.`topicname` (
`key` VARBINARY(2147483647),
`side` STRING,
`quantity` INT,
`symbol` STRING,
`price` INT,
`account` STRING,
`userid` STRING
);
Key schemas
In the default append usage for Tableflow, key schemas act as additional fields in the table definition.
For example, given the following KEY and VALUE schema:
{
"fields": [
{
"name": "userid",
"type": "int"
}
],
"name": "tableflowschema_key",
"namespace": "org.apache.flink.avro.generated.record",
"type": "record"
}
{
"fields": [
{
"default": null,
"name": "textbox",
"type": [
"null",
"string"
]
}
],
"name": "tableflowschema_value",
"namespace": "org.apache.flink.avro.generated.record",
"type": "record"
}
Tableflow generates the following table DDL:
CREATE TABLE cluster-id.topicname (
userid int,
textbox string
);
Message headers
Tableflow syncs the data from the Kafka message value and key, and if the Kafka message includes a header, Tableflow syncs the data from the header as well.
Tableflow sends headers as MAP<VARCHAR(2147483647), VARBINARY(2147483647)>. You can use Flink SQL functions to extract specific fields and cast them to the types you want. Also, you can use Flink to do preprocessing by running a continuous query that extracts values from headers and inserts them into regular table columns of a new topic.
Schema compatibility and evolution
Tableflow supports schema evolution by using Confluent Schema Registry as the source of truth. You can define schemas and set compatibility modes within the Schema Registry. When evolving event schemas for Kafka topics, schemas must adhere to the defined compatibility rules.
Consumers of tables materialized by Tableflow can access them only in read-only mode, meaning consumers can query the data but can’t modify the schema. Schema evolution is managed at the Kafka event level and validated through Schema Registry before being applied during materialization. Tableflow enforces schema consistency, ensuring that any changes originate from the data source and adhere to predefined evolution rules.
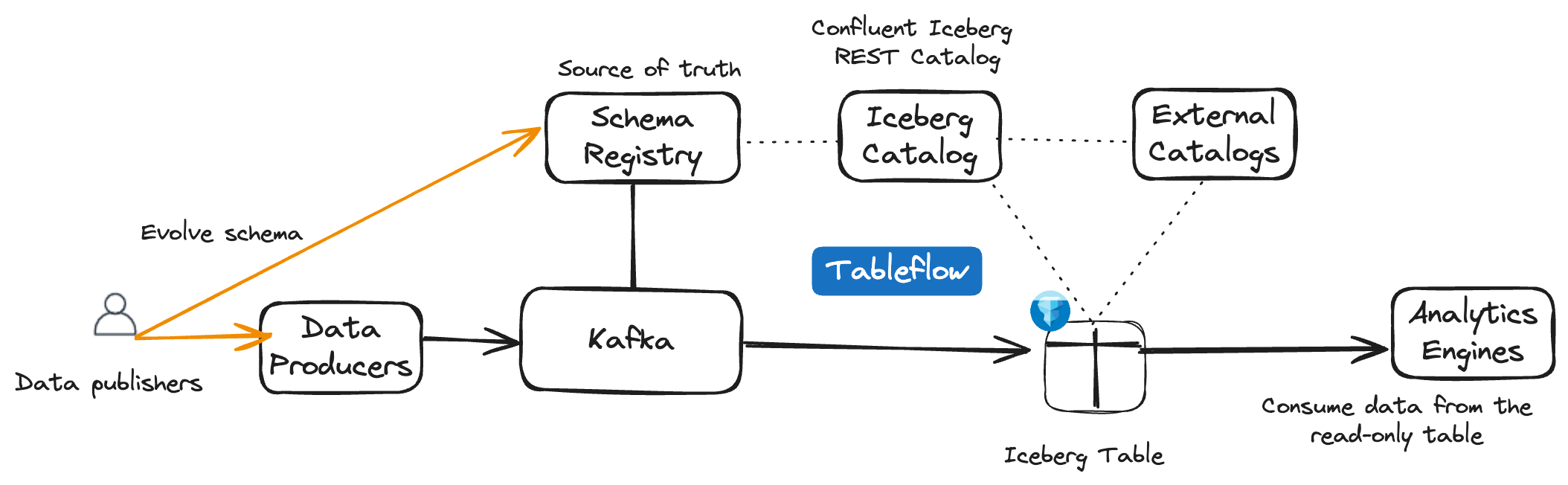
Tableflow validates schema changes against the Schema Registry during table materialization to ensure compliance. If Tableflow encounters data that doesn’t conform to the specified schema evolution rules, it suspends materialization for the affected topic.
When Tableflow is enabled on an existing topic, it utilizes the current schema and materializes the data from the beginning of the log. For this, Tableflow must be able to read the source topic from the beginning.
Supported schema evolutions
Tableflow supports backward-transitive evolution that allows the following schema changes.
When you add a new column, you must make it optional and provide a default value of
nullto ensure backward compatibility with data produced by older schema versions.When using backward-transitive compatibility, adding default values other than
nullis not supported.The following code example shows an optional field.
{ "name": "phoneNumber", "type": ["null", "string"], "default": null, "doc": "The user's phone number (Optional)" }
Type widening for the following types.
inttolongfloattodoubleDecimalprecision increase
Evolving the schema by changing compatibility mode to none is not recommended, unless the evolutions are backward compatible and are supported by Tableflow.
Using schemas without Schema Registry serializers
Tableflow supports cases in which there is a schema in Schema Registry using a TopicNameStrategy but the data has not been serialized with a Schema Registry serializer. This means there is no magic byte present in the Kafka message. This enables retroactively applying schema to a topic without requiring application changes. The data must still be serialized in the same format as the schema in Schema Registry, which means that if the Kafka data is serialized in Avro format, you must use an Avro schema in Schema Registry.
The following example shows how to accomplish this.
Example: Enable Tableflow without using a Schema Registry Serializer
Suppose you have published data that is serialized using the following Avro schema.
// Product.svsc
{
"type": "record",
"name": "Product",
"namespace": "com.example",
"fields": [
{ "name": "id", "type": "int" },
{ "name": "name", "type": "string" },
{ "name": "description", "type": "string" }
]
}
The following example Java producer code publishes Avro-serialized data using the provided schema but does not rely on Schema Registry.
Properties props = new Properties();
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArraySerializer");
...
// Create and serialize an Avro Product instance
Product product = new Product(1, "Product-1", "Description for Product-1");
byte[] avroBytes;
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
BinaryEncoder encoder = EncoderFactory.get().binaryEncoder(outputStream, null);
DatumWriter<Product> writer = new SpecificDatumWriter<>(Product.class);
writer.write(product, encoder);
encoder.flush();
avroBytes = outputStream.toByteArray();
} catch (IOException e) {
throw new RuntimeException("Serialization error: " + e.getMessage(), e);
}
// Publish the message
ProducerRecord<String, byte[]> record = new ProducerRecord<>(topic, String.valueOf(product.getId()), avroBytes);
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("Sent: " + product.getName() + " -> Topic: " + metadata.topic() + " Offset: " + metadata.offset());
} else {
exception.printStackTrace();
}
});
producer.flush();
producer.close();
Once you publish data to this topic, to enable Tableflow, follow these steps.
In Confluent Cloud Console, navigate to the topic that has data serialized using the previous Avro schema. Click Enable Tableflow, and you are prompted to create a schema.
Create a new schema using the same format as the data serialized in this topic, ensuring it matches the correct schema type, which in this example is Avro.
Continue with the next steps and enable Tableflow on the topic. Tableflow can now materialize the data using the configured schema.
Using Tableflow with topics containing multiple event types
Tableflow supports topics that include multiple event types within a single topic that uses TopicNameStrategy. Tableflow takes a Kafka topic that carries multiple event types with different schemas and normalizes them automatically into a single, unified table, where each event type is represented as its own structured column for easy querying and analysis.
Tableflow doesn’t support topics that contain data published with RecordNameStrategy.
Here are the key ways of using topics with multiple event types in Tableflow.
Using schema references
Schema references enable you to manage event types within a single topic by setting up a primary schema that points to other schemas.
The following example shows how to use schema references with Tableflow. It uses a topic that integrates Purchase and Pageview events.
Schema of Purchase events
{
"type":"record",
"namespace": "io.confluent.developer.avro",
"name":"Purchase",
"fields": [
{"name": "item", "type":"string"},
{"name": "amount", "type": "double"},
{"name": "customer_id", "type": "string"}
]
}
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Purchase",
"type": "object",
"properties": {
"item": {
"type": "string"
},
"amount": {
"type": "number"
},
"customer_id": {
"type": "string"
}
},
"required": ["item", "amount", "customer_id"]
}
syntax = "proto3";
package io.confluent.developer.proto;
message Purchase {
string item = 1;
double amount = 2;
string customer_id = 3;
}
Schema of Pageview events
{
"type":"record",
"namespace": "io.confluent.developer.avro",
"name":"Pageview",
"fields": [
{"name": "url", "type":"string"},
{"name": "is_special", "type": "boolean"},
{"name": "customer_id", "type": "string"}
]
}
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Pageview",
"type": "object",
"properties": {
"url": {
"type": "string"
},
"is_special": {
"type": "boolean"
},
"customer_id": {
"type": "string"
}
},
"required": ["url", "is_special", "customer_id"]
}
syntax = "proto3";
package io.confluent.developer.proto;
message Pageview {
string url = 1;
bool is_special = 2;
string customer_id = 3;
}
Combined schema that references both event types
[
"io.confluent.developer.avro.Purchase",
"io.confluent.developer.avro.Pageview"
]
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "CustomerEvent",
"type": "object",
"oneOf": [
{ "$ref": "io.confluent.developer.json.Purchase" },
{ "$ref": "io.confluent.developer.json.Pageview" }
]
}
syntax = "proto3";
package io.confluent.developer.proto;
import "purchase.proto";
import "pageview.proto";
message CustomerEvent {
oneof action {
Purchase purchase = 1;
Pageview pageview = 2;
}
}
Using union types
You can also use union types to expose a Kafka topic with multiple event types as a table using Tableflow. This approach enables every event type to be defined within a single schema by leveraging the native union type features provided by each format.
Avro unions
JSON Schema
oneOfProtocol Buffer
oneof
Example union types
{
"type": "record",
"namespace": "io.confluent.examples.avro",
"name": "AllTypes",
"fields": [
{
"name": "event_type",
"type": [
{
"type": "record",
"name": "Order",
"fields": [
{"name": "order_id", "type": "string"},
{"name": "amount", "type": "double"}
]
},
{
"type": "record",
"name": "Shipment",
"fields": [
{"name": "tracking_id", "type": "string"},
{"name": "status", "type": "string"}
]
}
]
}
]
}
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "AllTypes",
"type": "object",
"oneOf": [
{
"type": "object",
"title": "Order",
"properties": {
"order_id": { "type": "string" },
"amount": { "type": "number" }
},
"required": ["order_id", "amount"]
},
{
"type": "object",
"title": "Shipment",
"properties": {
"tracking_id": { "type": "string" },
"status": { "type": "string" }
},
"required": ["tracking_id", "status"]
}
]
}
syntax = "proto3";
package io.confluent.examples.proto;
message Order {
string order_id = 1;
double amount = 2;
}
message Shipment {
string tracking_id = 1;
string status = 2;
}
message AllTypes {
oneof event_type {
Order order = 1;
Shipment shipment = 2;
}
}
Querying Tableflow tables with multiple event types
You can query the struct columns directly, or later create table views in your data warehouse or lakehouse to flatten them into standard columns for use in downstream tools.

Tableflow with multiple event types
Schema limitations with Tableflow
Schema strategy: Only
TopicNameStrategyis supported.No schema changes are allowed for keys.
Dropping columns is not supported.
Conditional schemas are not supported.
Cyclic schemas are not supported.
Adding new nested fields to an existing schema is not supported.
Avro specific limitations:
Tableflow does not support the
enumtype. An Enum is parsed as astring.Tableflow does not support
timestamp-micros. This type is parsed asbigint/long.Tableflow does not support
uuid. This type is parsed asstring.Tableflow does not support
duration. This type is parsed asbinary/fixed.union(null, type)becomesnullable(type).union(type1,type2,...)becomesrow(type1, type2, ...).Tableflow does not support raw union schema, for example,
{["string", "int"]}Tableflow does not support multiset schemas.
JSON specific limitations:
Tableflow does not support
AllOforAnyOfschemas.If then elseschemas are not supported.NullSchemais not supported.Schemas with extra records outside of the schema may throw a null pointer exception or a cast exception in the deserializer.
For example, if you have fields
a,b, andc, and you submit a record witha = 1, random field = null,random fieldis interpreted asb, and ifbisn’t nullable, an exception is thrown. The Kafka serializer permits this record to be written.JSON Schema does not preserve the declaration order of fields. Tableflow orders fields in alphabetical order because it requires a deterministic order of fields. You can define the field order by using the
connect.indexproperty in the schema, for example:"fields": [ { "name": "field1", "type": "string", "connect.index": 7 } ]
Avro schema type mapping
The following sections describe all of the Avro types that are supported by Tableflow in Confluent Cloud. They include primitives, complex types, logical types, Connect types and types supported by Confluent Cloud for Apache Flink.
For an Avro schema registered in Schema Registry, the root type must always be a record.
Avro primitive types
The following section describes Tableflow support for materializing primitive types.
Avro types are shown with corresponding Iceberg types and example Avro schemas.
boolean
Iceberg type: int
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "boolean" }
bytes
Iceberg type: binary
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "bytes" }
double
Iceberg type: double
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "double" }
fixed
Iceberg type: fixed
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "fixed" }
float
Iceberg type: float
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "float" }
int
Iceberg type: int
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "int" }
string
Iceberg type: string
Support status: Supported
- Example Avro schema
{ "name" : "column0", "type" : "string" }
Avro logical types
The following section describes Tableflow support for materializing Avro logical types.
Avro types are shown with corresponding Iceberg types and example Avro schemas.
date
Iceberg type: date
Support status: Supported
- Value range
min = -2147483648 (Integer.MIN_VALUE)
max = 2147483647 (Integer.MAX_VALUE)
The date type represents the number of days from the unix epoch, 1 January 1970.
- Example Avro schema
{ "name": "column0", "type": { "type": "int", "logicalType": "date" } }
decimal
Iceberg type: decimal
Support status: Supported
- Value range
min = -10 (precision-scale) + 1
max = 10 (precision-scale) − 1
- Additional properties
precision (required) min value is 1
precision (required) max value is 38
scale (optional) default value is 0, must be less than or equal to precision
There is no validation to ensure that the required precision property is present in the schema.
The Iceberg
decimaltype can map either to the Avrobytesorfixedlogical types.- Example Avro schema
{ "name": "column0", "type": { "type": "bytes", "logicalType": "decimal", "precision": 12, "scale": 10 } }
{ "name": "column0", "type": { "type": "fixed", "name": "fixedColumn", "namespace": "", "size": 5, "logicalType": "decimal", "precision": 31, "scale": 18 } }
duration
Iceberg type: fixed
Support status: Supported
Even though duration is part of the Avro spec, it is not implemented in the Avro Java libraries, so Tableflow interprets it as a fixed type.
- Example Avro schema
{ "name": "column", "type": { "type": "fixed", "logicalType": "duration", "name" : "fixedColumn", "size": 12 } }
local-timestamp-micros
Iceberg type: timestamp adjustToUTC = false
Support status: Supported
local timestamp (microsecond precision) represents a timestamp in a local timezone. The long value stores the number of microseconds from 1 January 1970 00:00:00.000000.
- Value range
min = 0
max = 9223372036854775807 (Long.MAX_VALUE)
- Additional properties
flink.precision → default/min/max = 6/0/6
flink.precision default value is 6
flink.precision minimum value is 0
flink.precision maximum value is 6
If flink.precision <= 3, the value is interpreted as milliseconds instead of microseconds during Avro-to-row-data conversion.
If flink.precision >=4 and <=6, the value is interpreted as microseconds.
flink.precision > 6 is not supported.
- Example Avro schema
{ "name": "column0", "type": { "type": "long", "logicalType": "local-timestamp-micros", "flink.precision": 5, "flink.version": 1, "arg.properties": { "range": { "min": 0, "max": 9223372036854775807 } } } }
local-timestamp-millis
Iceberg type: timestamp adjustToUTC = false : timestamp without zone
Support status: Supported (millisecond precision not supported)
- Value range
min = -9223372036854775
max = 9223372036854775 (Long.MAX_VALUE/1000)
- Additional properties
flink.precision default value is 3
flink.precision minimum value is 0
flink.precision maximum value is 3
flink.precision > 3 is not supported.
Because this is a millisecond value, there is a chance for long overflow and value to become negative, so accepted values are only within the specified range.
Negative values are supported.
- Example Avro schema
{ "name": "column0", "type": { "type": "long", "logicalType": "local-timestamp-millis", "flink.precision": 2, "flink.version": 1, "arg.properties": { "range": { "min": -9223372036854775, "max": 9223372036854775 } } } }
time-micros
Iceberg type: long
Support status: Supported
- Value range
min = -9223372036854775807
max = 9223372036854775807 (Long.MAX_VALUE)
Flink doesn’t support reading Avro time-micros as a TIME type. Flink supports TIME with precision up to 3. time-micros is read and written as BIGINT.
The flink.precision value has no significance, because the value is interpreted as BIGINT and not TIME.
- Example Avro schema
{ "name": "column0", "type": { "type": "long", "logicalType": "time-micros", "flink.precision": 1, "flink.version": 1, "arg.properties": { "range": { "min": -9223372036854775807, "max": 9223372036854775807 } } } }
time-millis
Iceberg type: time (time of day without date, timezone)
Support status: Supported (millisecond precision not supported, will be microsecond precision)
- Value range
min = 0
max = 86400000 (number of milliseconds in a day)
- Additional properties
flink.precision default value is 3
flink.precision minimum value is 0
flink.precision maximum value is 3
flink.precision > 3 is not supported.
Important
Materialisation occurs even if the value is outside the range, but Iceberg reading will fail and the table will become unusable.
- Example Avro schema
{ "name": "column0", "type": { "type": "int", "logicalType": "time-milllis", "flink.precision": 1, "flink.version": 1, "arg.properties": { "range": { "min": 0, "max": 86400000 } } } }
timestamp-micros
Iceberg type: timestamptz adjustToUTC = true, microsecond precision with timezone
Support status: Supported
Represents a timestamp, with microsecond precision, independent of a particular time zone or calendar. The long stores the number of microseconds from the unix epoch, 1 January 1970 00:00:00.000000 UTC.
- Value range
min = 0
max = 9223372036854775807 (Long.MAX_VALUE)
- Additional properties
flink.precision default value is 6
flink.precision minimum value is 0
flink.precision maximum value is 6
If flink.precision <= 3, the value is interpreted as milliseconds instead of microseconds during Avro-to-row-data conversion.
If flink.precision >=4 and <=6, the value is interpreted as microseconds.
flink.precision > 6 is not supported.
Negative values are not supported.
- Example Avro schema
{ "name": "column0", "type": { "type": "long", "logicalType": "timestamp-micros", "flink.precision": 5, "flink.version": 1, "arg.properties": { "range": { "min": 0, "max": 9223372036854775807 } } } }
timestamp-millis
Iceberg type: timestamptz microsecond precision with timezone
Support status: Supported (millisecond precision not supported)
Represents a timestamp with millisecond precision, independent of a particular time zone or calendar. The long stores the number of milliseconds from the unix epoch, 1 January 1970 00:00:00.000 UTC.
- Value range
min = -9223372036854775
max = 9223372036854775 (Long.MAX_VALUE/1000)
- Additional properties
flink.precision default value is 3
flink.precision minimum value is 0
flink.precision maximum value is 3
flink.precision > 3 is not supported.
Because this is a millisecond value, there is a chance for long overflow and value to become negative, so accepted values are only within the specified range.
Negative values are supported.
- Example Avro schema
{ "name": "column0", "type": { "type": "long", "logicalType": "timestamp-millis", "flink.precision": 2, "flink.version": 1, "arg.properties": { "range": { "min": -9223372036854775, "max": 9223372036854775 } } } }
uuid
Iceberg type: string
Support status: Supported
- Value range
min = 0
max = 86400000 (number of milliseconds in a day)
- Additional properties
flink.maxLength
flink.minLength
flink.maxLength or flink.minLength don’t have any significance, because there is no validation to ensure that string length is within the range.
According to the Avro spec, the string must conform with RFC-4122, but there is no validation to ensure this. Any string value is accepted even if the logical type is uuid.
- Example Avro schema
{ "name": "column0", "type": { "type": "string", "arg.properties": { "regex": "[a-zA-Z]*", "length": { "min": 15, "max": 20 } }, "logicalType": "uuid", "flink.maxLength": 10, "flink.minLength": 5, "flink.version": "1" } }
Avro complex types
The following section describes Tableflow support for materializing Avro complex types.
Avro types are shown with corresponding Iceberg types and example Avro schemas.
array
Iceberg type: list
Support status: Supported
- Example Avro schema
{ "type": "array", "items" : "string", "default": [] }
enum
Iceberg type: string
Support status: Supported
- Example Avro schema
{ "type": "enum", "name": "Suit", "symbols" : ["SPADES", "HEARTS", "DIAMONDS", "CLUBS"] }
fixed
Iceberg type: binary
Support status: Supported
- Additional properties
size: number of bytes per value
- Example Avro schema
{ "type": "fixed", "size": 16, "name": "md5" }
map
Iceberg type: map
Support status: Supported
- Example Avro schema
{ "type": "map", "values" : "long", "default": {} }
record
Iceberg type: struct
Support status: Supported
- Example Avro schema
{ "type": "record", "name": "LongList", "aliases": ["LinkedLongs"], // old name for this "fields" : [ {"name": "value", "type": "long"}, // each element has a long {"name": "next", "type": ["null", "LongList"]} // optional next element ] }
union
Iceberg type: union
Support status: Supported
- Example Avro schema
["null", "string"]
union (general)
Iceberg type: struct
Support status: Supported
- Example Avro schema
[ "long", "string" ]
Confluent-specific types
The following section describes Tableflow support for materializing Connect and Confluent Cloud for Apache Flink types.
Confluent-specific types are shown with corresponding Iceberg types and example Avro schemas.
array
Iceberg type: map
Support status: Supported
- Example schema
{ "type" : "array", "items" : { "type" : "record", "name" : "MapEntry", "namespace" : "io.confluent.connect.avro", "fields" : [ { "name" : "key", "type" : "int" }, { "name" : "value", "type" : "bytes" } ] } }
int8
Iceberg type: int
Support status: Supported
- Additional properties
connect.type
The int8 type is represented as TINYINT in Flink.
- Example schema
{ "name": "column0", "type": { "type": "int", "connect.type": "int8" }
int16
Iceberg type: int
Support status: Not supported
- Additional properties
connect.type
The int16 type is represented as SMALLINT in Flink.
- Example schema
{ "name": "column0", "type": { "type": "int", "connect.type": "int16" }
multiset
Iceberg type: map
Support status: Not supported
- Example schema
{ "type" : "map", "values" : "int", "flink.type" : "multiset", "flink.version" : "1" }
{ "type" : "array", "items" : { "type" : "record", "name" : "MapEntry", "namespace" : "io.confluent.connect.avro", "fields" : [ { "name" : "key", "type" : "long" }, { "name" : "value", "type" : "int" } ] }, "flink.type" : "multiset", "flink.version" : "1" }
JSON Schema type mapping
The following section describes Tableflow support for materializing JSON Schema types.
JSON Schema types are shown with corresponding Iceberg types and example schemas.
ARRAY
Iceberg type: required list<time>
Support status: Supported
- JSON input schema
"ARRAY": { "type": "array", "items": { "type": "number", "title": "org.apache.kafka.connect.data.Time", "flink.precision": 2, "connect.type": "int32", "flink.version": "1" } }
BIGINT
Iceberg type: required long
Support status: Supported
- JSON input schema
"BIGINT": { "type": "number", "connect.type": "int64" }
BINARY
Iceberg type: required string
Support status: Supported
- JSON input schema
"BINARY": { "type": "string", "connect.type": "bytes", "flink.minLength": 123, "flink.maxLength": 123, "flink.version": "1" }
BOOLEAN
Iceberg type: required boolean
Support status: Supported
- JSON input schema
"BOOLEAN": { "type": "boolean" }
CHAR
Iceberg type: required string
Support status: Supported
- JSON input schema
"CHAR": { "type": "string", "minLength": 123, "maxLength": 123 }
DATE
Iceberg type: optional date
Support status: Supported
- JSON input schema
"DATE": { "type": "number", "connect.type": "int32", "title": "org.apache.kafka.connect.data.Date" }
DECIMAL
Iceberg type: optional decimal(10, 2)
Support status: Supported
- JSON input schema
"DECIMAL": { "type": "number", "connect.type": "bytes", "title": "org.apache.kafka.connect.data.Decimal", "connect.parameters": { "scale": "2" } }
DOUBLE
Iceberg type: required double
Support status: Supported
- JSON input schema
"DOUBLE": { "type": "number", "connect.type": "float64" }
FLOAT
Iceberg type: required float
Support status: Supported
- JSON input schema
"FLOAT": { "type": "number", "connect.type": "float32" }
INT
Iceberg type: required int
Support status: Supported
- JSON input schema
"INT": { "type": "number", "connect.type": "int32" }
MAP_K_V
Iceberg type: required map<int, long>
Support status: Supported
- JSON input schema
"MAP_K_V": { "type": "array", "connect.type": "map", "items": { "type": "object", "properties": { "key": { "type": "number", "connect.type": "int32" }, "value": { "type": "number", "connect.type": "int64" } } } }
MAP_VARCHAR_V
Iceberg type: required map<string, long>
Support status: Supported
- JSON input schema
"MAP_VARCHAR_V": { "type": "object", "connect.type": "map", "additionalProperties": { "type": "number", "connect.type": "int64" } }
MULTISET[K]
Iceberg type: n/a
Support status: Not supported
- JSON input schema
"MULTISET[K]": { "type": "array", "connect.type": "map", "flink.type": "multiset", "items": { "type": "object", "properties": { "value": { "type": "number", "connect.type": "int64" }, "key": { "type": "number", "connect.type": "int32" } } } }
MULTISET[VARCHAR]
Iceberg type: n/a
Support status: Not supported
- JSON input schema
"MULTISET[VARCHAR]": { { "type": "object", "connect.type": "map", "flink.type": "multiset", "additionalProperties": { "type": "number", "connect.type": "int64" } }
NUMBER
Iceberg type: required double
Support status: Supported
- JSON input schema
"NUMBER" : { "type" : "number", "nullable" : true }
ROW
Iceberg type: required struct<36: field1: optional string, 37: field2: optional int, 38: field3: optional boolean>
Support status: Supported
- JSON input schema
"ROW": { "type": "object", "properties": { "field1": { "type": "string" }, "field2": { "type": "number", "connect.type": "int32" }, "field3": { "type": "boolean" } } }
SMALLINT
Iceberg type: required int
Support status: Supported
- JSON input schema
"SMALLINT": { "type": "number", "connect.type": "int16" }
TIME
Iceberg type: optional time
Support status: Supported
- JSON input schema
"TIME": { "type": "number", "title": "org.apache.kafka.connect.data.Time", "flink.precision": 2, "connect.type": "int32", "flink.version": "1" }
TIMESTAMP
Iceberg type: optional timestamp
Support status: Supported
- JSON input schema
"TIMESTAMP": { "type":"number", "flink.precision":2, "flink.type":"timestamp", "connect.type":"int64", "flink.version":"1" }
TIMESTAMP_LTZ
Iceberg type: required timestamptz
Support status: Supported
- JSON input schema
"TIMESTAMP_LTZ": { "type": "number", "title": "org.apache.kafka.connect.data.Timestamp", "flink.precision": 2, "connect.type": "int64", "flink.version": "1" }
TINYINT
Iceberg type: required int
Support status: Supported
- JSON input schema
"TINYINT": { "type": "number", "connect.type": "int8" }
VARBINARY
Iceberg type: required binary
Support status: Supported
- JSON input schema
"VARBINARY": { "type": "string", "connect.type": "bytes", "flink.maxLength": 123, "flink.version": "1" }
VARCHAR
Iceberg type: required string
Support status: Supported
- JSON input schema
"VARCHAR": { "type": "string", "maxLength": 123 }
Protobuf schema type mapping
The following section describes Tableflow support for materializing Protobuf schema types.
Protobuf schema types are shown with corresponding Iceberg types and example Protobuf schemas.
ARRAY
Iceberg type: required list<long>
Support status: Supported
- Protobuf schema
repeated int64 ARRAY = 19;
BOOLEAN
Iceberg type: optional boolean
Support status: Supported
- Protobuf schema
optional bool BOOLEAN = 3;
BIGINT
Iceberg type: optional long
Support status: Supported
- Protobuf schema
optional int64 BIGINT = 1;
BINARY
Iceberg type: optional fixed[6]
Support status: Supported
- Protobuf schema
optional bytes BINARY = 2 [(confluent.field_meta) = { doc: "Example field documentation", params: [ { key: "flink.maxLength", value: "6" }, { key: "flink.minLength", value: "6" }, { key: "flink.version", value: "1" } ] }];
CHAR
Iceberg type: optional string
Support status: Supported
- Protobuf schema
optional string CHAR = 4 [(confluent.field_meta) = { params: [ { key: "flink.version", value: "1" }, { key: "flink.minLength", value: "123" }, { key: "flink.maxLength", value: "123" } ] }];
DATE
Iceberg type: optional date
Support status: Supported
- Protobuf schema
optional .google.type.Date DATE = 5;
DECIMAL
Iceberg type: optional decimal(5, 1)
Support status: Supported
- Protobuf schema
optional .confluent.type.Decimal DECIMAL = 7 [(confluent.field_meta) = { params: [ { key: "flink.version", value: "1" }, { value: "1", key: "scale" }, { value: "5", key: "precision" } ] }];
DOUBLE
Iceberg type: optional double
Support status: Supported
- Protobuf schema
optional double DOUBLE = 6;
FLOAT
Iceberg type: optional float
Support status: Supported
- Protobuf schema
optional float FLOAT = 8;
INT
Iceberg type: optional float
Support status: Supported
- Protobuf schema
optional int32 INT = 9;
MAP_K_V
Iceberg type: required map<string, long>
Support status: Supported
- Protobuf schema
repeated MapEntry MAP_K_V = 10; message MapEntry { option map_entry = true; optional string key = 1; optional int64 value = 2; }
ROW
Iceberg type: optional struct<32: a: optional string, 33: b: optional double>
Support status: Supported
- Protobuf schema
optional meta_Row ROW = 11; message meta_Row { optional string a = 1; optional double b = 2; }
SMALLINT
Iceberg type: optional int
Support status: Supported
- Protobuf schema
optional int32 SMALLINT = 12 [(confluent.field_meta) = { params: [ { key: "flink.version", value: "1" }, { key: "connect.type", value: "int16" } ] }];
TIMESTAMP
Iceberg type: optional timestamp
Support status: Supported
- Protobuf schema
optional .google.protobuf.Timestamp TIMESTAMP = 13 [(confluent.field_meta) = { params: [ { key: "flink.version", value: "1" }, { key: "flink.type", value: "timestamp" }, { key: "flink.precision", value: "3" } ] }];
TIMESTAMP_LTZ
Iceberg type: optional timestamptz
Support status: Supported
- Protobuf schema
optional .google.protobuf.Timestamp TIMESTAMP_LTZ = 14 [(confluent.field_meta) = { params: [ { key: "flink.precision", value: "3" }, { key: "flink.version", value: "1" } ] }];
TIME_WITHOUT_TIME_ZONE
Iceberg type: optional time
Support status: Supported
- Protobuf schema
optional .google.type.TimeOfDay TIME_WITHOUT_TIME_ZONE = 15 [(confluent.field_meta) = { params: [ { key: "flink.precision", value: "3" }, { key: "flink.version", value: "1" } ] }];
TINYINT
Iceberg type: optional binary
Support status: Supported
- Protobuf schema
optional int32 TINYINT = 16 [(confluent.field_meta) = { params: [ { key: "flink.version", value: "1" }, { key: "connect.type", value: "int8" } ] }];
VARCHAR
Iceberg type: optional string
Support status: Supported
- Protobuf schema
optional string VARCHAR = 18 [(confluent.field_meta) = { params: [ { key: "flink.maxLength", value: "123" }, { key: "flink.version", value: "1" } ] }];