
Use Tiered Separation to Protect Data on Critical Workloads in Confluent Cloud
This page describes benefits, use cases, and how to get started using Cluster Linking with tiered separation of content and workloads.
Benefits of tiered separation
Modern businesses have Kafka data that is required by both business-critical applications and lower-priority workloads. Keeping business-critical, user-facing applications running smoothly is paramount to hitting business goals and raising customer satisfaction. Cluster Linking can be used to separate and safeguard your “Tier 1” and “Tier 2” applications, offering the following benefits.
Business-critical and user-facing apps are safeguarded
Your business-critical, Tier 1 applications that require high performance are safe from being throttled by your lower-priority applications features such as:
Write throughput (also known as produce or ingress)
Read throughput (also known as consume or egress)
Connection attempts
Total connections
Requests per second
High partition topics
Lower-priority apps are safeguarded
Your lower-priority, Tier 2 applications can safely produce and consume at high throughputs, connection counts, and so on, at any time, without risk of affecting sensitive workloads. This can be ideal for workloads that spike in resource utilization, such as:
Training models for machine learning or data analysis
Intense analytics
Internal-only applications
Tier 1 and Tier 2 priority workloads
For modern organizations, not all workloads are created equal. Some producers and consumers power user-facing applications. For these higher priority Tier 1 applications, maintaining high performance is key to satisfying their customers. Any consumer lag, timeouts, and so on, would create a poor user experience. However, for other workloads, high performance is not as business-critical. Lower priority, Tier 2 jobs, such as analytics jobs, internal reporting, model training, and other internal-facing workloads may be able to tolerate lower throughput and higher lag without issue.
What do you do when Tier 2 jobs spike?
But what happens when a Tier 2 job spikes in consumption, and requires more resources (throughput, connections, request count, and so on) than your Kafka cluster can offer? Throttling will kick in, affecting all consumers, even those that are user-facing and business-critical. So the demand from a Tier 2, lag-tolerant job may cause lag in Tier 1 jobs, creating a poor experience for end users.
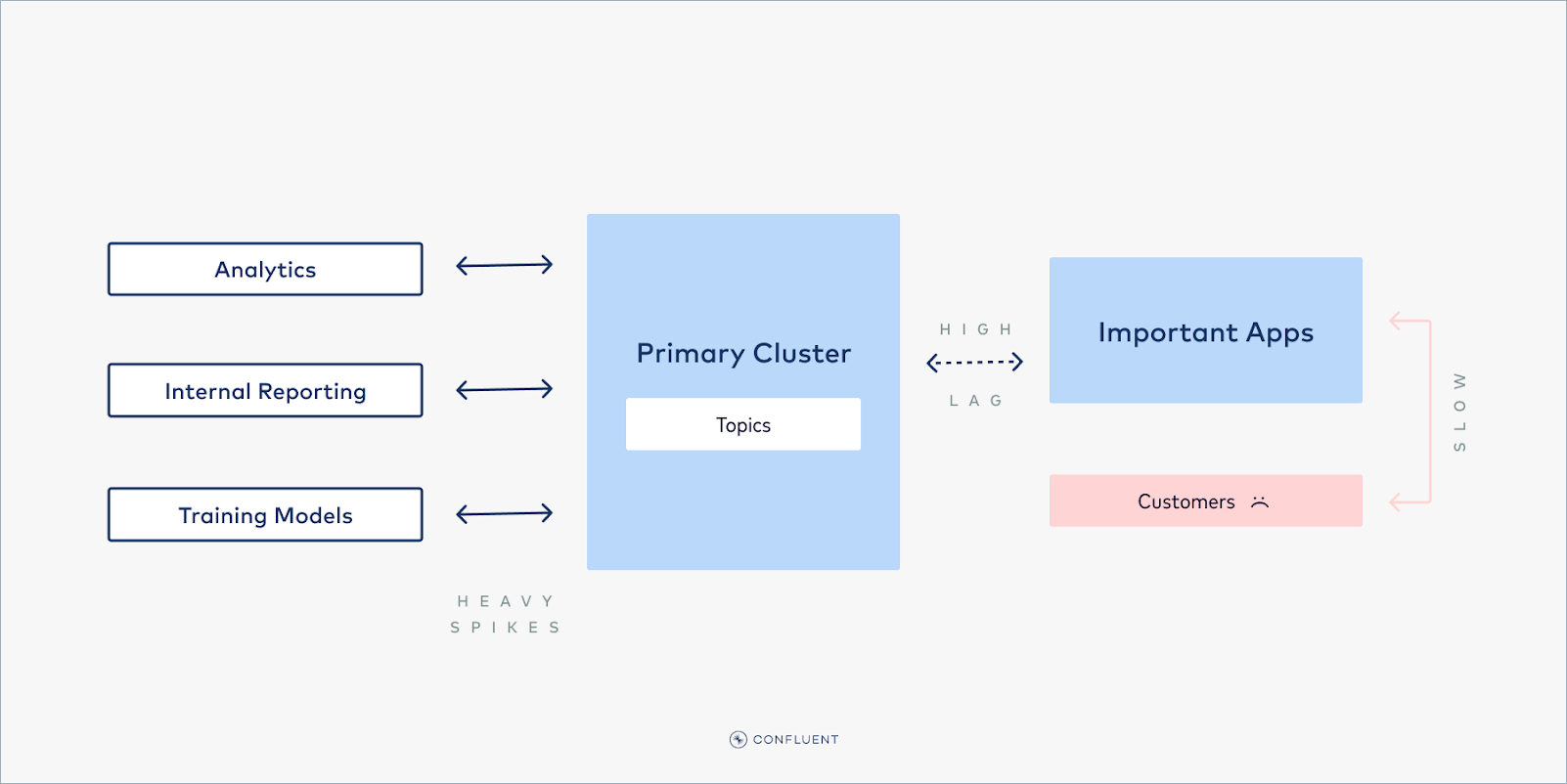
A linked, multi-cluster solution
This problem can be prevented by splitting the Kafka cluster in two: one cluster serves Tier 1 workloads, and a different cluster handles Tier 2 workloads. Producers and consumers can read off of their respective cluster, so that no matter how high the Tier 2 clients spike—such as when training a new ML model, or computing intense analytics—they can never affect the performance of the Tier 1 workloads.
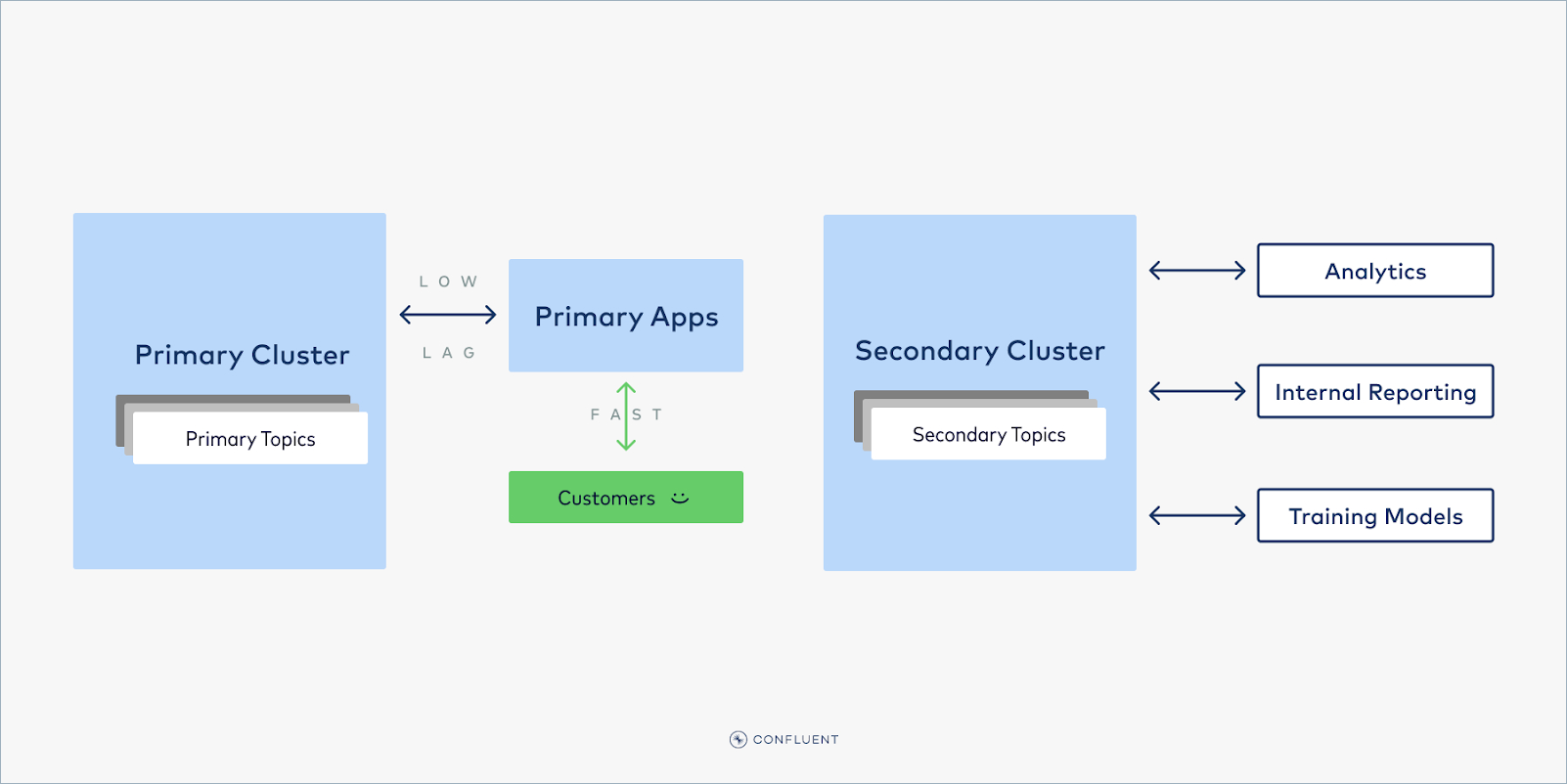
Balancing priority Tier 1 and Tier 2 data
But what about data that is needed by both Tier 1 and Tier 2 consumers? For example, your stream of orders may be required by both your user-facing web app and your internal analytics. The solution is to replicate this data with Cluster Linking. This data can be produced to the Tier 1 cluster–making it immediately available for the Tier 1 consumers–and then mirrored to the Tier 2 cluster. Cluster Linking is a fully-managed tool for copying data from one cluster to another. It creates identical, read-only mirror topics on your Tier 2 cluster, similar to read-replicas in a database, and keeps them in sync with the data being written to the Tier 1 cluster. In this way, Tier 2 consumers can consume all they want from the mirror topics, without any risk of affecting the Tier 1 workloads.
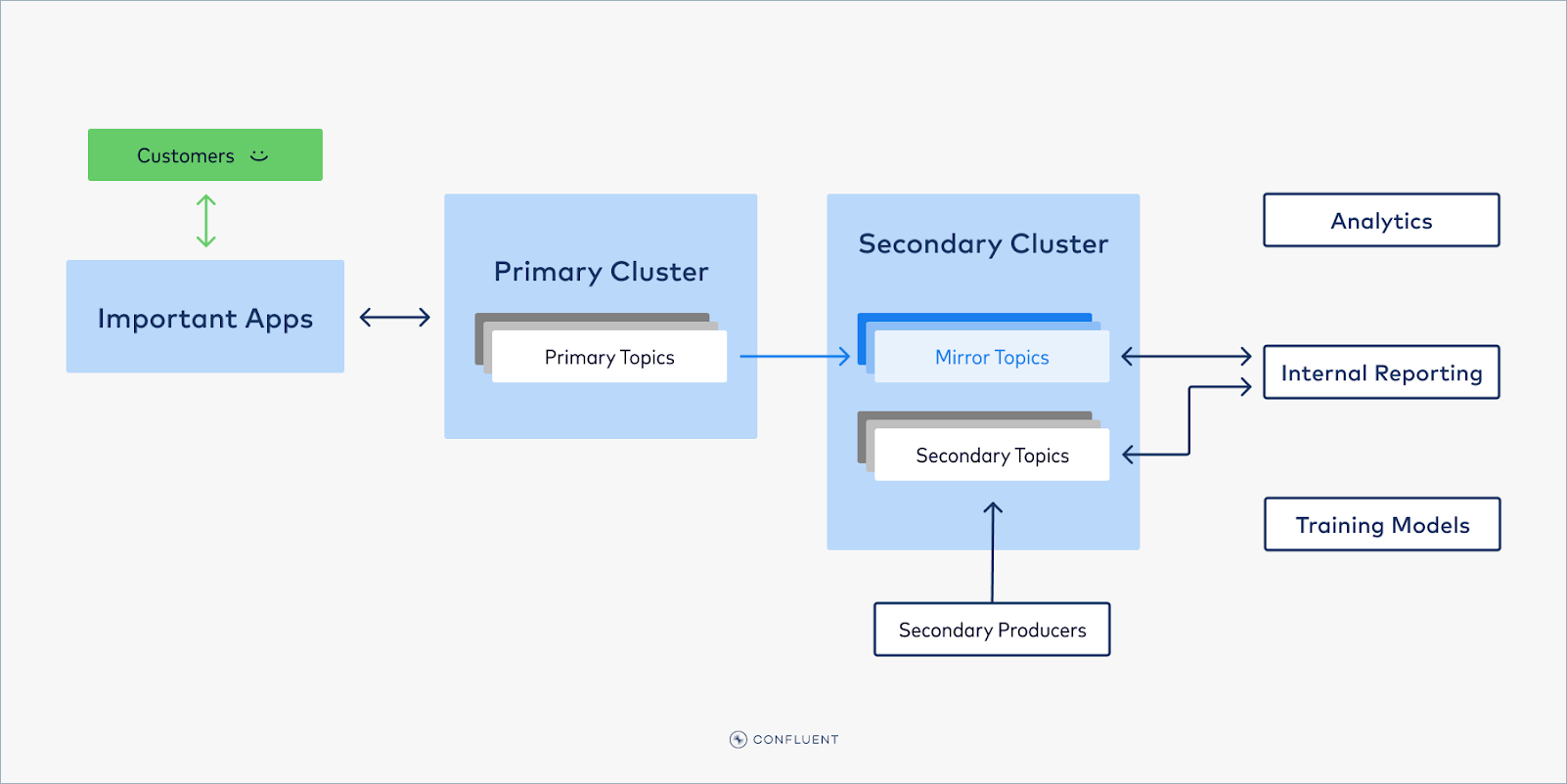
Setup and getting started
To set up a cluster link and read-replica mirror topics on a lower-priority cluster with Cluster Linking, you need:
A “Tier 1” source cluster (Confluent Cloud, Confluent Platform, or Kafka) and a “Tier 2” destination cluster (Confluent Cloud). The pair must be supported with Cluster Linking, as described in Supported cluster types.
A user or service account with CloudClusterAdmin RBAC role on the Tier 2 cluster.
A service account with one of the following sets of permissions on the Tier 1 cluster:
DeveloperRead and DeveloperManage for the topics you want to replicate, OR
The ACLs to READ and DESCRIBE-CONFIGS on the Topic(s) that you want to replicate, as described in Permissions for the cluster link to read from the source cluster in the Confluent Cloud documentation.
An API key on the Tier 1 cluster for that service account.
To see a step-by-step example of how to set up a cluster link, follow the Cluster Linking Quick Start on Confluent Cloud or the topic data sharing tutorial tutorial.