
Data Contracts for Schema Registry on Confluent Cloud
Data contracts in Confluent Schema Registry define quality expectations, metadata, and transformation rules for schemas. They let you validate data quality (check field values, enforce constraints), tag sensitive information (PII, financial), and migrate schemas safely (upgrade/downgrade transformations using JSONata or CEL expressions).
Data contracts support quality validation rules (domain validation, field constraints), migration rules (schema evolution transformations), and metadata (tags, ownership, SLOs). They ensure data quality, consistency, and interoperability when sharing information across systems.
How To Improve Data Quality with Domain Validation Rules (video)
To learn about working with data contracts in Confluent Cloud Console, see Manage Data Contracts in Confluent Cloud.
Requirements
General requirements
Schema rules are only available on Confluent Enterprise and Confluent Cloud with the Stream Governance “Advanced” package.
Schema rules are only supported in version 7.4 or above.
Confluent Cloud requirements
To work with rules on Confluent Cloud Schema Registry:
Enable Schema Registry with the Advanced Stream Governance package, as described in Packages, Features, and Limits, and in the Choose a Stream Governance package and enable Schema Registry for Confluent Cloud.
Confluent Platform requirements
Schema rules are only available on Confluent Enterprise (not on the Community edition). To learn more about Confluent Platform packages, see Platform packages.
To enable schema rules for Confluent Enterprise, add the following to the Schema Registry properties before starting Schema Registry. The value of the property below can be a comma-separated list of class names:
resource.extension.class=io.confluent.kafka.schemaregistry.rulehandler.RuleSetResourceExtension
Limitations
Current limitations are:
Kafka Connect on Confluent Cloud does not support rules execution.
Flink SQL and ksqlDB do not support rules execution in either Confluent Platform or Confluent Cloud.
Confluent Control Center (Legacy) does not show the new properties for Data Contracts on the schema view page, in particular metadata and rules.
Schema rules are only executed for the root schema, not referenced schemas. For example, given a schema named “Order” that references another schema named “Product” which has some rules attached to it, the serialization/deserialization of the “Order” object will not execute the rules of the “Product” schema.
The non-Java clients (.NET, go, Python, JavaScript) do not yet support the DLQ Action.
JavaScript and .NET do not support schema migration rules for Protobuf due to a limitation of the underlying third-party Protobuf libraries.
Understanding the scope of a data contract
A data contract is a formal agreement between an upstream component and a downstream component on the structure and semantics of data that is in motion. A schema is only one element of a data contract. A data contract specifies and supports the following aspects of an agreement:
Structure. This is the part of the contract that is covered by the schema, which defines the fields and their types.
Integrity constraints. This includes declarative constraints or data quality rules on the domain values of fields, such as the constraint that an age must be a positive integer.
Metadata. Metadata is additional information about the schema or its constituent parts, such as whether a field contains sensitive information. Metadata can also include documentation for a data contract, such as who created it.
Rules or policies. These data rules or policies can enforce that a field that contains sensitive information must be encrypted, or that a message containing an invalid age must be sent to a dead letter queue.
Change or evolution. This implies that data contracts are versioned, and can support declarative migration rules for how to transform data from one version to another, so that even changes that would normally break downstream components can be easily accommodated.
Keeping in mind that a data contract is an agreement between an upstream component and a downstream component, note that:
The upstream component enforces the data contract.
The downstream component can assume that the data it receives conforms to the contract.
Data contracts are important because they provide transparency over dependencies and data usage in a stream architecture. They also help to ensure the consistency, reliability, and quality of the data in motion.
The upstream component could be a Apache Kafka® producer, while the downstream component would be the Kafka consumer. But the upstream component could also be a Kafka consumer, and the downstream component would be the application in which the Kafka consumer resides. This differentiation is important in schema evolution, where the producer may be using a newer version of the data contract, but the downstream application still expects an older version. In this case the data contract is used by the Kafka consumer to mediate between the Kafka producer and the downstream application, ensuring that the data received by the application matches the older version of the data contract, possibly using declarative transformation rules to massage the data into the desired form.
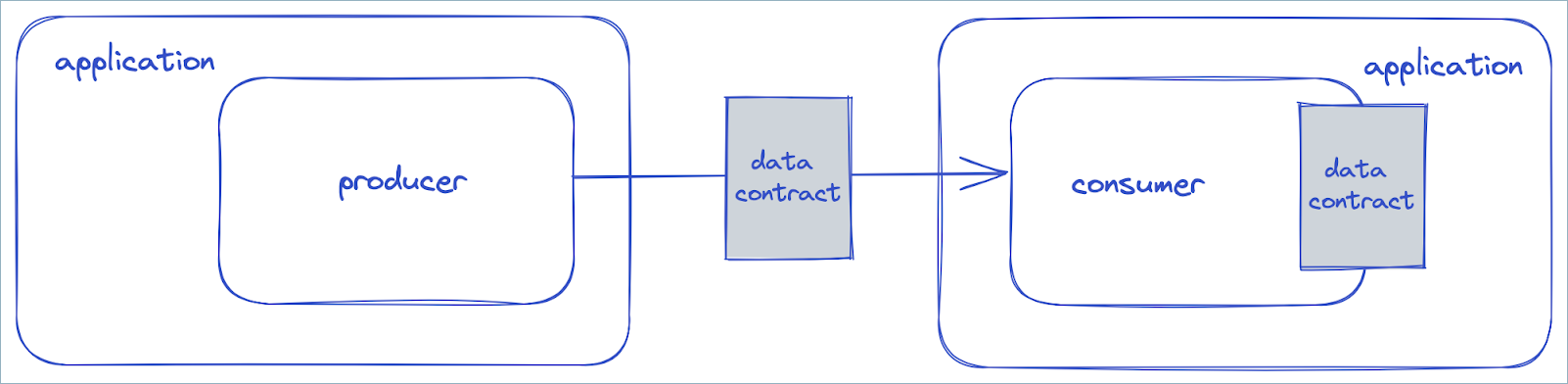
In the diagram above, the producer may be using version 2 of the data contract, yet the application in which the consumer resides expects version 1 of the data contract. In this case the consumer will use a migration rule to transform the data so that it conforms to version 1.
To support the five aspects of a data contract mentioned above, Schema Registry has been enhanced with tags, metadata, and rules.
Metadata properties
A data contract can be enhanced with arbitrary metadata properties.
{
"schema": "...",
"metadata": {
"properties": {
"owner": "Bob Jones",
"email": "bob@acme.com"
}
},
"ruleSet": ...
}
Rules
Rules can be used to specify integrity constraints or data policies in a data contract. Rules have several properties.
name- a user-defined name that can be used to reference the ruledoc- an optional descriptionkind- either CONDITION or TRANSFORMtype- the type of rule, which invokes a specific rule executor, such as Google Common Expression Language (CEL) or JSONata.mode- modes can be grouped as follows:Migration rules can be specified for an UPGRADE, DOWNGRADE, or both (UPDOWN). Migration rules are used during complex schema evolution.
Domain rules can be specified during serialization (WRITE), deserialization (READ) or both (WRITEREAD). Domain rules can be used to transform the domain values in a message payload.
tags- the tags to which the rule applies, if anyparams- a set of static parameters for the rule, which is optional. These are key-value pairs that are passed to the rule.expr- the body of the rule, which is optionalonSuccess- an optional action to execute if the rule succeeds, otherwise the built-in action type NONE is used. For UPDOWN and WRITEREAD rules, one can specify two actions separated by commas, such as “NONE,ERROR” for a WRITEREAD rule. In this case NONE applies to WRITE and ERROR applies to READ.onFailure- an optional action to execute if the rule fails, otherwise the built-in action type ERROR is used. For UPDOWN and WRITEREAD rules, one can specify two actions separated by commas, as mentioned above.
Every rule executor must implement a method named type() that returns a string. When a rule is specified in a schema, the client, during serialization or deserialization, checks to determine if an appropriate rule executor for the given rule type has been configured on the client. If so, the rule executor is used to run the rule.
Data quality rules
One of the built-in rule types is CEL, which supports data quality rules. The CEL rule type uses the Google Common Expression (CEL) language. To import the CEL rule executor, include the following dependency:
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-rules</artifactId>
<version>7.4.0</version>
</dependency>
Tip
Make sure that kafka-schema-rules matches the serializer version (for example, kafka-avro-serializer) and that these are both v.7.4 or above, as detailed in General requirements.
Next, configure the Java client to use this executor. The CEL rule executor will register itself using the “CEL” rule type. Next, you need to associate a CEL rule with the schema. For example, suppose you want to validate that the ssn field is only 9 characters long before serializing a message. You can use a schema with the rule below, where the message is passed to the rule as a variable with the name message:
{
"schema": "...",
"ruleSet": {
"domainRules": [
{
"name": "checkSsnLen",
"kind": "CONDITION",
"type": "CEL",
"mode": "WRITE",
"expr": "size(message.ssn) == 9"
}
]
}
}
Note that the example gives the rule the same name (checkSsnLen) as that passed to the rule.executors property. If you don’t use the same name, the client will use any executor that is registered for the given rule type on the client. However, it’s often useful to use the same name if you want to configure several rules of the same type (but with different names) differently.
During registration, if the schema is omitted above, then the ruleset will be attached to the latest schema in the subject. After registration, you need to specify auto.register.schemas=false and use.latest.version=true on the client.
Now that you’ve set up a data quality rule, whenever a message is sent that has an ssn field that is not 9 characters in length, the serializer will throw an exception. Alternatively, if the validation fails, you can have the message sent to a dead-letter queue. Note that the action type “DLQ” is specified below. For the bidirectional rules (WRITEREAD, UPDOWN), you can specify a comma-separated pair of action types if needed.
{
"schema": "...",
"ruleSet": {
"domainRules": [
{
"name": "checkSsnLen",
"kind": "CONDITION",
"type": "CEL",
"mode": "WRITE",
"expr": "size(message.ssn) == 9",
"params": {
"dlq.topic": "bad-data"
},
"onFailure": "DLQ"
}
]
}
}
Similar to rule executors, every rule action must implement a method named type() that returns a string.
When using a dead-letter queue to validate a record value, if the validation fails, you will usually want to capture both the record key and the record value. However, the record key is not passed to the serializer or deserializer that is validating the record value. To capture the record key, you must specify a “wrapping” serializer or deserializer for the record key that will capture the key and make it available to the serializer or deserializer for the record value. So if the record key is a simple string, instead of specifying:
key.serializer=org.apache.kafka.common.serialization.StringSerializer
Instead, specify:
key.serializer=io.confluent.kafka.serializers.WrapperKeySerializer
wrapped.key.serializer=org.apache.kafka.common.serialization.StringSerializer
To learn more about CEL, see https://github.com/google/cel-spec and Understanding CEL in Data Contract Rules.
Field-Level transforms
Field-level transforms can also be specified using the Google Common Expression Language (CEL). This is accomplished with a rule executor that transforms field values in a message, using a rule executor of type CEL_FIELD. To use this executor, include the following dependency:
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-rules</artifactId>
<version>current</version>
</dependency>
The CEL field level rule executor will register itself using the “CEL_FIELD” rule type. The rule expression can be applied to multiple fields, but those fields must be of the same type. To specify the applicable fields for the rule expression, we use a guard, which is a CEL boolean expression. So the complete rule expression is of the form:
<CEL expr for guard> ; <CEL expr for transformation>
Suppose you want to provide a default value for a field if it is empty. You can use a schema with the rule below, where field name is passed as name, the field value is passed as value, and the field type is passed as typeName. Note that the expr below is only applied to the field named occupation.
{
"schema": "...",
"ruleSet": {
"domainRules": [
{
"name": "populateDefault",
"kind": "TRANSFORM",
"type": "CEL_FIELD",
"mode": "WRITE",
"expr": "name == 'occupation' ; value == '' ? 'unspecified' : value"
}
]
}
}
Alternatively, you can specify a guard of the form typeName == 'STRING' to apply the rule expression to all string fields, such as in the following:
{
"schema": "...",
"ruleSet": {
"domainRules": [
{
"name": "populateDefault",
"kind": "TRANSFORM",
"type": "CEL_FIELD",
"mode": "WRITE",
"expr": "typeName == 'STRING' ; value == '' ? 'unspecified' : value"
}
]
}
}
Note
Only primitive types (string, bytes, int, long, float, double, boolean) are supported for field transformations. Enums are not supported.
Event-condition-action rules
When using conditions, one can model arbitrary Event-Condition-Action (ECA) rules by specifying an action for onSuccess to use when the condition is true, and an action for onFailure to use when the condition is false. The action type for onSuccess defaults to the built-in action type NONE, and the action type for onFailure defaults to the built-in action type ERROR. You can explicitly set these values to NONE, ERROR, DLQ, or a custom action type. For example, you might want to implement an action to send an email whenever an event indicates a credit card is about to expire.
To implement a custom action type, implement a RuleAction interface and then register the action as follows:
rule.actions=myRuleName # a comma-separated list of names
rule.actions.myRuleName.class=com.myorg.MyCustomAction
rule.actions.myRuleName.param.myparam1=value1
rule.actions.myRuleName.param.myparam2=value2
The RuleAction interface looks as follows:
public interface RuleAction extends RuleBase {
String type();
void run(RuleContext ctx, Object message, RuleException ex)
throws RuleException;
}
Complex schema evolution
Schema Registry is used to serve and maintain a versioned history of schemas. It also supports schema evolution, by only allowing schemas to evolve according to the configured compatibility settings. A versioned schema history is called a subject, and the compatibility rules enforce a subject-schema constraint, only allowing the schema in a subject to evolve in a manner that does not break clients.
But what if you want to evolve the schema in an incompatible manner without breaking clients? Such a scenario requires some form of data migration, and there are two possible solutions for a migration:
Inter-topic migrations: Set up a new Kafka topic and translate the topic data from the old format in the old topic to the new format in the new topic.
Intra-topic migrations: Use transformations when consuming from a topic to translate the topic data from the old format to the new format.
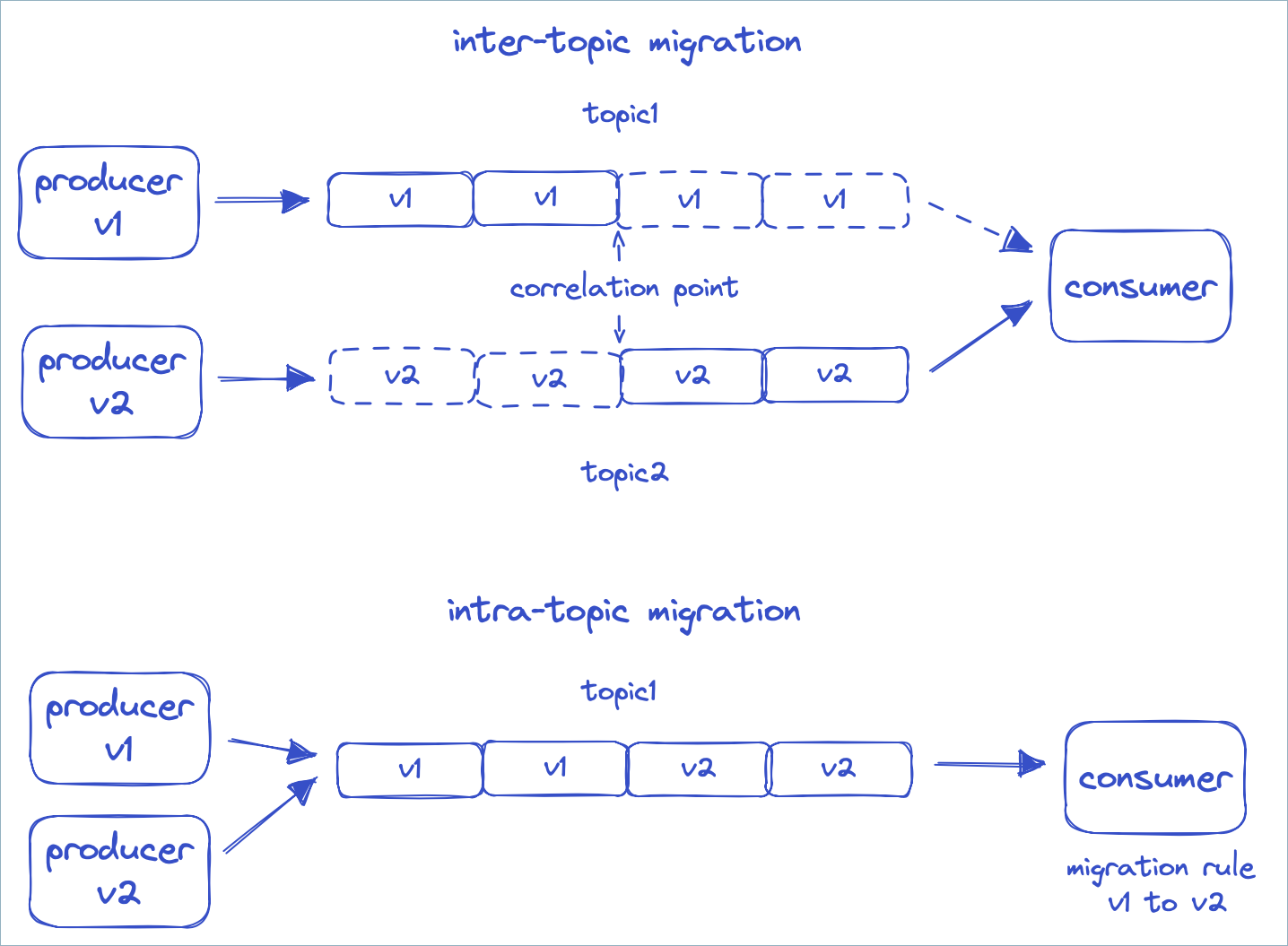
The complexity with the first approach is in switching consumers from reading the old topic to the new topic in a way that does not skip data or cause duplicate processing. To do this properly, a correlation would need to be established between the offsets of the two topics, and the consumer would need to start reading from the correct correlation point in the new topic. In addition, if something goes wrong you might want the ability to switch back to the old topic, again using the correct correlation point.
With the second option, the client does not need to be switched over to a different topic, but instead continues to read from the same topic, and a set of declarative migration rules will massage the data into the form that the consumer expects. With such declarative migration rules, we can support a system in which producers are separately using versions 1, 2, and 3 of a schema, which are all incompatible, and consumers that expect versions 1, 2, or 3 each see a message transformed to the desired version, regardless of which version the producer sent. This is often a cleaner and simpler solution for complex schema evolution that was not available with Schema Registry until now, with the release of Confluent Platform 7.4.
Before discussing how to use declarative migration rules, the next sections cover a few features that were added to Schema Registry in order to support complex schema evolution.
Application major versioning
The current versioning scheme in Schema Registry is a monotonically increasing sequence of numbers. If you want to identify when a breaking or incompatible change occurs in the schema history, you can use the recently added metadata property of the schema object. The name “application.major.version” below is arbitrary, you can call it just “major.version” for example.
{
"schema": "...",
"metadata": {
"properties": {
"application.major.version": "2"
}
},
"ruleSet": ...
}
You can then specify that a consumer only use the latest schema of a specific major version.
auto.register.schemas=false
use.latest.with.metadata=application.major.version=2
latest.cache.ttl.sec=300
The above example also specifies that the client should check for a new latest version every 5 minutes. This TTL configuration can also be used with the use.latest.version=true configuration.
Configuration enhancements
The compatibility level in Schema Registry can be set at the global level, or at the level of an individual subject. This setting is achieved by using a configuration object. Previously, the only field in the configuration object was for the compatibility level. The configuration object has been enhanced with the following properties;
compatibilityGroup- Only schemas that belong to the same compatibility group will be checked for compatibility.defaultMetadata- Default value for the metadata to be used during schema registration.overrideMetadata- Override value for the metadata to be used during schema registration.defaultRuleSet- Default value for the ruleSet to be used during schema registration.overrideRuleSet- Override value for the ruleSet to be used during schema registration.
Example: Use overrideMetadata to group schemas by application major version
For example, when registering a schema, schema metadata is initialized by:
first, taking the default value
then, merging the metadata from the schema on top of it
finally, merging the override value for the final result
If the schema does not specify metadata, then during the second step, the schema will use the metadata from the previous version if it exists.
By setting the “overrideMetadata” with the following value, you will ensure that every schema has an “application.major.version” of “2” when it is registered. This allows you to not have to explicitly pass this metadata value with every schema during registration. Also, by specifying below that the “compatibilityGroup” is “application.major.version”, only schemas that have the same value for “application.major.version” will be compared against one another during compatibility checks.
{
"compatibilityGroup": "application.major.version",
"overrideMetadata": {
"properties": {
"application.major.version": "2"
}
}
}
Example: Specify a global rule for a metadata tag for a given schema
You can register a ruleset related to a metadata tag globally without attaching it to a subject. For example, the provided tag PII results in transformation of all PII tagged fields regardless of topic, schema, and field name. You can create the same effect with custom rules.
Here is an example of using a curl command to set a global rule that will be injected in every new schema created after the global rule is set:
curl --location --request PUT '<SR_URL>/config' \
--header 'Accept: application/vnd.schemaregistry.v1+json, application/vnd.schemaregistry+json, application/json' \
--header 'Content-Type: application/json' \
--header 'Authorization: ••••••' \
--data '{
"defaultRuleSet": {
"domainRules": [
{
"name": "maskPII",
"doc": "Mask all PII tagged fields",
"kind": "TRANSFORM",
"mode": "WRITE",
"type": "CEL_FIELD",
"tags": [
"PII"
],
"expr": "\"XXXXX\"",
"onSuccess": "NONE",
"onFailure": "ERROR",
"disabled": false
}
]
}
}
'
Migration rules
How to Evolve your Schemas with Migration Rules (video)
With the above configurations, you can now pin a consumer to a specific application major version, and ensure that compatibility checks only happen as long as the application major version does not change.
When you introduce a schema that belongs to a new major version, you must attach migration rules to the schema to indicate how to transform the message from the previous major version to the new major version (for new consumers reading old messages) and how to transform the message from the new major version to the previous major version (for old consumers reading new messages). If a consumer encounters a schema with a major version that is two or more versions away, such as going from major version 1 to 3 (or from 3 to 1), then it will run migration rules transitively, in this case from 1 to 2, and then from 2 to 3.
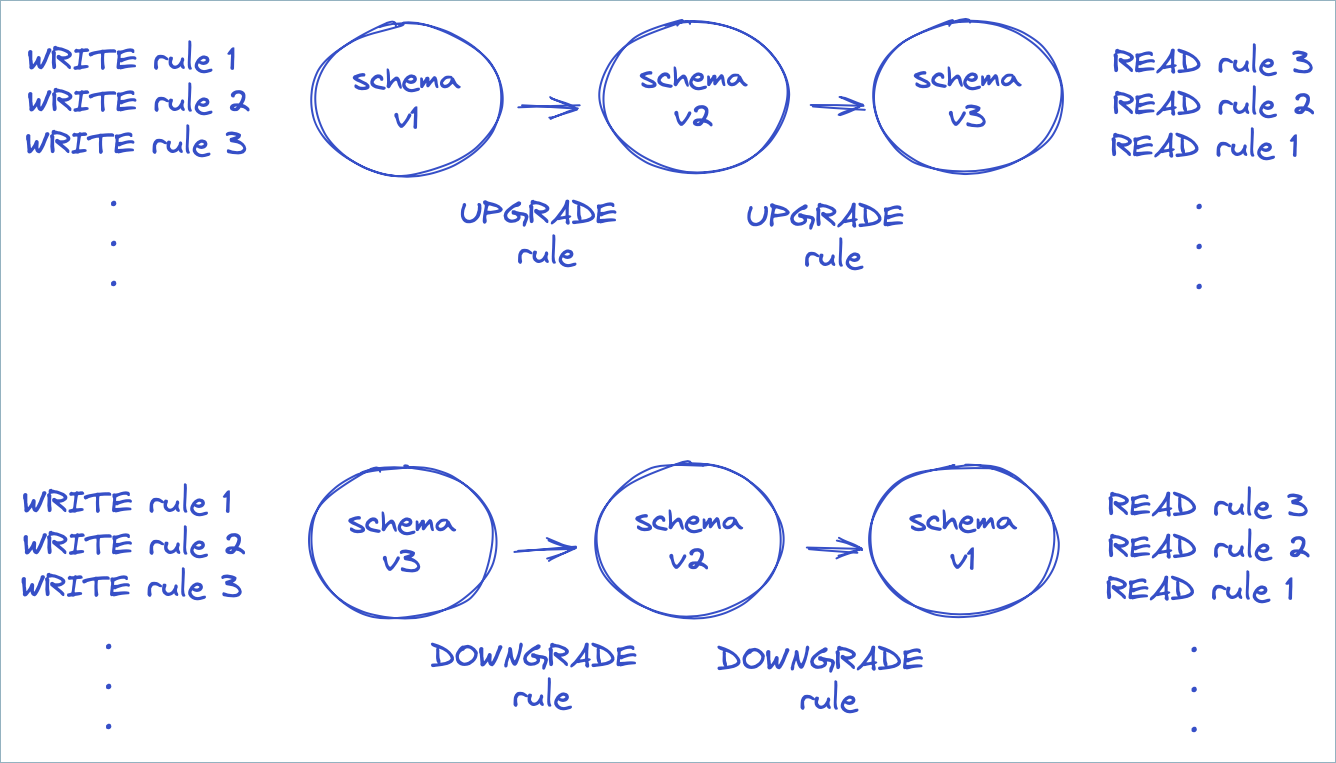
In the diagram above, the producer executes the rules applicable to WRITE mode, while the consumer either runs rules in either UPGRADE or DOWNGRADE mode (depending on the schema version of the payload and the desired version), then executes rules applicable to READ mode. Note that the rules are executed in the reverse order during READ mode. This is to ensure any actions performed during WRITE are undone in the proper order during READ.
How do migration rules work? They take advantage of the fact that Avro, JSON Schema, and Protobuf all specify a JSON serialization format for messages. The migration rules can be specified in any declarative language that supports JSON transformations.
Declarative JSONata rules
JSONata is a sophisticated transformation language for JSON that was inspired by XPath. To use the rule executor for JSONata, include the following dependency:
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-rules</artifactId>
<version>7.4.0</version>
</dependency>
The JSONata rule executor will register itself using the “JSONATA” rule type.
Suppose you have a simple schema with an ssn field.
{
"type":"record",
"name":"MyRecord",
"fields":[{
"name":"ssn",
"type":"string",
"confluent:tags": [ "PII", "PRIVATE" ]
}]
}
We want to rename the field as “socialSecurityNumber”. Below are a set of migration rules to achieve this. In this case, you can use the JSONata function called sift to remove the field with the old name, and then use a JSON property to specify the new field.
{
"schema": "...",
"ruleSet": {
"migrationRules": [
{
"name": "changeSsnToSocialSecurityNumber",
"kind": "TRANSFORM",
"type": "JSONATA",
"mode": "UPGRADE",
"expr": "$merge([$sift($, function($v, $k) {$k != 'ssn'}), {'socialSecurityNumber': $.'ssn'}])"
},
{
"name": "changeSocialSecurityNumberToSsn",
"kind": "TRANSFORM",
"type": "JSONATA",
"mode": "DOWNGRADE",
"expr": "$merge([$sift($, function($v, $k) {$k != 'socialSecurityNumber'}), {'ssn': $.'socialSecurityNumber'}])"
}
]
}
}
The UPGRADE rule allows new consumers to read old messages, while the DOWNGRADE rule allows old consumers to read new messages. If you plan to upgrade all consumers, you can of course omit the DOWNGRADE rule.
To learn more about JSONata, see https://jsonata.org and Understanding JSONata.
Custom rules
You can enhance data quality and enforce data contracts by registering schemas with custom rules. Both Java and non-Java clients such as Python clients support custom rules.
Apply a custom rule in two ways:
Built-in CEL rules: define the rule with a Common Expression Language (CEL) expression and associate it with an Avro, JSON, or Protobuf schema. No additional code is required. The
CEL_FIELDfield-level transform described in the previous section and the Python example below both use this approach.Custom rule executors: implement the Java
RuleExecutorinterface to define a new rule type for logic that a CEL expression cannot express.
Include the kafka-schema-rules
To use custom rules, you must include the following dependency:
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-rules</artifactId>
<version>current</version>
</dependency>
RuleExecutor interface
To define your own rule type, implement the RuleExecutor interface:
public interface RuleExecutor extends RuleBase {
String type();
Object transform(RuleContext ctx, Object message) throws RuleException;
}
For rules of type CONDITION, the transform method should return a Boolean value, and for rules of type TRANSFORM, the transform method should return the transformed message.
Example function: register_schema_with_rules
The example function, register_schema_with_rules, shows how to register a schema with a custom rule in Schema Registry.
from confluent_kafka.schema_registry import SchemaRegistryClient, Schema, Rule, RuleSet
def register_schema_with_rules(schema_registry_url: str, subject_name: str, schema_str: str, rule_expression: str):
"""
Registers a schema with a custom validation rule in Confluent Schema Registry.
This function takes a schema definition and a CEL rule, registers them
with the Schema Registry under a specified subject by embedding the rule
within the Schema object itself.
Args:
schema_registry_url (str): The URL of the Schema Registry instance.
subject_name (str): The name of the subject under which to register the schema.
schema_str (str): The Avro, JSON, or Protobuf schema as a string.
rule_expression (str): A CEL (Common Expression Language) expression for the rule.
"""
schema_registry_conf = {'url': schema_registry_url}
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
# Define the rule based on the provided CEL expression
rule = Rule(name="custom_validation_rule",
doc="Custom data validation rule",
kind="CONDITION",
mode="WRITE",
type="CEL_FIELD",
expr=rule_expression,
on_failure="ERROR") # Other options: DLQ, NONE
# Create a RuleSet and add the rule
rule_set = RuleSet(domain_rules=[rule])
# Create a Schema object and pass the ruleset to the constructor
schema = Schema(schema_str, schema_type="AVRO", ruleset=rule_set) # Or JSON, PROTOBUF
# Register the schema (which now contains the ruleset internally)
schema_id = schema_registry_client.register_schema(subject_name=subject_name,
schema=schema)
print(f"Schema registered for subject '{subject_name}' with ID: {schema_id}")
print(f"Associated rule: '{rule_expression}'")
Example usage
The following example shows how to use the register_schema_with_rules function to register a user schema with a rule that ensures the age field is a positive integer.
# Schema Registry and Kafka Configuration
SCHEMA_REGISTRY_URL = "http://localhost:8081"
SUBJECT_NAME = "user-topic-value"
# Define the Avro schema
AVRO_SCHEMA = """
{
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "age", "type": "int"}
]
}
"""
# Define the CEL rule
# This rule will be applied to the 'age' field
RULE_EXPRESSION = "message.age > 0"
# Register the schema with the custom rule
register_schema_with_rules(SCHEMA_REGISTRY_URL, SUBJECT_NAME, AVRO_SCHEMA, RULE_EXPRESSION)
Generate a UUID with a custom rule executor
A CEL rule can’t generate a value such as a UUID. To populate a field with a generated value, implement a custom rule executor. The following example defines a TRANSFORM executor that fills an empty tagged field with a generated UUID on write, registers the executor, and applies it to a schema.
Implement the executor:
package io.confluent.kafka.schemaregistry.rules;
import io.confluent.kafka.schemaregistry.rules.RuleContext.FieldContext;
import io.confluent.kafka.schemaregistry.rules.RuleContext.Type;
import java.nio.charset.StandardCharsets;
import java.util.UUID;
// A field-level rule executor that overwrites the tagged field with a freshly
// generated UUID (v4). Intended for TRANSFORM rules on WRITE.
// FieldRuleExecutor is a convenience base class that implements RuleExecutor
// for field-level transforms.
public class UuidGeneratorExecutor extends FieldRuleExecutor {
public static final String TYPE = "UUID";
public UuidGeneratorExecutor() {
}
@Override
public String type() {
return TYPE;
}
@Override
public FieldTransform newTransform(RuleContext ctx) throws RuleException {
UuidGeneratorTransform transform = new UuidGeneratorTransform();
transform.init(ctx);
return transform;
}
public static class UuidGeneratorTransform implements FieldTransform {
@Override
public Object transform(RuleContext ctx, FieldContext fieldCtx, Object fieldValue)
throws RuleException {
// Only generate when the field is empty or unset, so existing ids are preserved.
if (fieldValue != null && !"".equals(fieldValue)) {
return fieldValue;
}
String uuid = UUID.randomUUID().toString();
switch (fieldCtx.getType()) {
case STRING:
return uuid;
case BYTES:
return uuid.getBytes(StandardCharsets.UTF_8);
default:
// Not a string or bytes field, so leave it unchanged.
return fieldValue;
}
}
@Override
public void close() {
}
}
}
Register the executor so the Java ServiceLoader discovers it. Create a file named io.confluent.kafka.schemaregistry.rules.RuleExecutor under src/main/resources/META-INF/services/, containing the fully qualified class name of the executor:
io.confluent.kafka.schemaregistry.rules.UuidGeneratorExecutor
Define a TRANSFORM rule on the subject that targets fields tagged UUID and runs on write:
{
"ruleSet": {
"domainRules": [
{
"name": "genId",
"kind": "TRANSFORM",
"type": "UUID",
"mode": "WRITE",
"tags": ["UUID"]
}
]
}
}
Tag the target field in the schema so the rule applies to it. For an Avro schema, add the tag to the field definition:
{"name": "id", "type": "string", "confluent:tags": ["UUID"]}
Quick start
This Quick Start shows an example of a data quality rule using an Avro schema. You’ll creates a schema with a single field “f1”, and add a data quality rule rule to ensure that the length of the field is always less than 10.
Requirements
Schema rules are only available on Confluent Enterprise (not the Community edition) and Confluent Cloud with the Stream Governance “Advanced” package.
For Confluent Cloud Schema Registry, enable the Advanced Stream Governance package, as described in Packages, Features, and Limits, and in the Choose a Stream Governance package and enable Schema Registry for Confluent Cloud.
For Confluent Platform, make sure you have Confluent Platform (Enterprise Edition) installed, and then add the following to the Schema Registry properties before starting Schema Registry. The value of the property below can be a comma-separated list of class names:
resource.extension.class=io.confluent.kafka.schemaregistry.rulehandler.RuleSetResourceExtension
Start the producer
To run the producer on Confluent Platform:
./bin/kafka-avro-console-producer \
--topic test \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--property value.schema='{"type":"record","name":"myrecord","fields":
[{"name":"f1","type":"string"}]}' \
--property value.rule.set='{ "domainRules":
[{ "name": "checkLen", "kind": "CONDITION", "type": "CEL",
"mode": "WRITE", "expr": "size(message.f1) < 10",
"onFailure": "ERROR"}]}'
{"f1": "success"}
{"f1": "this will fail"}
To run the producer on Confluent Cloud:
./bin/kafka-avro-console-producer \
--topic test \
--bootstrap-server ${BOOTSTRAP_SERVER} \
--producer.config config.properties \
--property schema.registry.url=${SR_URL} \
--property basic.auth.credentials.source=USER_INFO \
--property basic.auth.user.info=${SR_API_KEY}:${SR_API_SECRET} \
--property value.schema='{"type":"record","name":"myrecord","fields":
[{"name":"f1","type":"string"}]}' \
--property value.rule.set='{ "domainRules":
[{ "name": "checkLen", "kind": "CONDITION", "type": "CEL",
"mode": "WRITE", "expr": "size(message.f1) < 10",
"onFailure": "ERROR"}]}'
{"f1": "success"}
{"f1": "this will fail"}
where config.properties contains:
bootstrap.servers={{ BOOTSTRAP_SERVER }}
security.protocol=SASL_SSL
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='{{ CLUSTER_API_KEY }}' password='{{ CLUSTER_API_SECRET }}';
sasl.mechanism=PLAIN
client.dns.lookup=use_all_dns_ips
session.timeout.ms=45000
acks=all
In the above example for config.properties, the following best practices and requirements are implemented:
bootstrap.servers, security protocols, and credentials are required for the Apache Kafka® producer, consumer, and admin.client.dns.lookupvalue is required for Kafka clients prior to 2.6.session.timeout.msbeing included is a best practice for higher availability in Kafka clients prior to 3.0. This value is ignored whengroup.protocol=consumeris set.acks=allspecifies that the producer requires all in-sync replicas to acknowledge receipt of messages (records), and is a best practice configuration on the producer to prevent data loss.
Start the consumer
To run the consumer on Confluent Platform:
./bin/kafka-avro-console-consumer \
--topic test \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081
To run the consumer on Confluent Cloud:
./bin/kafka-avro-console-consumer \
--topic test \
--bootstrap-server ${BOOTSTRAP_SERVER} \
--consumer.config config.properties \
--property schema.registry.url=${SR_URL} \
--property basic.auth.credentials.source=USER_INFO \
--property basic.auth.user.info=${SR_API_KEY}:${SR_API_SECRET}
where config.properties contains:
bootstrap.servers={{ BOOTSTRAP_SERVER }}
security.protocol=SASL_SSL
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='{{ CLUSTER_API_KEY }}' password='{{ CLUSTER_API_SECRET }}';
sasl.mechanism=PLAIN
client.dns.lookup=use_all_dns_ips
session.timeout.ms=45000
acks=all
In the above example for config.properties, the following best practices and requirements are implemented:
bootstrap.servers, security protocols, and credentials are required for the Kafka producer, consumer, and admin.client.dns.lookupvalue is required for Kafka clients prior to 2.6.session.timeout.msbeing included is a best practice for higher availability in Kafka clients prior to 3.0. This value is ignored whengroup.protocol=consumeris set.acks=allspecifies that the producer requires all in-sync replicas to acknowledge receipt of messages (records), and is a best practice configuration on the producer to prevent data loss.
Reference
CEL rule executor
The CEL rule executor sets the following variables that are available in expressions.
message- The message
CEL_FIELD rule executor
The CEL_FIELD rule executor sets the following variables that are available in expressions.
value- Field valuefullName- Fully-qualified name of the fieldname- Field nametypeName- Name of the field type, one of STRING, BYTES, INT, LONG, FLOAT, DOUBLE, BOOLEANtags- Tags that apply to the fieldmessage- The containing message
CEL built-in functions
Both the CEL and CEL_FIELD rule executors support the following built-in string functions.
<string>.isEmail()- Test whether the string is a valid email address.<string>.isHostname()- Test whether the string is a valid hostname.<string>.isIpv4()- Test whether the string is a valid IPv4 address.<string>.isIpv6()- Test whether the string is a valid IPv6 address.<string>.isUri()- Test whether the string is a valid absolute URI.<string>.isUriRef()- Test whether the string is a valid absolute or relative URI.<string>.isUuid()- Test whether the string is a valid UUID.
JSONATA rule executor
The JSONATA rule executor supports the following configuration parameters that can be passed when specifying the executor.
jsonata.timeout.ms- Maximum execution time in millisecondsjsonata.max.depth- Maximum number of recursive calls