
Observability for Kafka Clients to Confluent Cloud
Confluent Cloud removes many of the challenges you face when monitoring an on-premises Kafka cluster, but you still need to monitor your client applications and, to some degree, your Confluent Cloud cluster. Your success in Confluent Cloud largely depends on how well your applications perform. Observability into the performance and status of your client applications gives you insight into how to fine-tune your producers and consumers, when to scale your Confluent Cloud cluster, what might go wrong, and how to resolve problems.
This module covers how to set up a time-series database populated with data from the Confluent Cloud Metrics API and client metrics from a locally running Java consumer and producer, along with how to set up a data visualization tool. After the initial setup, you follow a series of scenarios that simulate failures and alert you when the errors occur.
Note
This example uses Prometheus as the time-series database and Grafana for visualization, but the same principles can be applied to any other technologies.
Prerequisites
Access to Confluent Cloud
Local install of Confluent CLI (v3.0.0 or later)
jq installed on your host
Docker installed on your host
Evaluate the costs to run the tutorial
Confluent Cloud examples that use actual Confluent Cloud resources might be billable. An example might create a new Confluent Cloud environment, Kafka cluster, topics, ACLs, service accounts, or resources that have hourly charges like connectors and ksqlDB applications. To avoid unexpected charges, carefully evaluate the cost of resources before you start. After you are done running a Confluent Cloud example, destroy all Confluent Cloud resources to avoid accruing hourly charges for services and verify that they have been deleted.
Confluent Cloud cluster and observability container setup
The following instructions:
Use
ccloud-stackto create a Confluent Cloud cluster, a service account with proper access control lists (ACLs), and a client configuration fileCreate a
cloudresource API key for theccloud-exporterBuild an Apache Kafka® client Docker image with the Maven project’s dependencies cache
Stand up multiple Docker containers (one consumer with JMX exporter, one producer with JMX exporter, Prometheus, Grafana and a Prometheus node-exporter) with Docker Compose
Log in to Confluent Cloud with the Confluent CLI:
confluent login --prompt --save
The
--saveflag saves your Confluent Cloud login credentials.Clone the confluentinc/examples GitHub repository.
git clone https://github.com/confluentinc/examples.git
Navigate to the
examples/ccloud-observability/directory and switch to themasterbranch:cd examples/ccloud-observability/ git checkout master
Set up a Confluent Cloud cluster, secrets, and observability components by running start.sh script:
./start.sh
Wait up to three minutes for data to become visible in Grafana, then continue to Validate setup to confirm your environment is ready.
Validate setup
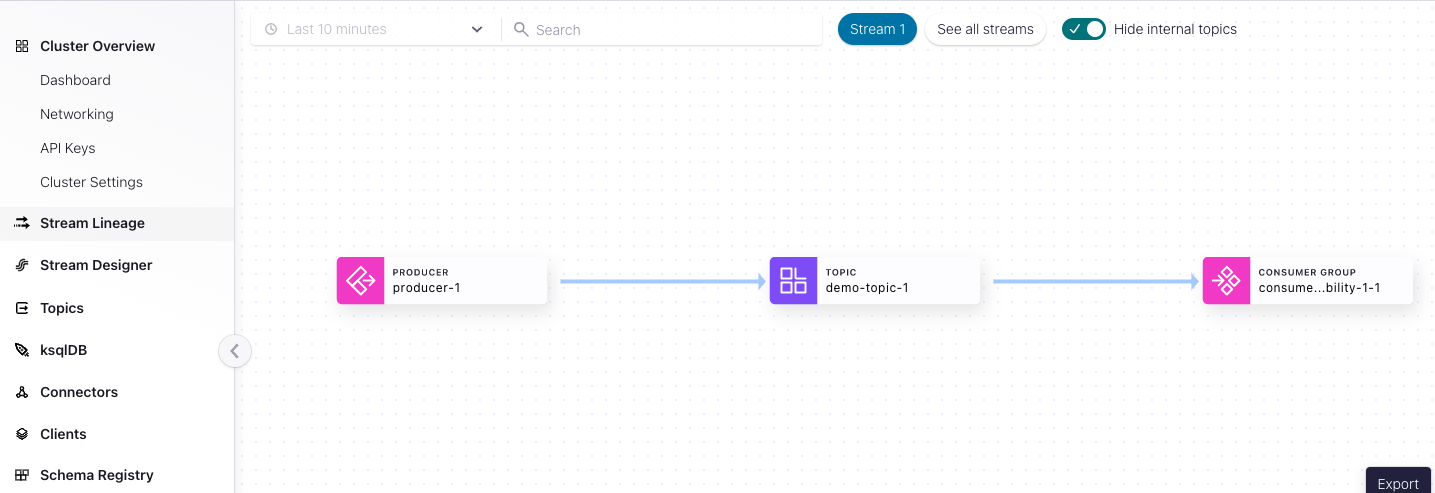
Validate the producer and consumer Kafka clients are running. From the Cloud Console, view the Stream Lineage in your newly created environment and Kafka cluster.
Navigate to the Prometheus Targets page.
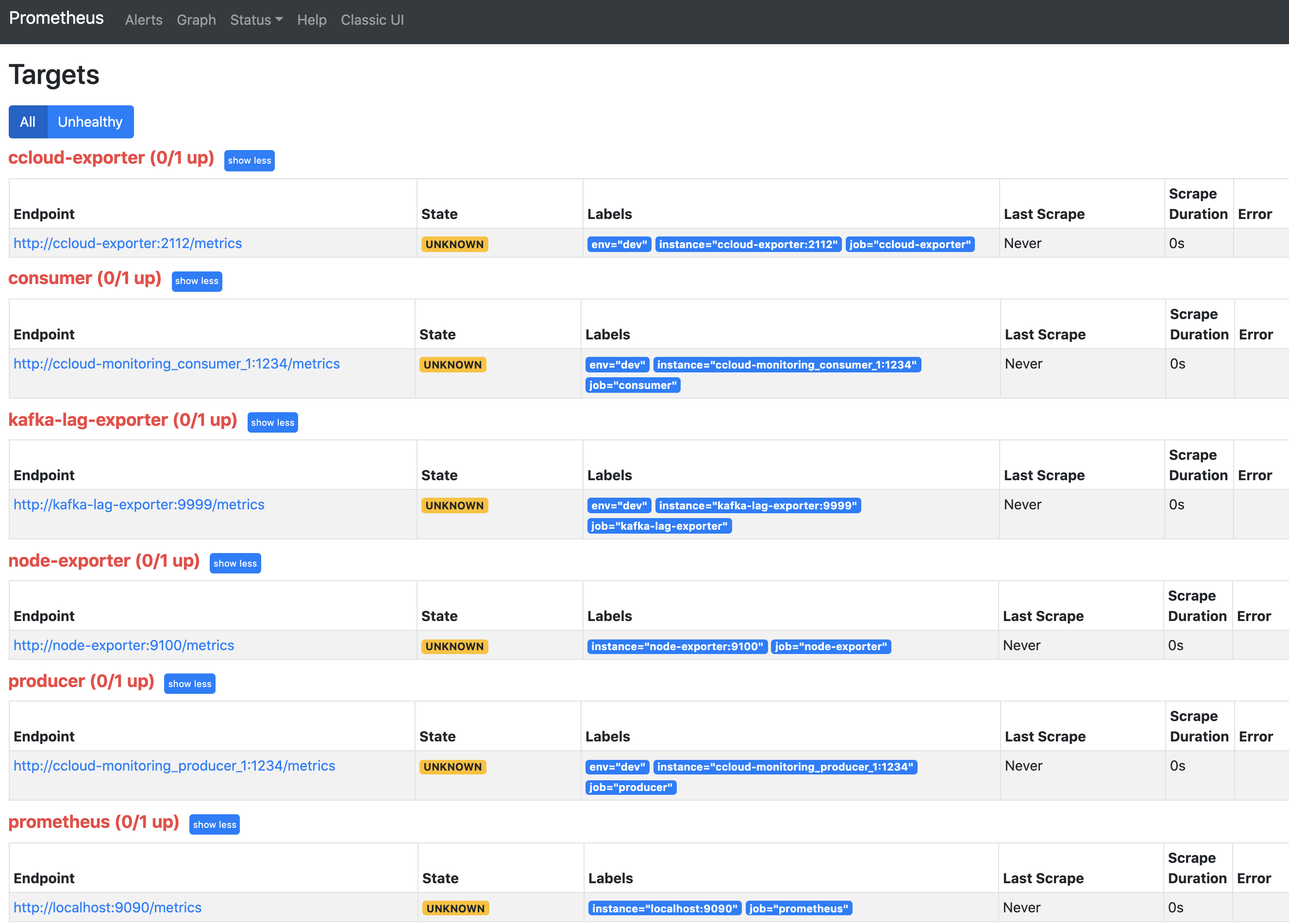
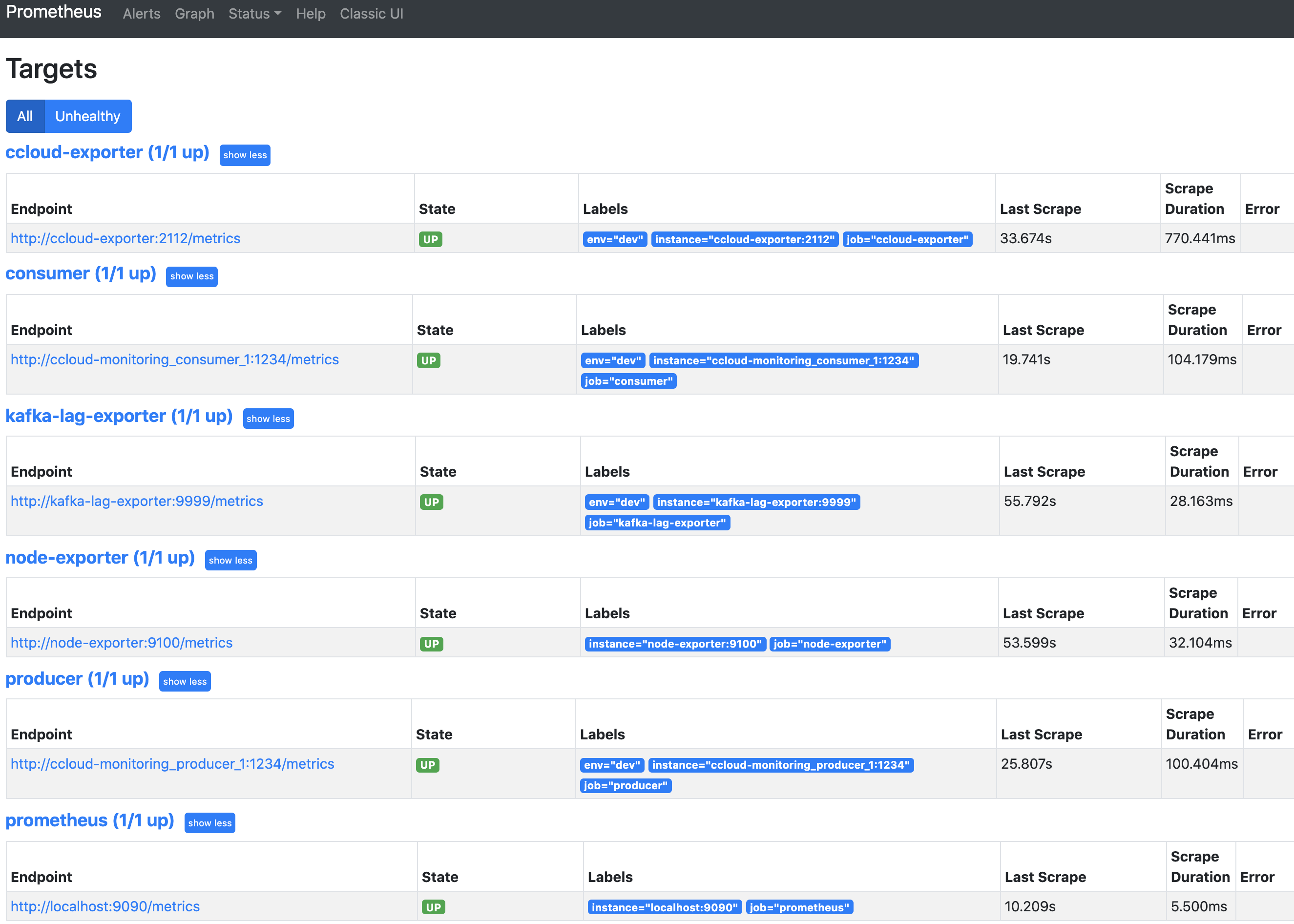
This page shows whether Prometheus is scraping the targets you have created. It should look like the following after two minutes if everything is working. You might need to refresh the page.
Open Grafana and use the username
adminand passwordpasswordto log in.Now you are ready to proceed to Producer client scenarios, Consumer client scenarios, or General client scenarios to see what different failure scenarios look like.
Producer client scenarios
The dashboard and scenarios in this section use client metrics from a Java producer. The same principles can be applied to any other non-Java clients: they generally offer similar metrics.
The source code for the client can be found in the ccloud-observability/src directory. The sample client uses default configurations, which is not a best practice for production use cases. This Java producer continues to produce the same message every 100 ms until the process is interrupted. The content of the message is not important here. In these scenarios, the focus is on the change in client metric values.
Confluent Cloud unreachable
In the producer container, add a rule blocking network traffic that has a destination TCP port 9092. This prevents the producer from reaching the Kafka cluster in Confluent Cloud.
This scenario looks at Confluent Cloud metrics from the Metrics API and client metrics from the client application’s MBean object kafka.producer:type=producer-metrics,client-id=producer-1.
Introduce failure scenario
Add a rule blocking traffic in the
producercontainer on port9092which is used to talk to the broker:docker compose exec producer iptables -A OUTPUT -p tcp --dport 9092 -j DROP
Diagnose the problem
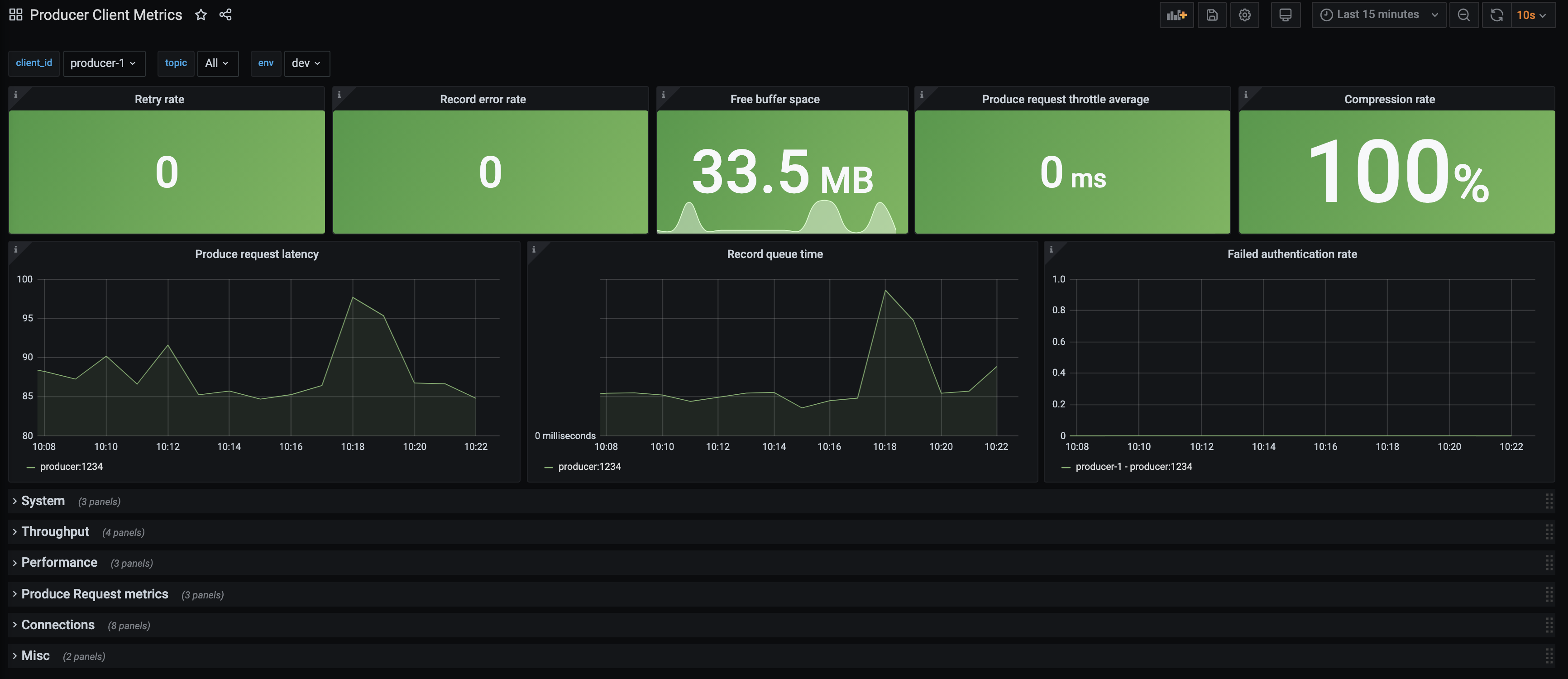
From your web browser, navigate to the Grafana dashboard at http://localhost:3000 and log in with the username
adminand passwordpassword.Navigate to the
Producer Client Metricsdashboard. Wait two minutes and then observe:A downward trend in outgoing bytes which you can find by expanding the
Throughputtab.The top-level panels like
Record error rate(derived from Kafka MBean attributerecord-error-rate) should turn red, a major indication something is wrong.The spark line in the
Free buffer space(derived from Kafka MBean attributebuffer-available-bytes) panel go down and a bump inRetry rate(derived from Kafka MBean attributerecord-retry-rate).
This means the producer is not producing data, which could happen for a few reasons.
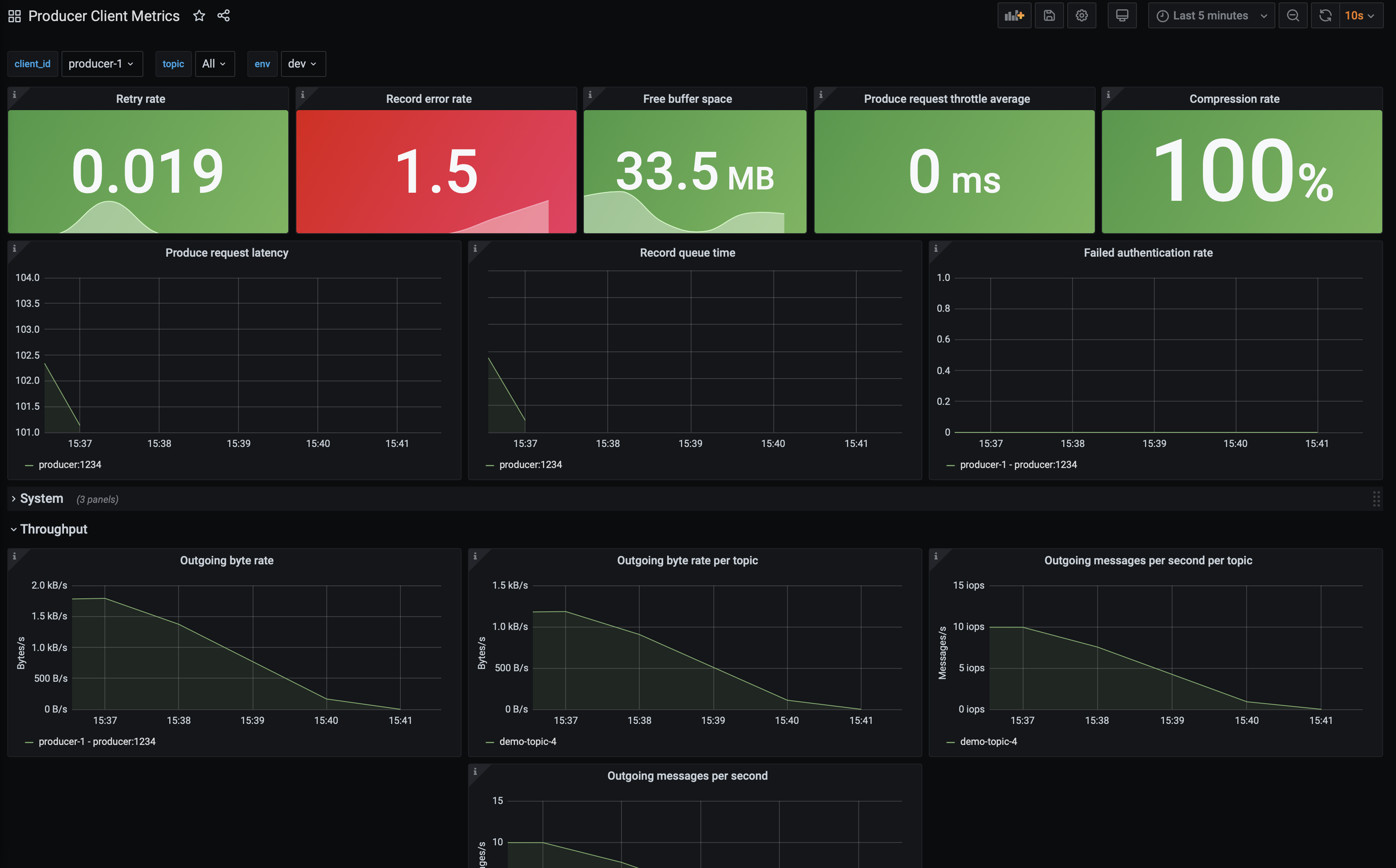
Check the status of the Confluent Cloud cluster, specifically that it is accepting requests to isolate this problem to the producer. To do this, navigate to the Confluent Cloud dashboard.
Look at the top panels. They should all be green which means the cluster is operating safely within its resources.

For a connectivity problem in a client, look specifically at the
Requests (rate). If this value is yellow or red, the client connectivity problem could be due to hitting the Confluent Cloud requests rate limit. If you exceed the maximum, requests might be refused. See the General Request Rate Limits scenario for more details.Check the producer logs for more information about what is going wrong. Use the following Docker command to get the producer logs:
docker compose logs producer
Verify that you see log messages similar to the following:
producer | [2021-02-11 18:16:12,231] WARN [Producer clientId=producer-1] Got error produce response with correlation id 15603 on topic-partition demo-topic-1-3, retrying (2147483646 attempts left). Error: NETWORK_EXCEPTION (org.apache.kafka.clients.producer.internals.Sender) producer | [2021-02-11 18:16:12,232] WARN [Producer clientId=producer-1] Received invalid metadata error in produce request on partition demo-topic-1-3 due to org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.. Going to request metadata update now (org.apache.kafka.clients.producer.internals.Sender)
The logs provide a clear picture of what is going on:
Error: NETWORK_EXCEPTIONandserver disconnected. This was expected because the failure scenario you introduced blocked outgoing traffic to the broker’s port. Looking at metrics alone does not always lead you directly to an answer, but they are a quick way to see if things are working as expected.
Resolve failure scenario
Remove the rule you created earlier that blocked traffic with the following command:
docker compose exec producer iptables -D OUTPUT -p tcp --dport 9092 -j DROP
It might take a few minutes for the producer to start sending requests again.
Troubleshooting
Producer output rate doesn’t come back up after adding in the
iptablesrule.Restart the producer by running
docker compose restart producer. This is advice specific to this tutorial.
Authorization revoked
Using the Confluent CLI, revoke the producer’s authorization to write to the topic.
This scenario looks at Confluent Cloud metrics from the Metrics API and client metrics from the client application’s MBean object kafka.producer:type=producer-metrics,client-id=producer-1.
Introduce failure scenario
Create an ACL that denies the service account permission to write to any topic, inserting your service account ID instead of
sa-123456:confluent kafka acl create --service-account sa-123456 --operation write --topic '*' --deny
Diagnose the problem
From your web browser, navigate to the Grafana dashboard at http://localhost:3000 and log in with the username
adminand passwordpassword.Navigate to the
Producer Client Metricsdashboard. Wait two minutes and then observe:The top-level panel with
Record error rate(record-error-rate) should turn red, a major indication something is wrong.Throughput, for example
Outgoing byte rate(outgoing-byte-rate), shows the producer is successfully sending messages to the broker. This is technically correct: the producer is sending the batch of records to the cluster but they are not being written to the broker’s log because of lack of authorization.
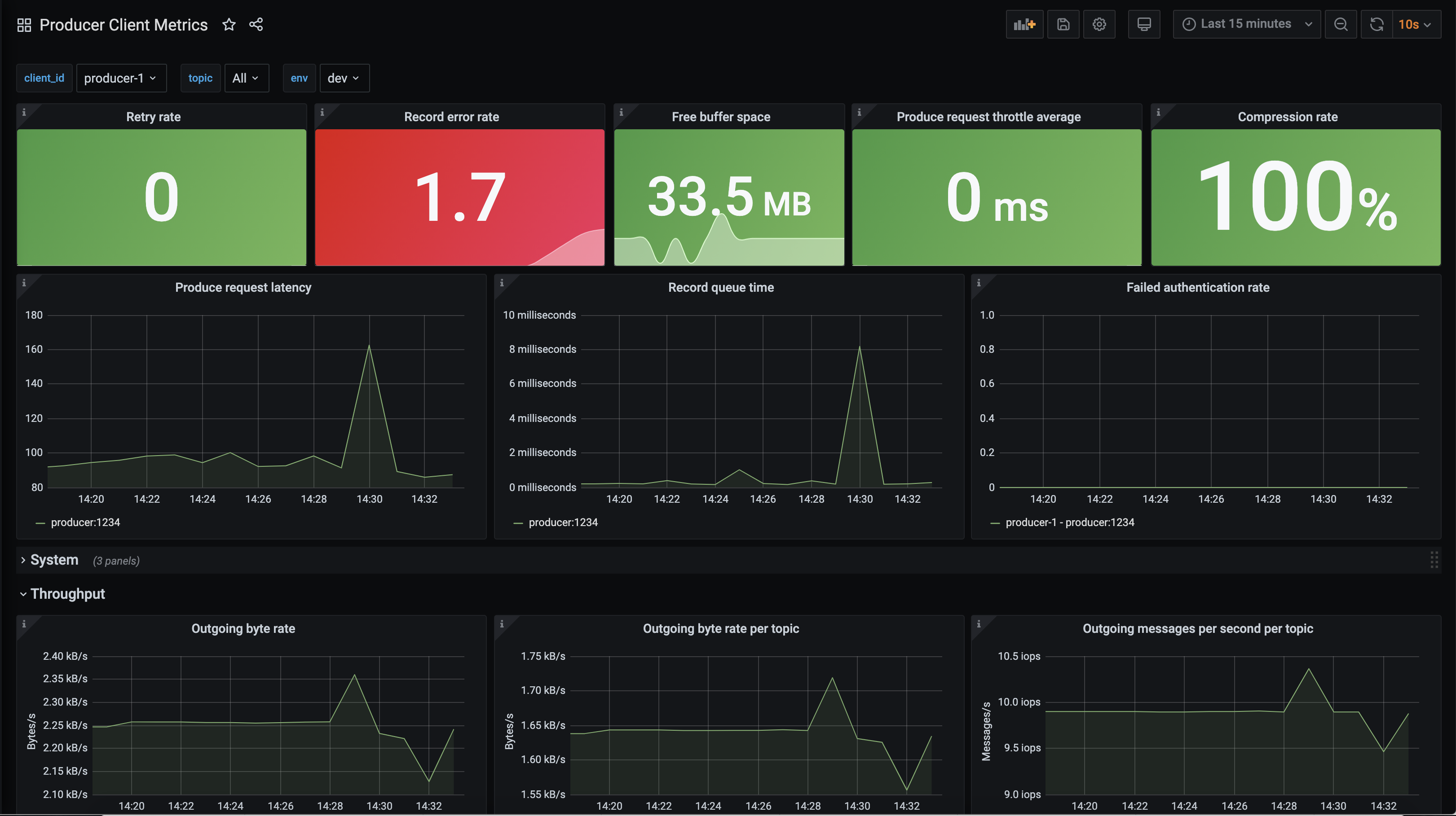
Check the status of the Confluent Cloud cluster, specifically that it is accepting requests. Navigate to the
Confluent Clouddashboard.In the
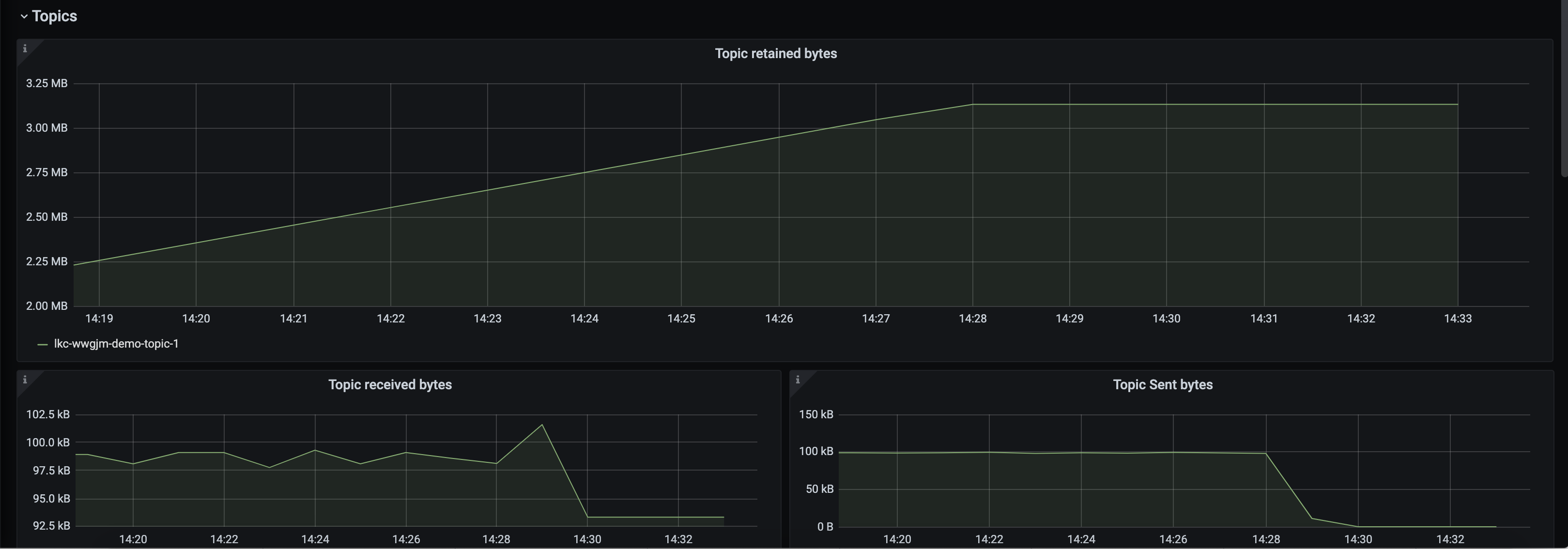
Confluent Clouddashboard, look at the top panels, they should all be green, which means the cluster is operating safely within its resources.Change the topics filter to show only
demo-topic-1. Observe:Topic received bytes(io.confluent.kafka.server/received_bytes) is still high because Confluent Cloud is still receiving the records and using network bandwidth, before they get denied due to authorization errors.Topic retained bytes(io.confluent.kafka.server/retained_bytes) has flattened because the records sent by the producer are not getting written to the log.Topic sent bytes(io.confluent.kafka.server/sent_bytes), which are the records sent to the consumer, has dropped to zero because there are no new records to send.
Check the producer logs for more information about what is going wrong. Use the following Docker command to get the producer logs:
docker compose logs producer
Verify that you see log messages similar to the following:
org.apache.kafka.common.errors.TopicAuthorizationException: Not authorized to access topics: [demo-topic-1]
The logs provide a clear picture of what is going on:
org.apache.kafka.common.errors.TopicAuthorizationException. This was expected because the failure scenario you introduced removed the ACL that permitted the service account to write to the topic.View the source code that catches this exception, ccloud-observability/src, using a
Callback().producer.send(new ProducerRecord<String, PageviewRecord>(topic, key, record), new Callback() { @Override public void onCompletion(RecordMetadata m, Exception e) { if (e != null) { e.printStackTrace(); } else { System.out.printf("Produced record to topic %s%n", topic); } } });
Resolve failure scenario
Delete the preceding ACL that denied the service account permission to write to any topic. Insert your service account ID instead of
sa-123456:confluent kafka acl delete --service-account sa-123456 --operation write --topic '*' --deny
Verify that the
org.apache.kafka.common.errors.TopicAuthorizationExceptionlog messages stopped in theproducercontainer.docker compose logs producer
Consumer client scenarios
The dashboard and scenarios in this section use client metrics from a Java consumer. The same principles can be applied to any other non-Java clients: they generally offer similar metrics.
The source code for the client can be found in the ccloud-observability/src directory. The client uses default configurations, which is not a best practice for production use cases. This Java consumer continues to consume the same message until the process is interrupted. The content of the message is not important here. In these scenarios, the focus is on the change in client metric values.
Increasing consumer lag
Consumer lag is a tremendous performance indicator. It tells you the offset difference between the producer’s last produced message and the consumer group’s last commit. If you are unfamiliar with consumer groups or concepts like committing offsets, see this Kafka Consumer documentation.
A large consumer lag, or a quickly growing lag, indicates that the consumer is not able to keep up with the volume of messages on a topic. For more information about monitoring consumer lag, see Monitor Kafka Consumer Lag in Confluent Cloud.
This scenario looks at metrics from various sources. Consumer lag metrics are pulled from the kafka-lag-exporter container, a Scala open-source project that collects data about consumer groups and presents them in a Prometheus scrapable format. Metrics about Confluent Cloud cluster resource usage are pulled from the Metrics API endpoints. Consumer client metrics are pulled from the client application’s MBean object kafka.consumer:type=consumer-fetch-manager-metrics,client-id=<client_id>.
Introduce failure scenario
By default one consumer and one producer are running. Change this to one consumer and five producers to force the condition where the consumer cannot keep up with the rate of messages being produced, which causes an increase in consumer lag. Scale the containers with the following command:
docker compose up -d --scale producer=5
This produces the following output:
ccloud-exporter is up-to-date kafka-lag-exporter is up-to-date node-exporter is up-to-date grafana is up-to-date prometheus is up-to-date Starting ccloud-observability_producer_1 ... done Creating ccloud-observability_producer_2 ... done Creating ccloud-observability_producer_3 ... done Creating ccloud-observability_producer_4 ... done Creating ccloud-observability_producer_5 ... done Starting ccloud-observability_consumer_1 ... done
Diagnose the problem
Open Grafana and log in with the username
adminand passwordpassword.Navigate to the
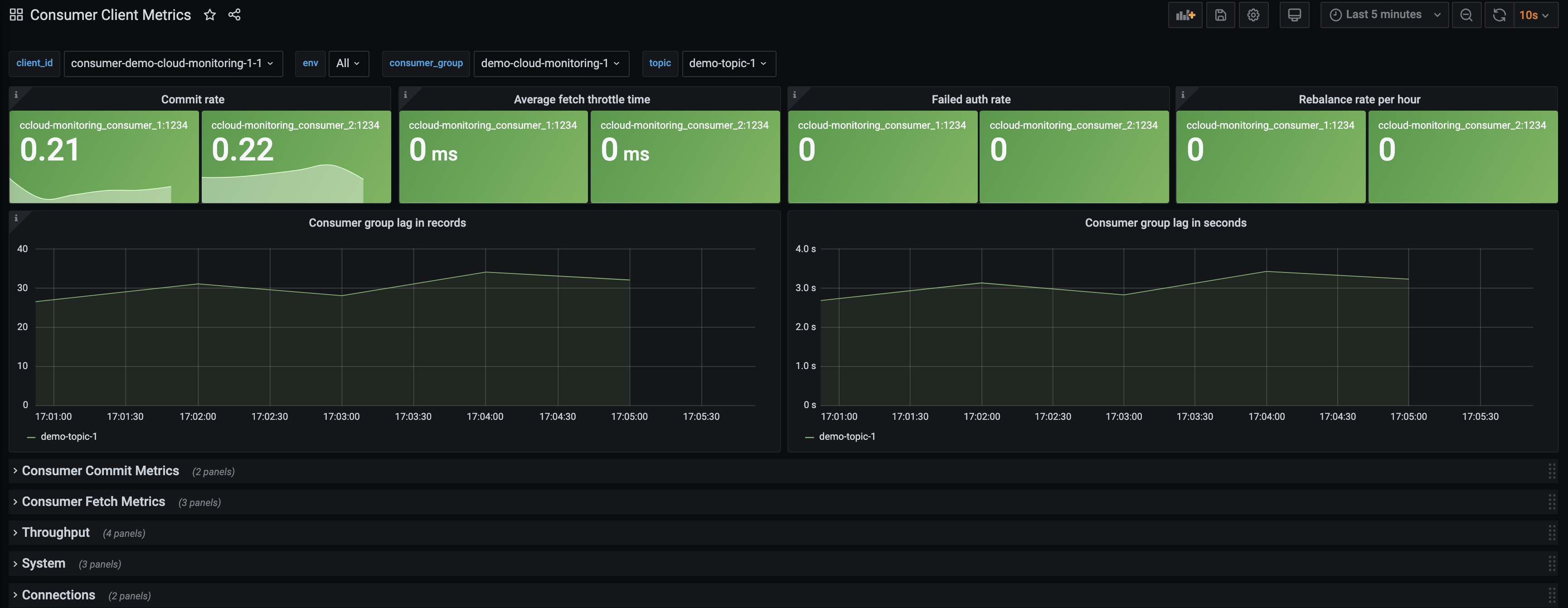
Consumer Client Metricsdashboard. Wait two minutes and then observe:An upward trend in
Consumer group lag in records.Consumer group lag in secondshas a less dramatic increase. Both indicate that the producer is creating more messages than the consumer can quickly fetch. These metrics are derived from thekafka-lag-exportercontainer.

An increase in
Fetch request rate(fetch-total) andFetch size avg(fetch-size-avg) in theConsumer Fetch Metricstab, indicating the consumer is fetching more often and larger batches.
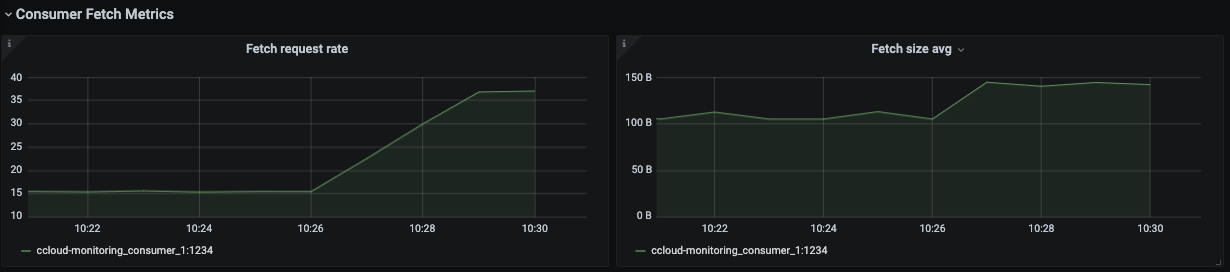
All the graphs in the
Throughputare indicating the consumer is processing more bytes and records.
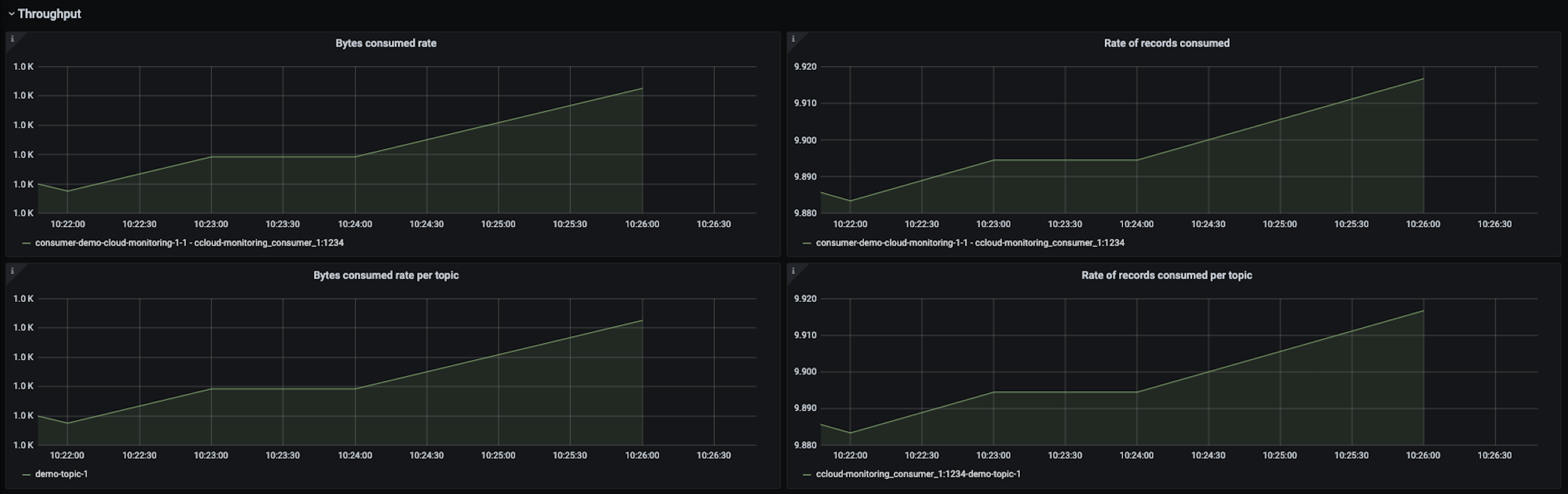
Note
If a client is properly tuned and has adequate resources, an increase in throughput metrics or fetch metrics does not necessarily mean the consumer lag increases.
Another view of consumer lag can be found in Confluent Cloud. Open the Cloud Console, navigate to the “Consumers” section, and click the
demo-cloud-observability-1consumer group. This page updates periodically; within two minutes you should see a steady increase in the offset lag.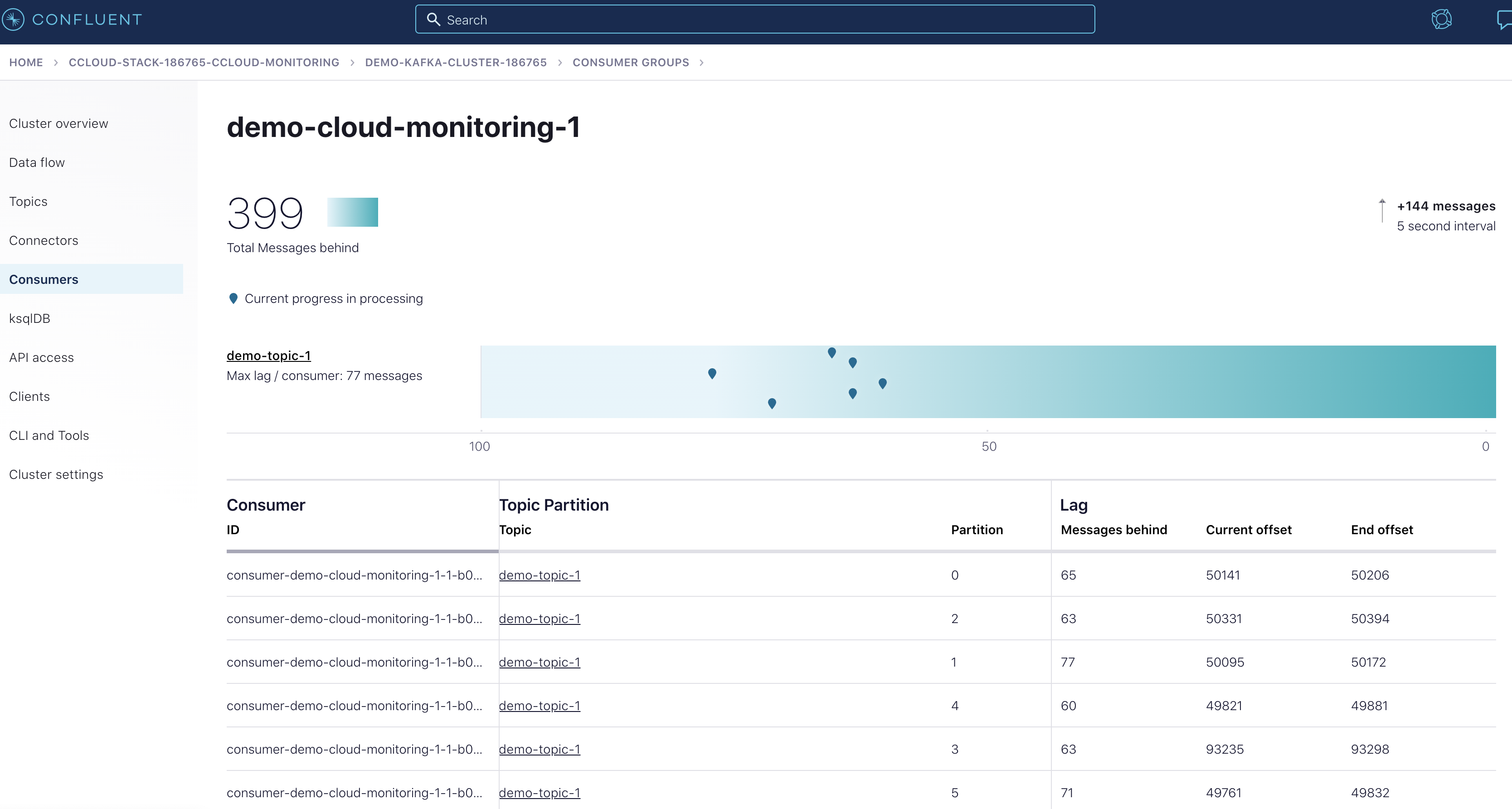
This provides a snapshot in time, but it lacks the historical view that the
Consumer Client Metricsdashboard provides.You can also observe the current consumer lag through the command-line tool if you have Confluent Platform installed.
kafka-consumer-groups --bootstrap-server $BOOTSTRAP_SERVERS --command-config $CONFIG_FILE --describe --group demo-cloud-observability-1
This produces something similar to the following:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID demo-cloud-observability-1 demo-topic-1 0 48163 48221 58 consumer-demo-cloud-observability-1-1-b0bec0b5-ec84-4233-9d3e-09d132b9a3c7 /10.2.10.251 consumer-demo-cloud-observability-1-1 demo-cloud-observability-1 demo-topic-1 3 91212 91278 66 consumer-demo-cloud-observability-1-1-b0bec0b5-ec84-4233-9d3e-09d132b9a3c7 /10.2.10.251 consumer-demo-cloud-observability-1-1 demo-cloud-observability-1 demo-topic-1 4 47854 47893 39 consumer-demo-cloud-observability-1-1-b0bec0b5-ec84-4233-9d3e-09d132b9a3c7 /10.2.10.251 consumer-demo-cloud-observability-1-1 demo-cloud-observability-1 demo-topic-1 5 47748 47803 55 consumer-demo-cloud-observability-1-1-b0bec0b5-ec84-4233-9d3e-09d132b9a3c7 /10.2.10.251 consumer-demo-cloud-observability-1-1 demo-cloud-observability-1 demo-topic-1 1 48097 48151 54 consumer-demo-cloud-observability-1-1-b0bec0b5-ec84-4233-9d3e-09d132b9a3c7 /10.2.10.251 consumer-demo-cloud-observability-1-1 demo-cloud-observability-1 demo-topic-1 2 48310 48370 60 consumer-demo-cloud-observability-1-1-b0bec0b5-ec84-4233-9d3e-09d132b9a3c7 /10.2.10.251 consumer-demo-cloud-observability-1-1
Again the downside of this view is the lack of historical context that the
Consumer Client Metricsdashboard provides.A top-level view of the Confluent Cloud cluster that reflects an increase in bytes produced and bytes consumed can be viewed in the Confluent Cloud dashboard in the panels highlighted in the following image.
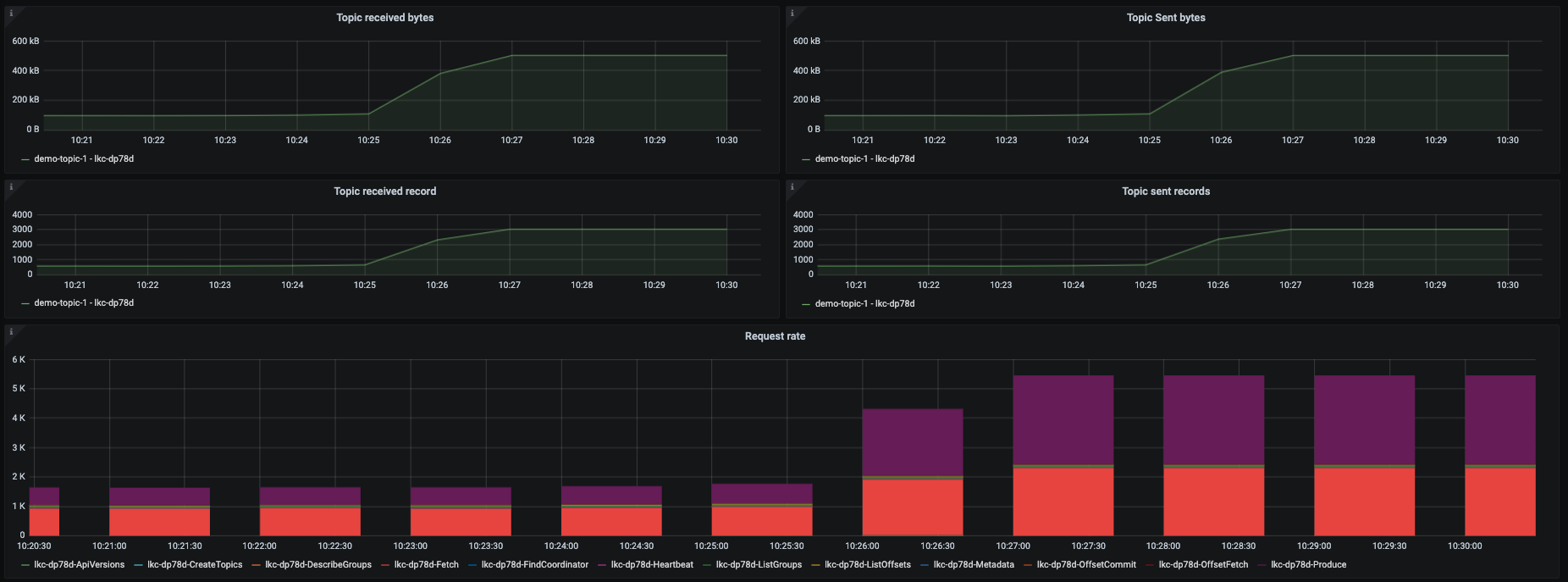
The consumer logs don’t show that the consumer is falling behind, which is why it is important to have a robust monitoring solution that covers consumer lag.
Resolve failure scenario
Start consumer-1 container, thus adding a consumer back to the consumer group, and stop the extra producers:
docker compose up -d --scale producer=1
This produces the following output:
node-exporter is up-to-date
grafana is up-to-date
kafka-lag-exporter is up-to-date
prometheus is up-to-date
ccloud-exporter is up-to-date
Stopping and removing ccloud-observability_producer_2 ... done
Stopping and removing ccloud-observability_producer_3 ... done
Stopping and removing ccloud-observability_producer_4 ... done
Stopping and removing ccloud-observability_producer_5 ... done
Starting ccloud-observability_consumer_1 ... done
Starting ccloud-observability_producer_1 ... done
General client scenarios
Confluent Cloud offers different cluster types, each with its own usage limits. This demo assumes you are running on a “basic” or “standard” cluster. Both have similar limitations. Be aware of these limits, because client requests are throttled or denied when you exceed them. If you are approaching your limits, consider upgrading your cluster to a different type.
The dashboard and scenarios in this section are powered by Metrics API data. Although hitting cloud limits would be a realistic scenario, this demo doesn’t, because you might not have enough resources on your local machine or enough network bandwidth to reach Confluent Cloud limits, and because of the potential costs you could incur. Instead, the following instructions walk you through where to look in this dashboard if you are experiencing a problem.
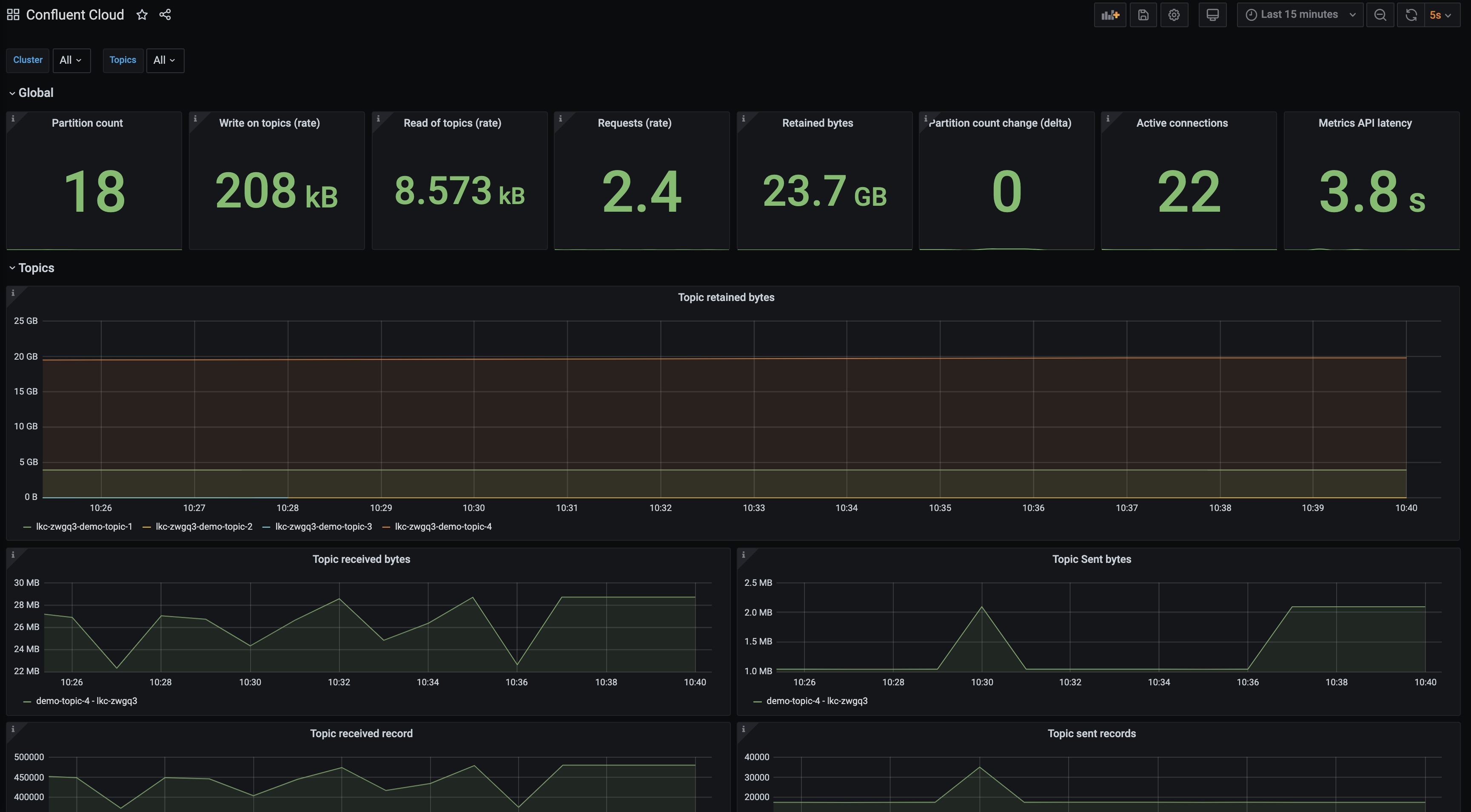
Failing to create a new partition
You might be unable to create a partition because you have reached one of the Confluent Cloud partition limits. Use the following instructions to check whether your cluster is getting close to its partition limits.
Open Grafana and use the username
adminand passwordpasswordto log in.Navigate to the Confluent Cloud dashboard.
Check the
Partition Countpanel. If this panel is yellow, you have used 80% of your allowed partitions. If it’s red, you have used 90%.A maximum number of partitions can exist on the cluster at one time, before replication. All topics that are created by you and internal topics that are automatically created by Confluent Platform components, such as ksqlDB, Kafka Streams, Connect, and Control Center, count towards the cluster partition limit.
Check the
Partition count change (delta)panel. Confluent Cloud clusters have a limit on the number of partitions that can be created and deleted in a five-minute period. This statistic provides the absolute difference between the number of partitions at the beginning and end of the five-minute period. This oversimplifies the problem. For example, at the start of a five-minute window you have 18 partitions. During the five-minute window you create a new topic with six partitions and delete a topic with six partitions. At the end of the five-minute window you still have 18 partitions, but you actually created and deleted 12 partitions.More conservative thresholds are put in place: this panel turns yellow at 50% utilization and red at 60%.
Request rate limits
Confluent Cloud has a limit on the maximum number of client requests allowed within a second. Client requests include but are not limited to requests from a producer to send a batch, requests from a consumer to commit an offset, or requests from a consumer to fetch messages. If request rate limits are hit, requests might be refused and clients might be throttled to keep the cluster stable. When a client is throttled, Confluent Cloud delays the client’s requests for produce-throttle-time-avg for producers or fetch-throttle-time-avg for consumers, both in milliseconds.
Confluent Cloud offers different cluster types, each with its own usage limits. This demo assumes you are running on a “basic” or “standard” cluster. Both have a request limit of 1,500 per second.
Open Grafana and use the username
adminand passwordpasswordto log in.Navigate to the Confluent Cloud dashboard.
Check the
Requests (rate)panel. If this panel is yellow, you have used 80% of your allowed requests. If it’s red, you have used 90%. See Grafana documentation for more information about configuring thresholds.Scroll down on the dashboard to see a breakdown of where the requests are directed in the
Request ratestacked column chart.
Reduce requests by adjusting producer batching configurations (
linger.ms), consumer batching configurations (fetch.max.wait.ms), and shut down unnecessary clients.
Clean up Confluent Cloud resources
Run the ./stop.sh script, passing the path to your stack configuration as an argument. Insert your service account ID instead of sa-123456 in the following example. Your service account ID can be found in your client configuration file path (stack-configs/java-service-account-sa-123456.config).
The METRICS_API_KEY environment variable must be set when you run this script to delete the Metrics API key that start.sh created for Prometheus to be able to scrape the Metrics API. The key was output at the end of the start.sh script, or you can find it in the .env file that start.sh created.
METRICS_API_KEY=XXXXXXXXXXXXXXXX ./stop.sh stack-configs/java-service-account-sa-123456.config
You see output like the following after all local containers and Confluent Cloud resources have been cleaned up:
Deleted API key "XXXXXXXXXXXXXXXX".
[+] Running 7/7
⠿ Container kafka-lag-exporter Removed 0.6s
⠿ Container grafana Removed 0.5s
⠿ Container prometheus Removed 0.5s
⠿ Container node-exporter Removed 0.4s
⠿ Container ccloud-observability-consumer-1 Removed 0.6s
⠿ Container ccloud-observability-producer-1 Removed 0.6s
⠿ Network ccloud-observability_default Removed 0.1s
This script will destroy all resources in java-service-account-sa-123456.config. Do you want to proceed? [y/n] y
Now using "env-123456" as the default (active) environment.
Destroying Confluent Cloud stack associated to service account id sa-123456
Deleting CLUSTER: demo-kafka-cluster-sa-123456 : lkc-123456
Deleted Kafka cluster "lkc-123456".
Deleted API key "XXXXXXXXXXXXXXXX".
Deleted service account "sa-123456".
Deleting ENVIRONMENT: prefix ccloud-stack-sa-123456 : env-123456
Deleted environment "env-123456".
Additional resources
Read Monitoring Your Event Streams: Tutorial for Observability Into Apache Kafka Clients.
See other Confluent Cloud Examples.
See Developing Client Applications on Confluent Cloud for configuring, monitoring, and optimizing Kafka client applications.
See jmx-monitoring-stacks for examples of monitoring on-premises Kafka clusters and clients.