
Oracle Database Source (JDBC) Connector for Confluent Cloud
The fully-managed Oracle Database Source connector for Confluent Cloud captures a snapshot of the existing data in an Oracle database, then monitors and records all subsequent row-level changes. The connector supports Avro, JSON Schema, Protobuf, or JSON (schemaless) output data formats. All of the events for each table are recorded in a separate Apache Kafka® topic. The events can then be easily consumed by applications and services. Note that deleted records are not captured.
Note
This Quick Start is for the fully-managed Confluent Cloud connector. If you are installing the connector locally for Confluent Platform, see JDBC Connector (Source and Sink) for Confluent Platform.
If you require private networking for fully-managed connectors, make sure to set up the proper networking beforehand. For more information, see Manage Networking for Confluent Cloud Connectors.
Features
The Oracle Database Source connector provides the following features:
At least once delivery: The connector guarantees that records are delivered at least once to the Kafka topic.
Topics created automatically: The connector automatically creates Kafka topics using the naming convention:
<topic.prefix><tableName>. The tables are created with the properties:topic.creation.default.partitions=1andtopic.creation.default.replication.factor=3.Insert modes:
timestamp mode is enabled when only a timestamp column is specified when you enter database details.
timestamp+incrementing mode is enabled when both a timestamp column and incrementing column are specified when you enter database details.
Important
A timestamp column must not be nullable.
Database authentication: Uses password authentication.
Record processing: Supports table and query modes. Use the
queryproperty to execute custom SQL queries for joining tables or selecting specific data subsets.Data formats: The connector supports Avro, JSON Schema, Protobuf, or JSON (schemaless) output data. Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
Select configuration properties:
db.timezonepoll.interval.msbatch.max.rowstimestamp.delay.interval.mstopic.prefixschema.pattern
Offset management capabilities: Supports offset management. For more information, see Manage custom offsets.
Secret manager integration: The connector supports secret manager integration. For
Passwordbased authentication, the connector can retrieve the following configurations from an integrated secret manager at runtime as needed.Secret manager managed configuration
Type
connection.hostSTRINGconnection.portINTconnection.userSTRINGconnection.passwordPASSWORDFor more information, see Create a secret manager integration in Confluent Cloud.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Limitations
Be sure to review the following information.
For connector limitations, see Oracle Database Source (JDBC) Connector limitations.
If you plan to use one or more Single Message Transformations (SMTs), see SMT Limitations.
Note
Most JSON data that uses precise decimal data represents it as a decimal number with a precision of 38 (e.g., NUMBER(38,0). This is too large for INT64 or FLOAT64. INTEGER is an alias for NUMBER(38) and has the same issue. For this reason, this source connector uses the Connect DECIMAL type. Confluent has an article that goes into greater detail about this subject. See Kafka Connect Deep Dive – JDBC Source connector.
Manage custom offsets
You can manage the offsets for this connector. Offsets provide information on the point in the system from which the connector is accessing data. For more information, see Manage Offsets for Fully-Managed Connectors in Confluent Cloud.
To manage offsets:
Manage offsets using Confluent Cloud APIs. For more information, see Connect offsets API reference.
To get the current offset, make a GET request that specifies the environment, Kafka cluster, and connector name.
GET /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets
Host: https://api.confluent.cloud
Response:
Successful calls return HTTP 200 with a JSON payload that describes the offset.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"protocol": "1",
"table": "{table_name}"
},
"offset": {
"incrementing": 26
}
}
],
"metadata": {
"observed_at": "2024-03-28T17:57:48.139635200Z"
}
}
Responses include the following information:
The position of latest offset.
The observed time of the offset in the metadata portion of the payload. The
observed_attime indicates a snapshot in time for when the API retrieved the offset. A running connector is always updating its offsets. Useobserved_atto get a sense for the gap between real time and the time at which the request was made. By default, offsets are observed every minute. CallingGETrepeatedly will fetch more recently observed offsets.Information about the connector.
In these examples, the curly braces around “{connector_name}” indicate a replaceable value.
To update the offset, make a POST request that specifies the environment, Kafka cluster, and connector name. Include a JSON payload that specifies new offset and a patch type.
POST /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request
Host: https://api.confluent.cloud
{
"type": "PATCH",
"offsets": [
{
"partition": {
"protocol": "1",
"table": "{table_name}"
},
"offset": {
"incrementing": 3
}
}
]
}
Considerations:
You can only make one offset change at a time for a given connector.
This is an asynchronous request. To check the status of this request, you must use the check offset status API. For more information, see Get the status of an offset request.
For source connectors, the connector attempts to read from the position defined by the requested offsets.
Response:
Successful calls return HTTP 202 Accepted with a JSON payload that describes the offset.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"protocol": "1",
"table": "{table_name}"
},
"offset": {
"incrementing": 3
}
}
],
"requested_at": "2024-03-28T17:58:45.606796307Z",
"type": "PATCH"
}
Responses include the following information:
The requested position of the offsets in the source.
The time of the request to update the offset.
Information about the connector.
To delete the offset, make a POST request that specifies the environment, Kafka cluster, and connector name. Include a JSON payload that specifies the delete type.
POST /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request
Host: https://api.confluent.cloud
{
"type": "DELETE"
}
Considerations:
Delete requests delete the offset for the provided partition and reset to the base state. A delete request is as if you created a fresh new connector.
This is an asynchronous request. To check the status of this request, you must use the check offset status API. For more information, see Get the status of an offset request.
Do not issue delete and patch requests at the same time.
For source connectors, the connector attempts to read from the position defined in the base state.
Response:
Successful calls return HTTP 202 Accepted with a JSON payload that describes the result.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [],
"requested_at": "2024-03-28T17:59:45.606796307Z",
"type": "DELETE"
}
Responses include the following information:
Empty offsets.
The time of the request to delete the offset.
Information about Kafka cluster and connector.
The type of request.
To get the status of a previous offset request, make a GET request that specifies the environment, Kafka cluster, and connector name.
GET /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request/status
Host: https://api.confluent.cloud
Considerations:
The status endpoint always shows the status of the most recent PATCH/DELETE operation.
Response:
Successful calls return HTTP 200 with a JSON payload that describes the result. The following is an example of an applied patch.
{
"request": {
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"protocol": "1",
"table": "{table_name}"
},
"offset": {
"incrementing": 3
}
}
],
"requested_at": "2024-03-28T17:58:45.606796307Z",
"type": "PATCH"
},
"status": {
"phase": "APPLIED",
"message": "The Connect framework-managed offsets for this connector have been altered successfully. However, if this connector manages offsets externally, they will need to be manually altered in the system that the connector uses."
},
"previous_offsets": [
{
"partition": {
"protocol": "1",
"table": "{table_name}"
},
"offset": {
"incrementing": 26
}
}
],
"applied_at": "2024-03-28T17:58:48.079141883Z"
}
Responses include the following information:
The original request, including the time it was made.
The status of the request: applied, pending, or failed.
The time you issued the status request.
The previous offsets. These are the offsets that the connector last updated prior to updating the offsets. Use these to try to restore the state of your connector if a patch update causes your connector to fail or to return a connector to its previous state after rolling back.
JDBC modes and offsets
You can run the JDBC source connectors in one of four modes. Each mode uses a different offset object in its JSON payload to track the progress of the connector. The provided samples show an offset object from a JBDC source connector in incrementing mode.
bulk- No offset. This is the default mode for JDBC source connectors.incrementing- The offset is provided by theincrementingproperty in the offset object.timestamp- The offset is provided by thetimestampandtimestamp-nanosproperties in the offset object.timestamp+incrementing- The offset is provided by theincrementing,timestampandtimestamp-nanosproperties in the offset object.
JSON payload
The table below offers a description of the unique fields in the JSON payload for managing offsets of the JDBC Source connectors, including:
IBM Db2 Source connector
Microsoft SQL Server Source connector
MySQL Source connector
Oracle Database Source connector
PostgreSQL Source connector
Field | Definition | Required/Optional |
|---|---|---|
| Specifies the value of Available only in the following modes: incrementing, timestamp+incrementing. | Required |
| Specifies the protocol. Available in the following modes: incrementing, timestamp, timestamp+incrementing. | Required |
| The name of the table. Available in the following modes: incrementing, timestamp, timestamp+incrementing. | Required |
| The number of milliseconds since Available only in the following modes: timestamp, timestamp+incrementing. | Required |
| Fractional seconds component of the timestamp object. Available only in the following modes: timestamp, timestamp+incrementing. | Required |
Quick Start
Use this quick start to get up and running with the Confluent Cloud Oracle Database Source connector. The quick start provides the basics of selecting the connector and configuring it to obtain a snapshot of the existing data in an Oracle database and then monitoring and recording all subsequent row-level changes.
- Prerequisites
Authorized access to a Confluent Cloud cluster on Amazon Web Services (AWS), Microsoft Azure (Azure), or Google Cloud.
The Confluent CLI installed and configured for the cluster. See Install the Confluent CLI.
The connector automatically creates Kafka topics using the naming convention:
<topic.prefix><tableName>. The tables are created with the properties:topic.creation.default.partitions=1andtopic.creation.default.replication.factor=3. If you want to create topics with specific settings, create the topics before running this connector.Important
If you are configuring granular access using a service account, and you leave the optional Topic prefix (
topic.prefix) configuration property empty, you must grant ACLCREATEandWRITEaccess to all the Kafka topics or create RBAC role bindings. To add ACLs, you use the (*) wildcard in the ACL entries as shown in the following examples.confluent kafka acl create --allow --service-account "<service-account-id>" --operation create --topic "*"
confluent kafka acl create --allow --service-account "<service-account-id>" --operation write --topic "*"
The Oracle Database System must be configured with a Pluggable Database (PDB) service name. See Configuring a Multitenant Oracle Database System for instructions for setting this up. This is used for the Database name when configuring the connection to the database.
The Oracle Database version must be 11.2.0.4 or later.
Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
Make sure your connector can reach your service. Consider the following before running the connector:
Depending on the service environment, certain network access limitations may exist. See Manage Networking for Confluent Cloud Connectors for details.
To use a set of public egress IP addresses, see Public Egress IP Addresses for Confluent Cloud Connectors. For additional fully-managed connector networking details, see Networking and DNS.
Do not include
jdbc:xxxx://in the connection hostname property. An example of a connection hostname property isdatabase.example.endpoint.com. For example,mydatabase.abc123ecs2.us-west.rds.amazonaws.com.Clients from Azure Virtual Networks are not allowed to access the server by default. Check that your Azure Virtual Network is correctly configured and that Allow access to Azure Services is enabled.
See your specific cloud platform documentation for how to configure security rules for your VPC.
Kafka cluster credentials. The following lists the different ways you can provide credentials.
Enter an existing service account resource ID.
Create a Confluent Cloud service account for the connector. Make sure to review the ACL entries required in the service account documentation. Some connectors have specific ACL requirements.
Create a Confluent Cloud API key and secret. To create a key and secret, you can use confluent api-key create or you can autogenerate the API key and secret directly in the Cloud Console when setting up the connector.
Using the Confluent Cloud Console
Step 1: Launch your Confluent Cloud cluster
To create and launch a Kafka cluster in Confluent Cloud, see Create a kafka cluster in Confluent Cloud.
Step 2: Add a connector
In the left navigation menu, click Connectors. If you already have connectors in your cluster, click + Add connector.
Step 3: Select your connector
Click the Oracle Database Source connector card.
Step 4: Enter the connector details
Note
Make sure you have all your prerequisites completed.
An asterisk ( * ) designates a required entry.
At the Oracle Database Source Connector screen, complete the following:
In the Topic prefix field, define a topic prefix your connector will use to publish to Kafka topics. The connector will Kafka topics using the following naming convention: <topic.prefix><tableName>.
Important
If you are configuring granular access using a service account, and you leave the optional Topic prefix (topic.prefix) configuration property empty, you must grant ACL CREATE and WRITE access to all the Kafka topics or create RBAC role bindings. To add ACLs, you use the (*) wildcard in the ACL entries as shown in the following examples.
confluent kafka acl create --allow --service-account
"<service-account-id>" --operation create --topic "*"
confluent kafka acl create --allow --service-account
"<service-account-id>" --operation write --topic "*"
Select the way you want to provide Kafka Cluster credentials. You can choose one of the following options:
My account: This setting allows your connector to globally access everything that you have access to. With a user account, the connector uses an API key and secret to access the Kafka cluster. This option is not recommended for production.
Service account: This setting limits the access for your connector by using a service account. This option is recommended for production.
Use an existing API key: This setting allows you to specify an API key and a secret pair. You can use an existing pair or create a new one. This method is not recommended for production environments.
Note
Freight clusters support only service accounts for Kafka authentication.
Click Continue.
Configure the authentication properties:
Authentication method
Authentication method: Select how you want to authenticate with your database. Currently,
Passwordis the only valid authentication method.Use secret manager: Enable this setting to fetch sensitive configuration values, such as the
Password, from a secret manager.
Secret manager configuration
Secret manager: Select the secret manager that Confluent Cloud should use to retrieve sensitive data.
Configurations from Secret manager: Select the configurations whose values Confluent Cloud should fetch from the secret manager.
Provider Integration: Select an existing integration that has access to your resource such as the secret manager.
How should we connect to your database?
Connection host: The JDBC connection host. Do not include
jdbc:xxxx://in the connection hostname property. An example of a connection hostname property isdatabase-1.123abc456ecs2.us-west-2.rds.amazonaws.com. Depending on the service environment, certain network access limitations may exist. For details, see Manage Networking for Confluent Cloud Connectors.Connection port: JDBC connection port for Oracle Database.
Connection user: JDBC connection user for Oracle Database.
Connection password: JDBC connection password Oracle Database.
Database name type: Select database connection using
SIDorSERVICE_NAME. Defaults toSID.Database name: JDBC database name for Oracle Database.
SSL mode: The SSL mode to use to connect to your database. Valid options are
disabled,verify-caorverify-full.Trust store: Upload the trust store file that contains the Certificate Authority (CA) CA information.
Trust store password: The trust store password containing server CA certificate. Only required if using
verify-caorverify-fullSSL mode.Distinguished name (DN) of the database server: Use this parameter to specify the distinguished name (DN) of the database server. Only required if using
verify-fullSSL mode.
Click Continue.
Table names (Deprecated): (Deprecated) List of tables to include in copying. Use a comma-separated list to specify multiple tables (for example, "User, Address, Email"). This is deprecated, please use table.include.list.
Table types: By default, the JDBC connector will only detect tables with type
TABLEfrom the source database. This configuration allows a command separated list of table types to extract.Database timezone: Name of the JDBC timezone used in the connector when querying with time-based criteria. Defaults to
UTC.Table include list: List of tables to include in copying. Use a comma-separated list of regular expressions or fully-qualified table names to specify multiple tables (for example,
HR.EMPLOYEES, HR.DEPARTMENTSor.*users.*, .*orders.*). For Oracle, use schema.table format and do not include database name in the fully-qualified name (for example,HR.EMPLOYEES).Table exclude list: A comma-separated list of regular expressions that match the fully-qualified names of tables to be excluded from copying. Use a comma-separated list to specify multiple regular expressions. Table names are case-sensitive. For example,
table.exclude.list: schema1.customer.*,schema2.order.*. If specified,table.whitelistcannot not be set.”
Output messages
Select output record value format: Select the output record value format (data going to the Kafka topic): AVRO, JSON, JSON_SR (JSON Schema), or PROTOBUF. Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON Schema, or Protobuf).
Show advanced configurations
Schema context: Select a schema context to use for this connector, if using a schema-based data format. This property defaults to the Default context, which configures the connector to use the default schema set up for Schema Registry in your Confluent Cloud environment. A schema context allows you to use separate schemas (like schema sub-registries) tied to topics in different Kafka clusters that share the same Schema Registry environment. For example, if you select a non-default context, a Source connector uses only that schema context to register a schema and a Sink connector uses only that schema context to read from. For more information about setting up a schema context, see What are schema contexts and when should you use them?.
Mode: The mode for updating a table each time it is polled. Defaults to
bulkmode.Table to timestamp columns mappings: A comma-separated list of table regex to timestamp columns mappings. On specifying multiple timestamp columns, COALESCE SQL function would be used to find out the effective timestamp for a row. Expected format is
regex1:[col1|col2],regex2:[col3]. Regexes would be matched against the fully-qualified table names. Identifier names are case sensitive. Every table included for capture should match exactly one of the provided mappings. An example for a valid input would be.*\.customers.*:[updated_at|modified_at],.*\.orders.*:[changed_at].Numeric Mapping: Map NUMERIC values by precision and optionally scale to integral or decimal types.
Table to incrementing column mappings: A comma-separated list of table regex to incrementing column mappings. Expected format is
regex1:col1,regex2:col2. Regexes would be matched against the fully-qualified table names. Identifier names are case sensitive. Every table included for capture should match exactly one of the provided mappings. An example for a valid input would be.*\.customers.*:id,.*\.orders.*:order_id.Schema pattern: Schema pattern to fetch table metadata from the database.
Quote SQL Identifiers: When to quote table names, column names, and other identifiers in SQL statements. For backward compatibility, the default value is
ALWAYS.Timestamp column name (Deprecated): (Deprecated legacy configuration. Use timestamp.columns.mapping for new implementations.) Comma-separated list of one or more timestamp columns to detect new or modified rows using the COALESCE SQL function. Rows whose first non-null timestamp value is greater than the largest previous timestamp value seen will be discovered with each poll. At least one column should not be nullable.
Initial timestamp: The epoch timestamp used for initial queries that use timestamp criteria. The value -1 sets the initial timestamp to the current time. If not specified, the connector retrieves all data. Once the connector has managed to successfully record a source offset, this property has no effect even if changed to a different value later on.
Date Calendar System: The time elapsed from epoch populated in the end table topic for DATE or TIMESTAMP type columns can have two different values based upon the Calendar used to interpret it. If LEGACY is used, it will use the hybrid Gregorian/Julian calendar which was the default in the older java date time APIs. However, if ‘PROLEPTIC_GREGORIAN’ is used, then it will use the proleptic gregorian calendar which extends the Gregorian rules backward indefinitely and does not apply the 1582 cutover. This matches the behavior of modern Java date/time APIs (java.time). This is defaulted to LEGACY for backward compatibility. Changing this configuration on an existing connector might lead to a drift in the Kafka topic record values.
Incrementing column name (Deprecated): (deprecated) The name of the strictly incrementing column to use to detect new rows. Any empty value indicates the column should be autodetected by looking for an auto-incrementing column. This column may not be nullable.
Note
This configuration is deprecated. Use incrementing column mapping instead of incrementing column name.
Transaction Isolation Level: Isolation level determines how transaction integrity is visible to other users and systems.
DEFAULTis the default isolation level configured at the database server.READ_UNCOMMITTEDis the lowest isolation level. At this level, a transaction may see changes that are not committed (that is, dirty reads) made by other transactions.READ_COMMITTEDguarantees that any data read is already committed at the moment it is read.REPEATABLE_READadds to the guarantees of theREAD_COMMITTEDlevel with the addition of also guaranteeing that any data read cannot change, if the transaction reads the same data again. However, phantom reads are possible.SERIALIZABLEis the highest isolation level. In addition to everythingREPEATABLE_READguarantees,SERIALIZABLEalso eliminates phantom reads.Timestamp granularity for timestamp columns: Defines the granularity of the Timestamp column.
CONNECT_LOGICAL(default) represents timestamp values using Connect’s built-in representations.NANOS_LONGrepresents timestamp values as nanoseconds (ns) since the epoch (UNIX epoch time).NANOS_STRINGrepresents timestamp values as ns since the epoch in string format.NANOS_ISO_DATETIME_STRINGrepresents timestamp values in ISO formatyyyy-MM-dd'T'HH:mm:ss.n.Poll interval (ms): Set the time in milliseconds to wait for new change events when no data is returned. Default is
500ms.Max rows per batch: The maximum number of rows to include in a single batch when polling for new data. This setting can be used to limit the amount of data buffered internally in the connector.
Delay interval (ms): The amount of time to wait after a row with a certain timestamp appears before we include it in the result. You may choose to add some delay to allow transactions with an earlier timestamp to complete.
Additional Configs
Value Converter Replace Null With Default: Specifies whether to replace fields that have a default value and that are null to the default value. When set to
true, the connector uses the default value; otherwise, it usesnull. Applies to theJSONconverter.Value Converter Reference Subject Name Strategy: Sets the subject reference name strategy for values. Valid entries are
DefaultReferenceSubjectNameStrategyorQualifiedReferenceSubjectNameStrategy. You can use this strategy only withPROTOBUFformat; the default strategy isDefaultReferenceSubjectNameStrategy.Value Converter Schemas Enable: Includes schema within each of the serialized values. Input messages must contain
schemaandpayloadfields and must not contain additional fields. For plainJSONdata, set this tofalse. Applies to theJSONconverter.Errors Tolerance: Use this property to configure the connector’s error handling behavior.
Warning
Use this property with caution for sink connectors, as it can lead to data loss. If you set this property to
all, the connector does not fail on errant records, but logs them (and sends to DLQ for sink connectors) and continues processing. If you set this property tonone, the connector task fails on errant records.Value Converter Ignore Default For Nullables: When set to
true, this property ensures that the corresponding record in Kafka isnull, instead of showing the default column value. Applies to theAVRO,PROTOBUF, andJSON_SRconverters.Value Converter Decimal Format: Specifies the
JSONorJSON_SRserialization format for ConnectDECIMALlogical type values with two allowed literals:BASE64to serializeDECIMALlogical types as base64 encoded binary data, andNUMERICto serializeDECIMALlogical type values inJSONorJSON_SRas a number representing the decimal value.Key Converter Schema ID Serializer: The class name of the schema ID serializer for keys. This is used to serialize schema IDs in the message headers.
Value Converter Connect Meta Data: Enables the Connect converter to add its metadata to the output schema. Applies to Avro converters.
Value Converter Value Subject Name Strategy: Determines how to construct the subject name under which the value schema is registered with Schema Registry.
Key Converter Key Subject Name Strategy: Determines how to construct the subject name for key schema registration.
Value Converter Schema ID Serializer: The class name of the schema ID serializer for values. This is used to serialize schema IDs in the message headers.
Auto-restart policy
Enable Connector Auto-restart: Enables the auto-restart behavior of the connector and its task in the event of user-actionable errors. Defaults to
true, enabling the connector to automatically restart in case of user-actionable errors. Set this property tofalseto disable auto-restart for failed connectors. If disabled, you must manually restart the connector.
Database details
Query Config: If specified, the connector uses this custom SQL query to read source records, which allows for operations like joining tables or selecting subsets of data. Providing a query instructs the connector to read only the result set instead of performing a full table copy. This configuration supports different query modes with the incremental query properly constructed by appending a
WHEREclause (for more information, see Incremental Query Modes). Note that onlySELECTstatements are supported. Always adhere to security best practices, like enforcing strict authorization using managed connector RBAC, applying appropriate network access controls for control plane APIs, and following the principle of least privilege when provisioning identities or credentials for any third-party systems.
Transforms
Single Message Transformations: To add a new SMT, see Add transforms. For more information about unsupported SMTs, see Unsupported transformations.
Processing position
Set offsets: Click Set offsets to define a specific offset for this connector to begin procession data from. For more information on managing offsets, see Manage offsets.
For all property values and definitions, see Configuration Properties.
Click Continue.
Based on the number of topic partitions you select, you will be provided with a recommended number of tasks.
To change the number of tasks, use the Range Slider to select the desired number of tasks.
Click Continue.
Verify the connection details by previewing the running configuration.
Tip
For information about previewing your connector output, see Data Previews for Confluent Cloud Connectors.
After you’ve validated that the properties are configured to your satisfaction, click Launch.
The status for the connector should go from Provisioning to Running.

Step 5: Check the Kafka topic
After the connector is running, verify that messages are populating your Kafka topic.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Using the Confluent CLI
Complete the following steps to set up and run the connector using the Confluent CLI.
Note
Make sure you have all your prerequisites completed.
Step 1: List the available connectors
Enter the following command to list available connectors:
confluent connect plugin list
Step 2: List the connector configuration properties
Enter the following command to show the connector configuration properties:
confluent connect plugin describe <connector-plugin-name>
The command output shows the required and optional configuration properties.
Step 3: Create the connector configuration file
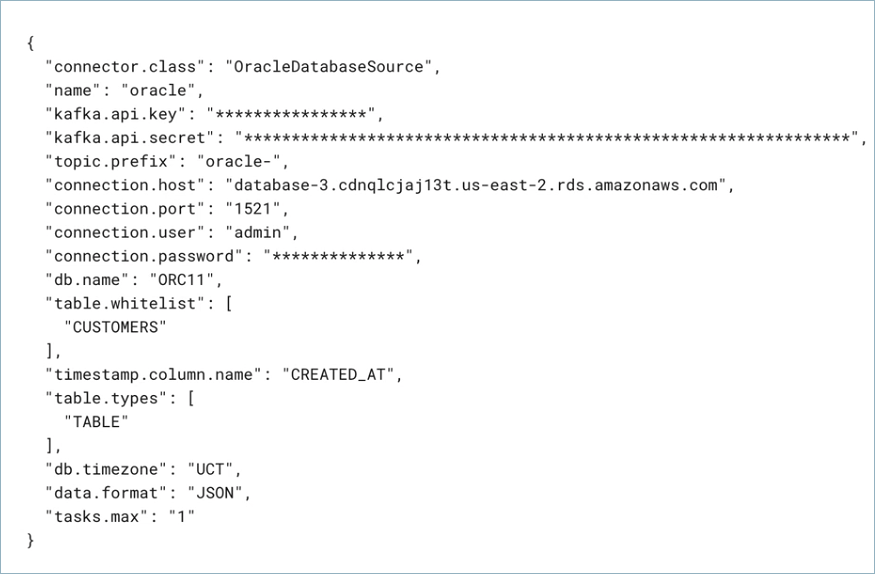
Create a JSON file that contains the connector configuration properties. The following example shows the required connector properties.
{
"name" : "OracleDatabaseSource_0",
"connector.class": "OracleDatabaseSource",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key>",
"kafka.api.secret" : "<my-kafka-api-secret>",
"topic.prefix" : "oracle_",
"connection.host" : "<my-database-endpoint>",
"connection.port" : "1521",
"connection.user" : "<database-username>",
"connection.password": "<database-password>",
"db.name": "db078_pdb1.subnet.vcn.oraclevcn.com",
"table.include.list": ".*PASSENGERS.*",
"timestamp.columns.mapping": ".*PASSENGERS.*:[created_at]",
"output.data.format": "JSON",
"db.timezone": "UTC",
"tasks.max" : "1"
}
Note the following property definitions:
"name": Sets a name for your new connector."connector.class": Identifies the connector plugin name.
"kafka.auth.mode": Identifies the connector authentication mode you want to use. There are two options:SERVICE_ACCOUNTorKAFKA_API_KEY(the default). To use an API key and secret, specify the configuration propertieskafka.api.keyandkafka.api.secret, as shown in the example configuration (above). To use a service account, specify the Resource ID in the propertykafka.service.account.id=<service-account-resource-ID>. To list the available service account resource IDs, use the following command:confluent iam service-account list
For example:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"topic.prefix": Enter a topic prefix. The connector automatically creates Kafka topics using the naming convention:<topic.prefix><tableName>. The tables are created with the properties:topic.creation.default.partitions=1andtopic.creation.default.replication.factor=3. If you want to create topics with specific settings, create the topics before running this connector. If you are configuring granular access using a service account, you must set up ACLs for the topic prefix.Important
If you are configuring granular access using a service account, and you leave the optional Topic prefix (
topic.prefix) configuration property empty, you must grant ACLCREATEandWRITEaccess to all the Kafka topics or create RBAC role bindings. To add ACLs, you use the (*) wildcard in the ACL entries as shown in the following examples.confluent kafka acl create --allow --service-account "<service-account-id>" --operation create --topic "*"
confluent kafka acl create --allow --service-account "<service-account-id>" --operation write --topic "*"
"output.data.format": Sets the output Kafka record value format (data coming from the connector). Valid entries are AVRO, JSON_SR, PROTOBUF, JSON, or STRING. You must have Confluent Cloud Schema Registry configured if using a schema-based message format (for example, Avro, JSON_SR (JSON Schema), or Protobuf)."db.timezone": Identifies the database timezone. This can be any valid database timezone. The default is UTC. For more information, see this list of database timezones.
SMTs: For details about adding SMTs using the Confluent CLI, see the Single Message Transformations documentation.
See Configuration Properties for all properties and definitions.
Step 4: Load the properties file and create the connector
Enter the following command to load the configuration and start the connector:
confluent connect cluster create --config-file <file-name>.json
For example:
confluent connect cluster create --config-file oracle-source.json
Example output:
Created connector OracleDatabaseSource_0 lcc-ix4dl
Step 5: Check the connector status
Enter the following command to check the connector status:
confluent connect cluster list
Example output:
ID | Name | Status | Type
+-----------+-------------------------+---------+-------+
lcc-ix4dl | OracleDatabaseSource_0 | RUNNING | source
Step 6: Check the Kafka topic.
After the connector is running, verify that messages are populating your Kafka topic.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Configuring a Multitenant Oracle Database System
Multitenancy is a standard feature for Oracle database systems, beginning with Oracle Database version 12c. Multitenancy provides a Container Database (CDB) that houses the system information and Pluggable Databases (PDBs) that house your application data and tables.
The following example OCI DB Systems screen shows the environment configuration used in this procedure.
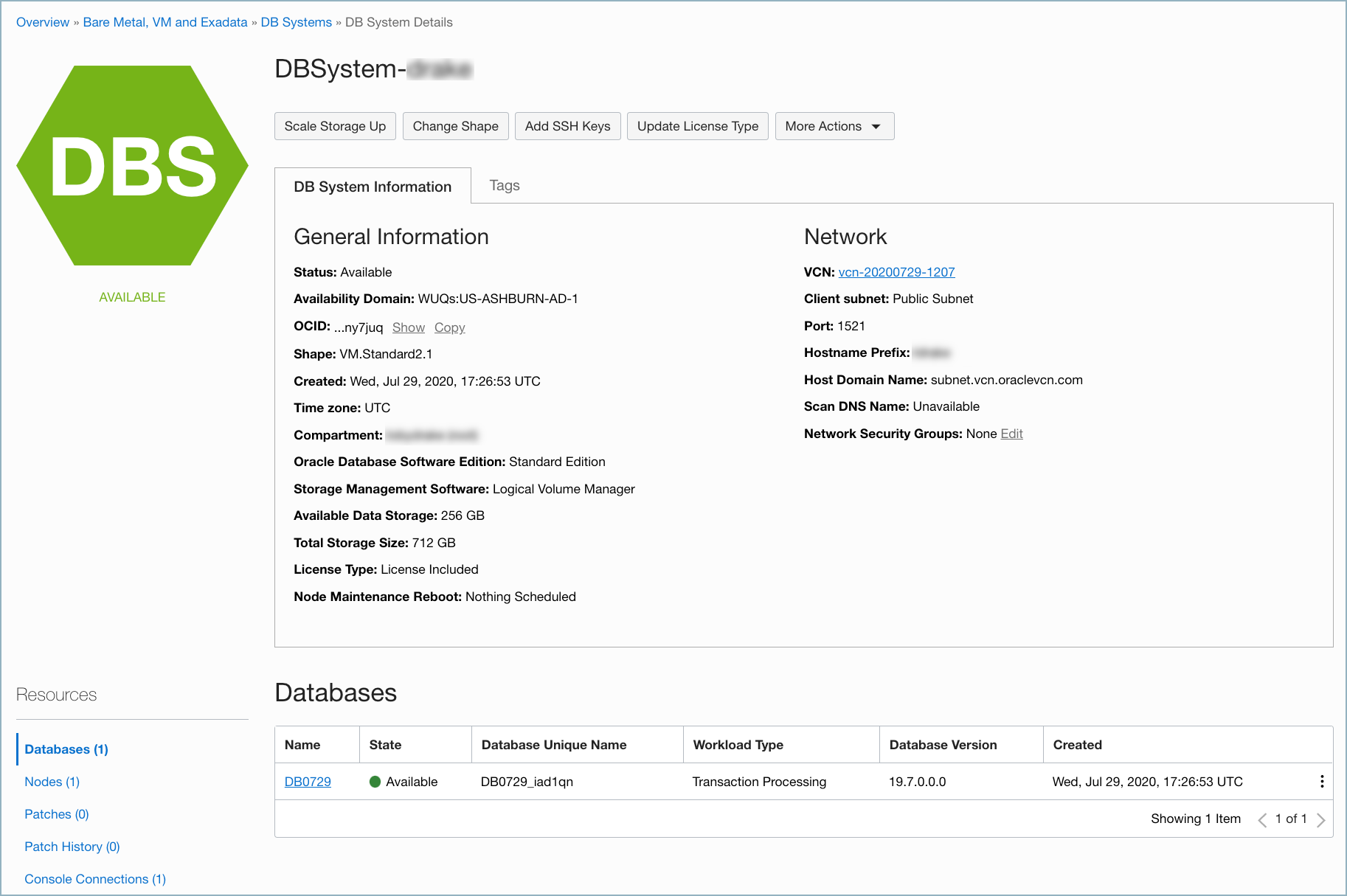
Use the following steps to configure an Oracle multitenant database system in the Oracle Cloud Infrastructure (OCI). Once configured, you can use the Oracle Database Source (JDBC) Connector for Confluent Cloud to connect to the database and obtain a snapshot of the existing data in the database and then monitor and record all subsequent row-level changes to that data.
- Prerequisites
Familiarity with Oracle database systems and management tools.
A running Oracle database on OCI. To create an Oracle database on OCI, see Creating Bare Metal and Virtual Machine DB Systems.
Authorization to create and modify an Oracle database on OCI.
A Console Connection configured for the database system. See Connecting to the Serial Console.
Ports 22 and 1521 open on the database machine (for SSH and SQL*Net access). For network configuration details, see Network Setup for DB Systems.
Step 1: SSH into the database VM
Open a Secure Shell (SSH) terminal session on the database VM and switch to the Oracle user. Note that you pass the private key for connecting to the VM instance.
ssh opc@<public-ip-address> -i </path/to/private-key>
For example:
ssh opc@192.136.114.86 -i ~/.ssh/oracle_id_rsa
Once you are on the VM, enter the following commands to switch to the Oracle user.
sudo su
su - oracle
Example output:
[opc@host ~]$ sudo su
[root@host opc]# su - oracle
Last login: Wed Jul 29 20:00:03 UTC 2020
[oracle@host ~]$
Step 2: Get the Pluggable Database (PDB) service name
Get the PDB service name by checking the listener status. Enter the following command on the VM as the Oracle user:
lsnrctl status LISTENER
For example:
[oracle@host ~]$ lsnrctl status LISTENER
LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-JUL-2020 21:41:52
Copyright (c) 1991, 2019, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=host.subnet.vcn.oraclevcn.com)(PORT=1521)))
STATUS of the LISTENER
------------------------
Alias LISTENER
Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production
Start Date 29-JUL-2020 17:39:05
Uptime 0 days 4 hr. 2 min. 47 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /u01/app/oracle/product/19.0.0/dbhome_1/network/admin/listener.ora
Listener Log File /u01/app/oracle/diag/tnslsnr/host/listener/alert/log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=host.subnet.vcn.oraclevcn.com)(PORT=1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=host.subnet.vcn.oraclevcn.com)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/admin/DB0729_iad1qn/xdb_wallet))(Presentation=HTTP)(Session=RAW))
Services Summary...
Service "DB0729XDB.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
Service "DB0729_iad1qn.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
Service "a33f59386e740c51e053c701f40af1dd.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
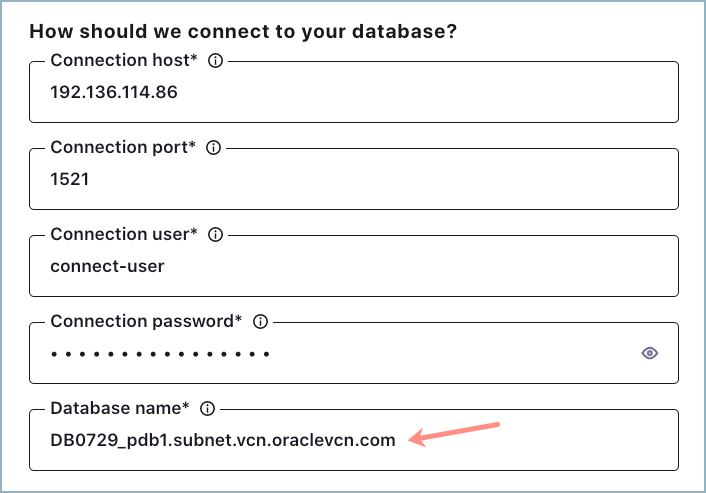
Service "db0729_pdb1.subnet.vcn.oraclevcn.com" has 1 instance(s).
Instance "DB0729", status READY, has 1 handler(s) for this service...
The command completed successfully
In the example output above, the PDB service name you need is shown below:
(HOST=host.subnet.vcn.oraclevcn.com)(PORT=1521)
Step 3: Create the PDB service name
Complete the following steps on the VM to create a new tnsnames.ora PDB service name entry. The new entry is used when setting up the database connection for the Oracle Database Source (JDBC) Connector for Confluent Cloud. The entry allows the connector to establish a connection to the Oracle database.
Exit the Oracle user account.
exit
Change to the root directory.
cd /
Find the
tnsnames.oraentries.find . -name tnsnames.ora
For example:
[oracle@host ~]$ exit logout [root@host opc]# cd / [root@host /]# find . -name tnsnames.ora ./u01/app/oracle/product/19.0.0/dbhome_1/network/admin/samples/tnsnames.ora ./u01/app/oracle/product/19.0.0/dbhome_1/network/admin/tnsnames.ora
Change to the
network/admindirectory.cd /u01/app/oracle/product/19.0.0/dbhome_1/network/admin
Edit the
tnsnames.orafile and add the PDB service name from the listener status output. The additional PDB service name block isDB0729_PDB1in the example.vi tnsnames.ora
For example:
DB0729_IAD1QN = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = host.subnet.vcn.oraclevcn.com)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = DB0729_iad1qn.subnet.vcn.oraclevcn.com) ) ) DB0729_PDB1 = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = host.subnet.vcn.oraclevcn.com)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = DB0729_pdb1.subnet.vcn.oraclevcn.com) ) )
Step 4: Launch the connector
Complete the steps in Oracle Database Source (JDBC) Connector for Confluent Cloud. When you get to the section where you need to add the database connection details, enter the PDB service name you added in the previous step. For example:
Configuration Properties
Use the following configuration properties with the fully-managed connector. For self-managed connector property definitions and other details, see the connector docs in Self-managed connectors for Confluent Platform.
How should we connect to your data?
nameSets a name for your connector.
Type: string
Valid Values: A string at most 64 characters long
Importance: high
Kafka Cluster credentials
kafka.auth.modeKafka Authentication mode. It can be one of KAFKA_API_KEY or SERVICE_ACCOUNT. It defaults to KAFKA_API_KEY mode, whenever possible.
Type: string
Valid Values: SERVICE_ACCOUNT, KAFKA_API_KEY
Importance: high
kafka.api.keyKafka API Key. Required when kafka.auth.mode==KAFKA_API_KEY.
Type: password
Importance: high
kafka.service.account.idThe Service Account that will be used to generate the API keys to communicate with Kafka Cluster.
Type: string
Importance: high
kafka.api.secretSecret associated with Kafka API key. Required when kafka.auth.mode==KAFKA_API_KEY.
Type: password
Importance: high
Schema Config
schema.context.nameAdd a schema context name. A schema context represents an independent scope in Schema Registry. It is a separate sub-schema tied to topics in different Kafka clusters that share the same Schema Registry instance. If not used, the connector uses the default schema configured for Schema Registry in your Confluent Cloud environment.
Type: string
Default: default
Importance: medium
How do you want to prefix table names?
topic.prefixPrefix to prepend to table names to generate the name of the Apache Kafka® topic to publish data to.
Type: string
Importance: high
Authentication method
authentication.methodSelect how you want to authenticate with your database.
Type: string
Default: Password
Importance: high
secret.manager.enabledFetch sensitive configuration values from a secret manager.
Type: boolean
Default: false
Importance: high
Secret manager configuration
secret.managerSelect the secret manager to use for retrieving sensitive data.
Type: string
Importance: high
secret.manager.managed.configsSelect the configurations to fetch their values from the secret manager.
Type: list
Importance: high
secret.manager.provider.integration.idSelect an existing provider integration that has access to your secret manager.
Type: string
Importance: high
How should we connect to your database?
connection.hostDepending on the service environment, certain network access limitations may exist. Make sure the connector can reach your service. Do not include jdbc:xxxx:// in the connection hostname property (e.g. database-1.abc234ec2.us-west.rds.amazonaws.com).
Type: string
Importance: high
connection.portJDBC connection port.
Type: int
Valid Values: [0,…,65535]
Importance: high
connection.userJDBC connection user.
Type: string
Importance: high
connection.passwordJDBC connection password.
Type: password
Importance: high
db.connection.typeSelect database connection using sid or service name
Type: string
Default: SID
Importance: high
db.nameJDBC database name.
Type: string
Importance: high
ssl.modeWhat SSL mode should we use to connect to your database. disabled disables SSL entirely. verify-ca uses SSL for encryption and performs authentication of the server CA. verify-ca option requires a Java truststore containing the server CA and the truststore password to be provided.
Type: string
Default: disabled
Importance: high
ssl.truststorefileThe binary trust store file that contains the server’s CA certificate. Only required if you use verify-ca or verify-full ssl mode. The connector supports files in JKS format. For REST API usage, you must base64-encode the binary trust store file and prefix it with
data:text/plain;base64,. For example, first, encode the filebase64_truststore=$(cat /path/to/truststore.jks | base64)and then usedata:text/plain;base64,$base64_truststoreas the value.Type: password
Default: [hidden]
Importance: low
ssl.truststorepasswordThe trust store password containing server CA certificate. Only required if using verify-ca or verify-full ssl mode.
Type: password
Default: [hidden]
Importance: low
ssl.server.cert.dnUse this paramter to specify the distinguished name (DN) of the database server. Only required if using verify-full ssl mode.
Type: string
Importance: low
Database details
table.whitelist(Deprecated) List of tables to include in copying. Use a comma-separated list to specify multiple tables (for example: “User, Address, Email”). This is deprecated, please use table.include.list.
Type: list
Importance: medium
table.include.listA comma-separated list of regular expressions that match the fully-qualified names of tables to be copied. Use a comma-separated list to specify multiple regular expressions. Table names are case-sensitive. For example,
table.include.list: schema1.customer.*,schema2.order.*. If specified,table.whitelistcannot be set.Type: list
Importance: medium
table.exclude.listA comma-separated list of regular expressions that match the fully-qualified names of tables to be excluded from copying. Use a comma-separated list to specify multiple regular expressions. Table names are case-sensitive. For example,
table.exclude.list: schema1.customer.*,schema2.order.*. If specified,table.whitelistcannot not be set.Type: list
Importance: medium
queryIf specified, the connector uses this custom SQL query to read source records, which allows for operations like joining tables or selecting subsets of data. Providing a query instructs the connector to read only the result set instead of performing a full table copy. This configuration supports different query modes with the incremental query properly constructed by appending a WHERE clause (For more information, Incremental Query Modes - <https://docs.confluent.io/kafka-connectors/jdbc/current/source-connector/overview.html#incremental-query-modes>). Note that only SELECT statements are supported. Always adhere to security best practices, like enforcing strict authorization via <https://docs.confluent.io/cloud/current/connectors/managed-connector-rbac.html#managed-connector-rbac>, applying appropriate :ref: network access controls - <https://docs.confluent.io/cloud/current/security/access-control/ip-filtering/manage-ip-filters.html> for control plane APIs, and following the principle of least privilege when provisioning identities or credentials for any third-party systems.
Type: password
Default: [hidden]
Importance: medium
table.typesBy default, the JDBC connector will only detect tables with type TABLE from the source Database. This config allows a command separated list of table types to extract.
Type: list
Default: TABLE
Importance: medium
schema.patternSchema pattern to fetch table metadata from the database.
Type: string
Importance: high
db.timezoneName of the JDBC timezone used in the connector when querying with time-based criteria. Defaults to UTC.
Type: string
Default: UTC
Importance: medium
numeric.mappingMap NUMERIC values by precision and optionally scale to integral or decimal types. Use
noneif all NUMERIC columns are to be represented by Connect’s DECIMAL logical type. Usebest_fitif NUMERIC columns should be cast to Connect’s INT8, INT16, INT32, INT64, or FLOAT64 based upon the column’s precision and scale. Usebest_fit_eager_doubleif, in addition to the properties of best_fit described above, it is desirable to always cast NUMERIC columns with scale to Connect FLOAT64 type, despite potential of loss in accuracy. Useprecision_onlyto map NUMERIC columns based only on the column’s precision assuming that column’s scale is 0. Thenoneoption is the default, but may lead to serialization issues with Avro since Connect’s DECIMAL type is mapped to its binary representation, andbest_fitwill often be preferred since it maps to the most appropriate primitive type.Type: string
Default: none
Importance: low
timestamp.granularityDefine the granularity of the Timestamp column. CONNECT_LOGICAL (default): represents timestamp values using Kafka Connect built-in representations. MICROS_LONG: represents timestamp values as micros since epoch. MICROS_STRING: represents timestamp values as micros since epoch in string. MICROS_ISO_DATETIME_STRING: uses iso format for timestamps in micros. NANOS_LONG: represents timestamp values as nanos since epoch. NANOS_STRING: represents timestamp values as nanos since epoch in string. NANOS_ISO_DATETIME_STRING: uses iso format
Type: string
Default: CONNECT_LOGICAL
Importance: low
Mode
modeThe mode for updating a table each time it is polled.
BULK: perform a bulk load of the entire table each time it is polled.TIMESTAMP: use a timestamp (or timestamp-like) column to detect new and modified rows. This assumes the column is updated with each write, and that values are monotonically incrementing, but not necessarily unique.INCREMENTING: use a strictly incrementing column on each table to detect only new rows. Note that this will not detect modifications or deletions of existing rows.TIMESTAMP AND INCREMENTING: use two columns, a timestamp column that detects new and modified rows and a strictly incrementing column which provides a globally unique ID for updates so each row can be assigned a unique stream offset.Type: string
Default: “”
Importance: medium
timestamp.columns.mappingA comma-separated list of table regex to timestamp columns mappings. On specifying multiple timestamp columns, COALESCE SQL function would be used to find out the effective timestamp for a row. Expected format is
regex1:[col1|col2],regex2:[col3]. Regexes would be matched against the fully-qualified table names. Identifier names are case sensitive. Every table included for capture should match exactly one of the provided mappings. An example for a valid input would be.*\.customers.*:[updated_at|modified_at],.*\.orders.*:[changed_at].Type: list
Importance: medium
incrementing.column.mappingA comma-separated list of table regex to incrementing column mappings. Expected format is
regex1:col1,regex2:col2. Regexes would be matched against the fully-qualified table names. Identifier names are case sensitive. Every table included for capture should match exactly one of the provided mappings. An example for a valid input would be.*\.customers.*:id,.*\.orders.*:order_id.Type: list
Importance: medium
timestamp.column.name(Deprecated legacy configuration. Use timestamp.columns.mapping for new implementations.) Comma separated list of one or more timestamp columns to detect new or modified rows using the COALESCE SQL function. Rows whose first non-null timestamp value is greater than the largest previous timestamp value seen will be discovered with each poll. At least one column should not be nullable.
Type: list
Importance: medium
quote.sql.identifiersWhen to quote table names, column names, and other identifiers in SQL statements. For backward compatibility, the default value is ALWAYS.
Type: string
Default: ALWAYS
Valid Values: ALWAYS, NEVER
Importance: medium
incrementing.column.name(Deprecated legacy configuration. Use incrementing.column.mapping for new implementations.) The name of the strictly incrementing column to use to detect new rows. Any empty value indicates the column should be autodetected by looking for an auto-incrementing column. This column may not be nullable.
Type: string
Default: “”
Importance: medium
transaction.isolation.modeIsolation level determines how transaction integrity is visible to other users and systems.
DEFAULT: This is the default isolation level configured at the Database Server.READ_UNCOMMITTED: This is the lowest isolation level. At this level, one transaction may see dirty reads (that is, not-yet-committed changes made by other transactions).READ_COMMITTED: This level guarantees that any data read is already committed at the moment it is read.REPEATABLE_READ: In addition to the guarantees of theREAD_COMMITTEDlevel, this option also guarantees that any data read cannot change, if the transaction reads the same data again. However, phantom reads are possible.SERIALIZABLE: This is the highest isolation level. In addition to everythingREPEATABLE_READguarantees, it also eliminates phantom reads.Type: string
Default: DEFAULT
Valid Values: DEFAULT, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, SERIALIZABLE
Importance: medium
timestamp.initialThe epoch timestamp used for initial queries that use timestamp criteria. The value
-1sets the initial timestamp to the current time. If not specified, the connector retrieves all data. Once the connector has managed to successfully record a source offset, this property has no effect even if changed to a different value later on.Type: long
Valid Values: [-1,…]
Importance: medium
date.calendar.systemThe time elapsed from epoch populated in the end table topic for DATE or TIMESTAMP type columns can have two different values based upon the Calendar used to interpret it. If
LEGACYis used, it will use the hybrid Gregorian/Julian calendar which was the default in the older java date time APIs. However, ifPROLEPTIC_GREGORIANis used, then it will use the proleptic gregorian calendar which extends the Gregorian rules backward indefinitely and does not apply the 1582 cutover. This matches the behavior of modern Java date/time APIs (java.time). This is defaulted to LEGACY for backward compatibility. Changing this configuration on an existing connector might lead to a drift in the kafka topic record values.Type: string
Default: LEGACY
Importance: medium
Connection details
poll.interval.msFrequency in ms to poll for new data in each table.
Type: int
Default: 5000 (5 seconds)
Valid Values: [100,…]
Importance: high
batch.max.rowsMaximum number of rows to include in a single batch when polling for new data. This setting can be used to limit the amount of data buffered internally in the connector.
Type: int
Default: 100
Valid Values: [1,…,5000]
Importance: low
timestamp.delay.interval.msHow long to wait after a row with a certain timestamp appears before we include it in the result. You may choose to add some delay to allow transactions with an earlier timestamp to complete. The first execution will fetch all available records (starting at timestamp 0) until current time minus the delay. Every following execution will get data from the last time we fetched until current time minus the delay.
Type: int
Default: 0
Valid Values: [0,…]
Importance: high
Output messages
output.data.formatSets the output Kafka record value format. Valid entries are AVRO, JSON_SR, PROTOBUF, JSON, or STRING. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO, JSON_SR, and PROTOBUF
Type: string
Default: JSON
Importance: high
Number of tasks for this connector
tasks.maxMaximum number of tasks for the connector.
Type: int
Valid Values: [1,…]
Importance: high
Additional Configs
header.converterThe converter class for the headers. This is used to serialize and deserialize the headers of the messages.
Type: string
Importance: low
producer.override.compression.typeThe compression type for all data generated by the producer. Valid values are none, gzip, snappy, lz4, and zstd.
Type: string
Importance: low
producer.override.linger.msThe producer groups together any records that arrive in between request transmissions into a single batched request. More details can be found in the documentation: https://docs.confluent.io/platform/current/installation/configuration/producer-configs.html#linger-ms.
Type: long
Valid Values: [100,…,1000]
Importance: low
value.converter.allow.optional.map.keysAllow optional string map key when converting from Connect Schema to Avro Schema. Applicable for Avro Converters.
Type: boolean
Importance: low
value.converter.auto.register.schemasSpecify if the Serializer should attempt to register the Schema.
Type: boolean
Importance: low
value.converter.connect.meta.dataAllow the Connect converter to add its metadata to the output schema. Applicable for Avro Converters.
Type: boolean
Importance: low
value.converter.enhanced.avro.schema.supportEnable enhanced schema support to preserve package information and Enums. Applicable for Avro Converters.
Type: boolean
Importance: low
value.converter.enhanced.protobuf.schema.supportEnable enhanced schema support to preserve package information. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.flatten.unionsWhether to flatten unions (oneofs). Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.generate.index.for.unionsWhether to generate an index suffix for unions. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.generate.struct.for.nullsWhether to generate a struct variable for null values. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.int.for.enumsWhether to represent enums as integers. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.latest.compatibility.strictVerify latest subject version is backward compatible when use.latest.version is true.
Type: boolean
Importance: low
value.converter.object.additional.propertiesWhether to allow additional properties for object schemas. Applicable for JSON_SR Converters.
Type: boolean
Importance: low
value.converter.optional.for.nullablesWhether nullable fields should be specified with an optional label. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.optional.for.proto2Whether proto2 optionals are supported. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.scrub.invalid.namesWhether to scrub invalid names by replacing invalid characters with valid characters. Applicable for Avro and Protobuf Converters.
Type: boolean
Importance: low
value.converter.use.latest.versionUse latest version of schema in subject for serialization when auto.register.schemas is false.
Type: boolean
Importance: low
value.converter.use.optional.for.nonrequiredWhether to set non-required properties to be optional. Applicable for JSON_SR Converters.
Type: boolean
Importance: low
value.converter.wrapper.for.nullablesWhether nullable fields should use primitive wrapper messages. Applicable for Protobuf Converters.
Type: boolean
Importance: low
value.converter.wrapper.for.raw.primitivesWhether a wrapper message should be interpreted as a raw primitive at root level. Applicable for Protobuf Converters.
Type: boolean
Importance: low
errors.toleranceUse this property if you would like to configure the connector’s error handling behavior. WARNING: This property should be used with CAUTION for SOURCE CONNECTORS as it may lead to dataloss. If you set this property to ‘all’, the connector will not fail on errant records, but will instead log them (and send to DLQ for Sink Connectors) and continue processing. If you set this property to ‘none’, the connector task will fail on errant records.
Type: string
Default: none
Importance: low
key.converter.key.schema.id.serializerThe class name of the schema ID serializer for keys. This is used to serialize schema IDs in the message headers.
Type: string
Default: io.confluent.kafka.serializers.schema.id.PrefixSchemaIdSerializer
Importance: low
key.converter.key.subject.name.strategyHow to construct the subject name for key schema registration.
Type: string
Default: TopicNameStrategy
Importance: low
value.converter.decimal.formatSpecify the JSON/JSON_SR serialization format for Connect DECIMAL logical type values with two allowed literals:
BASE64 to serialize DECIMAL logical types as base64 encoded binary data and
NUMERIC to serialize Connect DECIMAL logical type values in JSON/JSON_SR as a number representing the decimal value.
Type: string
Default: BASE64
Importance: low
value.converter.flatten.singleton.unionsWhether to flatten singleton unions. Applicable for Avro and JSON_SR Converters.
Type: boolean
Default: false
Importance: low
value.converter.ignore.default.for.nullablesWhen set to true, this property ensures that the corresponding record in Kafka is NULL, instead of showing the default column value. Applicable for AVRO,PROTOBUF and JSON_SR Converters.
Type: boolean
Default: false
Importance: low
value.converter.reference.subject.name.strategySet the subject reference name strategy for value. Valid entries are DefaultReferenceSubjectNameStrategy or QualifiedReferenceSubjectNameStrategy. Note that the subject reference name strategy can be selected only for PROTOBUF format with the default strategy being DefaultReferenceSubjectNameStrategy.
Type: string
Default: DefaultReferenceSubjectNameStrategy
Importance: low
value.converter.replace.null.with.defaultWhether to replace fields that have a default value and that are null to the default value. When set to true, the default value is used, otherwise null is used. Applicable for JSON Converter.
Type: boolean
Default: true
Importance: low
value.converter.schemas.enableWhen true, the JsonConverter writes each record to Kafka as a {schema, payload} envelope so downstream consumers can interpret the value with its schema. When false, only the payload (plain JSON) is written. Applicable for JSON Converter.
Type: boolean
Default: false
Importance: low
value.converter.value.schema.id.serializerThe class name of the schema ID serializer for values. This is used to serialize schema IDs in the message headers.
Type: string
Default: io.confluent.kafka.serializers.schema.id.PrefixSchemaIdSerializer
Importance: low
value.converter.value.subject.name.strategyDetermines how to construct the subject name under which the value schema is registered with Schema Registry.
Type: string
Default: TopicNameStrategy
Importance: low
Auto-restart policy
auto.restart.on.user.errorEnable connector to automatically restart on user-actionable errors.
Type: boolean
Default: true
Importance: medium
Frequently asked questions
Find answers to frequently asked questions about the fully managed Oracle Database Source connector for Confluent Cloud.
Configuration and setup
Why is my connector failing with task killed: not assigned a table or query?
This error occurs when the connector is not assigned a specific table or when both a table and query are specified in the configuration.
Common causes:
The specified table does not exist or is not accessible by the connector user.
Both
table.include.listandqueryproperties are configured. The connector requires one or the other, not both.The table name is not fully qualified or the connector user lacks visibility to the specified table.
Resolution:
Verify that the table exists in the Oracle database and is accessible by the user specified in
connection.user.Ensure you configure either
table.include.listorquery, but not both.Use fully qualified table names in the format
SCHEMA.TABLE_NAME(for example,HR.EMPLOYEES).Grant the necessary permissions to the connector user to access the specified tables. The user must have
SELECTprivileges on the tables you want to ingest.
For more information about configuration properties, see Configuration Properties.
How do I configure the connector to use a Pluggable Database (PDB)?
Oracle databases starting with version 12c use a multitenant architecture with Container Databases (CDB) and Pluggable Databases (PDB). The connector requires a PDB service name for the Database name configuration property.
Configuration steps:
Identify the PDB service name from your Oracle database. See Configuring a Multitenant Oracle Database System for detailed instructions on configuring multitenant Oracle databases.
Use the PDB service name (not the CDB name) in the Database name field when configuring the connector. For example:
"db.name": "db0729_pdb1.subnet.vcn.oraclevcn.com"
Ensure the connector user has the necessary privileges in the PDB, not only the CDB.
Prerequisites:
Oracle Database version
11.2.0.4or later.The PDB must be in OPEN state.
The connector user must exist in the PDB and have
SELECTprivileges on the tables to be ingested.
For more information about multitenant database configuration, see Configuring a Multitenant Oracle Database System.
Database connection and errors
How do I troubleshoot ORA-01109: database not open errors?
The ORA-01109 error indicates that the Oracle database is not in the OPEN state when the connector attempts to connect.
Common causes:
The Oracle database is in MOUNT state or another non-OPEN state.
Insufficient memory or disk space prevented the database from opening.
Database restart or maintenance operations left the database in a closed state.
Resolution:
Check the database status using SQL*Plus or another Oracle client:
SELECT status FROM v$instance;
Work with your database administrator (DBA) to ensure the database is in OPEN state.
Verify that the host has enough resources (memory, disk space, CPU) to open the database.
If the database is in MOUNT state, open it using:
ALTER DATABASE OPEN;
After confirming the database is open, restart the connector.
For more information about prerequisites, see Prerequisites.
Why am I seeing SSL handshake errors when connecting to Oracle Database?
SSL/TLS handshake errors can occur due to certificate validation issues, incompatible SSL configurations, or Java runtime environment changes.
Common causes:
Missing or invalid SSL certificates.
Certificate authority (CA) validation failures.
Incompatibility between the Oracle JDBC driver and the Java runtime environment.
Changes to the Java Development Kit (JDK) security settings.
Resolution:
Verify that your Oracle database is configured to accept SSL/TLS connections.
If using SSL, ensure that the Oracle database certificate is valid and not expired.
Check the Oracle database SSL configuration and ensure the cipher suites are compatible with the JDBC driver.
Review Oracle JDBC driver documentation for SSL/TLS configuration requirements.
If you recently upgraded or if the connector environment was updated, verify compatibility between the JDK version and the Oracle JDBC driver.
Advanced configuration:
For non-SSL connections, ensure that ssl.mode is not configured or set to allow unencrypted connections. For SSL connections, you might need to provide more JDBC connection properties through the connector configuration.
If you continue to experience SSL handshake errors, contact Confluent Support for assistance with advanced troubleshooting.
How do I troubleshoot connection timeouts or connectivity issues?
Connection issues can occur due to network configuration, firewall rules, or database availability. Follow these troubleshooting steps to resolve connectivity problems.
Verify network configuration:
Ensure your Oracle database is accessible from Confluent Cloud. The connector must be able to reach your database hostname and port.
Do not include
jdbc:xxxx://in the connection hostname property. Use only the hostname (for example,mydatabase.abc123ecs2.us-west.rds.amazonaws.com).For Amazon Web Services (AWS) RDS or other cloud databases, verify that security group rules allow inbound traffic from Confluent Cloud on the Oracle port (default 1521).
For Microsoft Azure (Azure) Virtual Networks, ensure that Allow access to Azure Services is enabled. Clients from Azure Virtual Networks are not allowed to access the server by default.
See your specific cloud platform documentation for how to configure security rules for your VPC.
Check connector configuration:
Verify that the
connection.hostandconnection.portproperties are correctly configured.Ensure that the
connection.userhas enough permissions to access the database and tables.Test database connectivity from a client outside Confluent Cloud to confirm the database is reachable.
Private networking considerations:
If you are using PrivateLink or other private networking solutions, ensure your network configuration allows traffic from the connector to your database.
Review Manage Networking for Confluent Cloud Connectors for networking details.
Consider using Public Egress IP Addresses for Confluent Cloud Connectors if you need to allowlist specific IP addresses.
For more information, see the Prerequisites section.
Data synchronization and polling
Why isn’t my timestamp column detecting new or modified rows?
The connector uses timestamp columns to detect new and modified rows in timestamp mode. If your connector is not detecting changes, review the following configuration requirements.
Requirements for timestamp columns:
The timestamp column must not be nullable. The connector cannot use nullable timestamp columns.
The column must be updated automatically with each write operation.
Values must be monotonically incrementing (though not necessarily unique).
The column must contain timestamp or timestamp-like data that is compatible with Oracle’s
TIMESTAMPorDATEdata types.
Insert modes:
Timestamp mode: Specify only a timestamp column when you configure the connector using the
timestamp.columns.mappingproperty. This mode uses a timestamp (or timestamp-like) column to detect new and modified rows. This assumes the column is updated with each write, and that values are monotonically incrementing, but not necessarily unique.Timestamp+incrementing mode: Specify both a timestamp column and an incrementing column using both
timestamp.columns.mappingandincrementing.column.nameproperties. This mode uses two columns: a timestamp column that detects new and modified rows, and a strictly incrementing column which provides a globally unique ID for updates so each row can be assigned a unique stream offset.
Timestamp column mapping:
Use the timestamp.columns.mapping property to specify which timestamp column to use for each table. For example:
"timestamp.columns.mapping": ".*PASSENGERS.*:[CREATED_AT]"
Verify SQL compatibility:
Ensure that the SQL statement used to retrieve the current timestamp is compatible with Oracle. The connector uses Oracle-specific SQL syntax to query timestamp values.
For more information, see the Prerequisites section.
Why is the connector missing or skipping records?
Records can be missed or skipped due to improper timestamp column configuration, connector restarts, or database query issues.
Common causes:
Timestamp column configuration: If using timestamp mode with a timestamp column that has duplicate values or is not monotonically increasing, the connector might skip records. Several rows with identical timestamp values can cause unpredictable behavior.
Connector restarts: When the connector restarts, it resumes from the last committed offset. If offsets are not properly managed or if the timestamp column is not configured correctly, the connector might skip some records.
Nullable timestamp columns: The connector cannot use nullable timestamp columns and fails or skips records if the column contains NULL values.
Incrementing column issues: If using timestamp+incrementing mode, ensure the incrementing column is strictly increasing and non-nullable.
Resolution:
Use timestamp+incrementing mode instead of timestamp mode to ensure unique record identification. Configure both
timestamp.columns.mappingandincrementing.column.nameproperties.Verify that your timestamp column is not nullable and contains only non-NULL values.
Ensure that timestamp values are monotonically increasing (newer records have later timestamps).
If duplicates are unavoidable, use an incrementing column to provide a unique identifier for each row.
Review Manage custom offsets for guidance on offset management.
Monitor connector logs for errors or warnings related to timestamp queries or offset commits.
For more information about insert modes, see the preceding Features section.
How do I troubleshoot performance issues or slow polling?
Performance issues can occur when the connector processes large datasets or uses inefficient polling intervals. Review the following configuration properties to optimize connector performance.
Adjust polling intervals:
poll.interval.ms: Controls how often the connector polls for new data. The default is 5,000 milliseconds. Increasing this value reduces the frequency of database queries, which can improve performance for databases with infrequent updates.timestamp.delay.interval.ms: Specifies the delay interval to wait before querying for new data. This can help ensure that all data is available before the connector attempts to read it.
Optimize batch size:
batch.max.rows: Controls how many rows to include in a single batch when polling for new data. The default is 100 rows. Increasing this value can improve throughput for large datasets, but can also increase memory usage.
Review database performance:
Ensure your database has appropriate indexes on timestamp and incrementing columns to optimize query performance.
Monitor database query performance to identify slow queries or resource constraints.
Consider whether your database instance has enough CPU, memory, and I/O capacity to handle the connector workload.
For large tables, consider using partitioning strategies at the database level to improve query performance.
Advanced configuration:
If you continue to experience performance issues, you might need to adjust advanced connector properties or contact Confluent Support for assistance.
For more information about configuration properties, see Configuration Properties.
Next Steps
For an example that shows fully-managed Confluent Cloud connectors in action with Confluent Cloud for Apache Flink, see the Cloud ETL Demo. This example also shows how to use Confluent CLI to manage your resources in Confluent Cloud.
