
Tableflow in Confluent Cloud
Tableflow is a Confluent Cloud feature that materializes Apache Kafka® topics as Apache Iceberg™ or Delta Lake tables. It eliminates custom data pipelines by automatically handling schematization, type conversions, schema evolution, CDC stream materialization, and catalog publishing. Tableflow tables can be read by any analytics engine—Snowflake, Databricks, BigQuery, Trino—without data duplication.
Tableflow eliminates the need for complex, costly, and error-prone custom data pipelines for ingesting, cleaning, and preparing raw data and ingesting it to data lakes and data warehouses. Tableflow automates key tasks, such as schematization, type conversions, schema evolution, Change Data Capture (CDC) stream materialization, table metadata publishing to catalogs, and table maintenance.
Tableflow introduces support for:
Iceberg: Exposing streaming data in Confluent Cloud-hosted Kafka topics as Iceberg tables.
Delta Lake: Now generally available, enabling you to explore materializing Kafka topics as Delta Lake tables in your own storage. These tables can be consumed as storage-backed external tables from Databricks.
Tableflow ensures seamless integration with catalogs and compute engines, making operational data instantly available for analytics in open table formats, like Iceberg and Delta Lake. Without requiring data duplication, Tableflow allows tables to be exposed as read-only, enabling immediate access for downstream analytics, AI workloads, and other compute processes across multiple engines.
With Confluent Cloud for Apache Flink, you can perform real-time stream processing before materializing data into Iceberg or Delta Lake tables, enabling you to shift data processing closer to the source. This “shift-left” approach ensures the data is enriched, transformed, and analytics-ready as it is ingested.
Key features
Tableflow offers the following capabilities:
Materialize Kafka topics or Flink tables as Iceberg or Delta Lake tables
Use your storage (“Bring Your Own Storage”) or Confluent Managed Storage for materialized tables
Built-in Iceberg REST Catalog (IRC)
Catalog integration with AWS Glue, Databricks Unity, Apache Polaris, and Snowflake Open Catalog
Use Avro, Protobuf, and JSON Schema as the input data format and support for schematization using Confluent Cloud Schema Registry.
Self-managed encryption key (BYOK) support for enhanced security and compliance requirements.
Client-side field level encryption (CSFLE) for materializing topics with encrypted sensitive fields (Limited Availability)
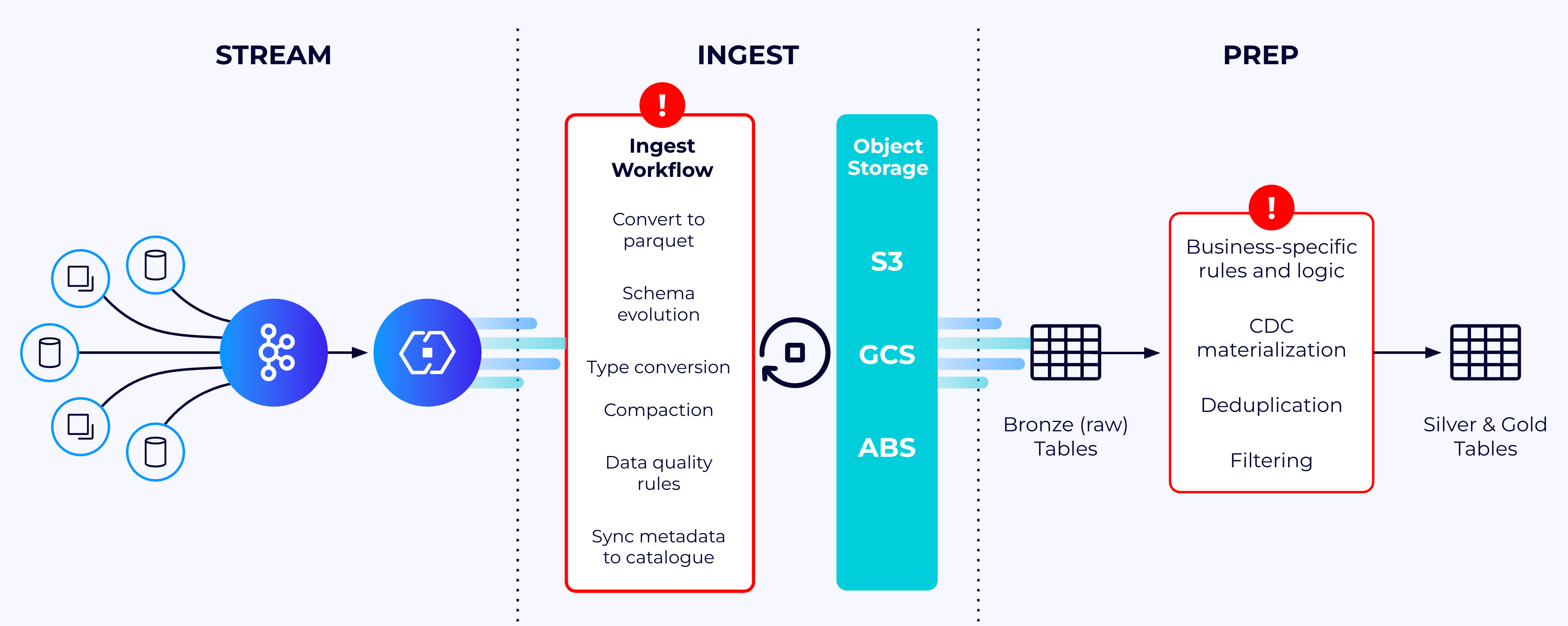
Tableflow enhances data quality and structure by managing data preprocessing and preparation automatically before materializing streaming data into Iceberg or Delta Lake tables. Below are the key automated data processing and preparation capabilities supported in Tableflow.
Type mapping and conversions
Tableflow seamlessly transforms incoming Kafka data, in Avro, JSON Schema, and Protobuf formats, into structured Parquet files, which are then materialized as Iceberg or Delta Lake tables.
Schematization and schema evolution
Tableflow leverages Confluent Cloud Schema Registry as the source of truth for defining table schemas, ensuring structured and consistent data representation in Iceberg and Delta Lake tables. Tableflow adheres to Schema Registry compatibility modes, automatically evolving schemas while maintaining compatibility.
Tableflow handles the following schema changes automatically:
Adding new columns
Removing columns
Widening column types (for example,
inttolong)
Schema changes that are not compatible with the configured Schema Registry compatibility mode require manual intervention. For more information, see Schemas with Tableflow in Confluent Cloud.
Materialization of Change Data Capture (CDC) logs
Tableflow efficiently materializes CDC logs, preserving the structure and integrity of change events from Kafka topics into Iceberg and Delta Lake tables for analytics and processing.
Table maintenance and optimizations
To maintain optimal performance, Tableflow automates table maintenance by compacting and cleaning up small files generated by continuous streaming data in object storage. This improves read performance by consolidating small files into larger, more efficient formats while also managing obsolete data.
Why Tableflow?
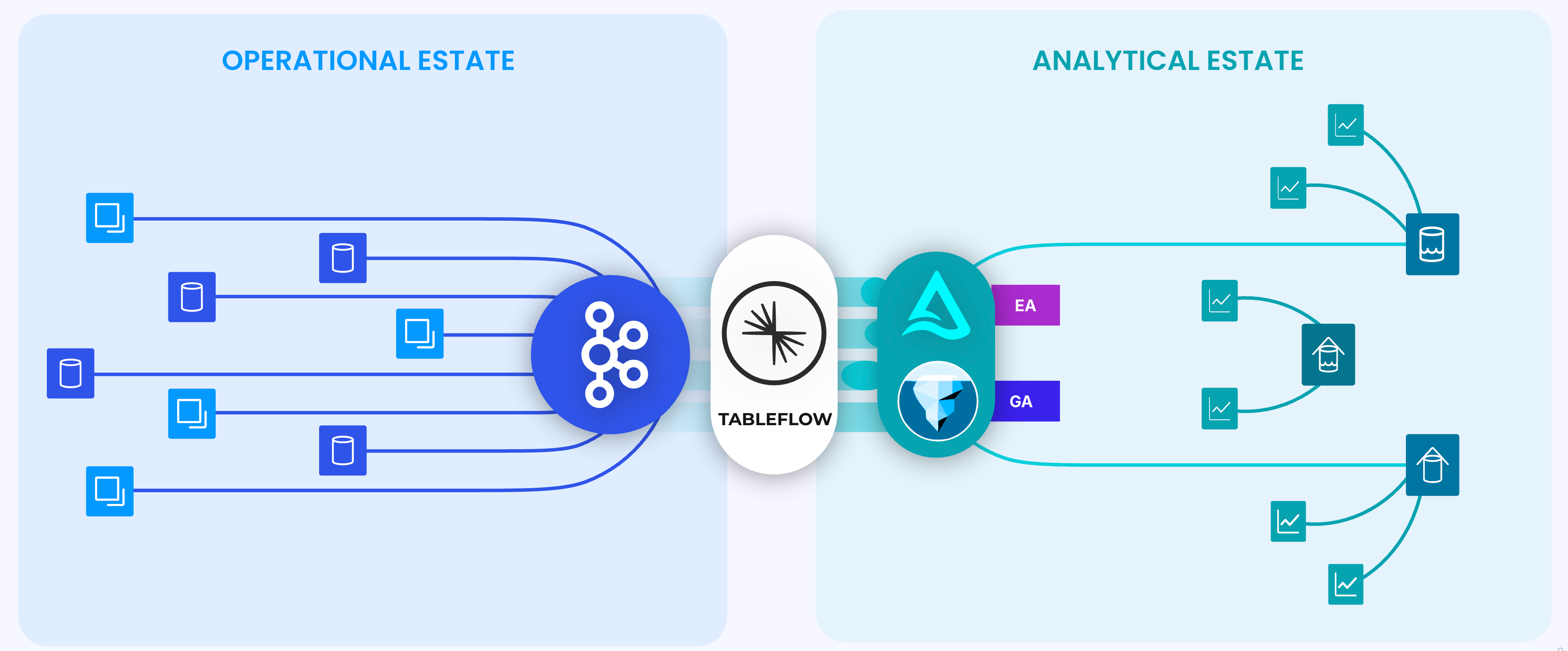
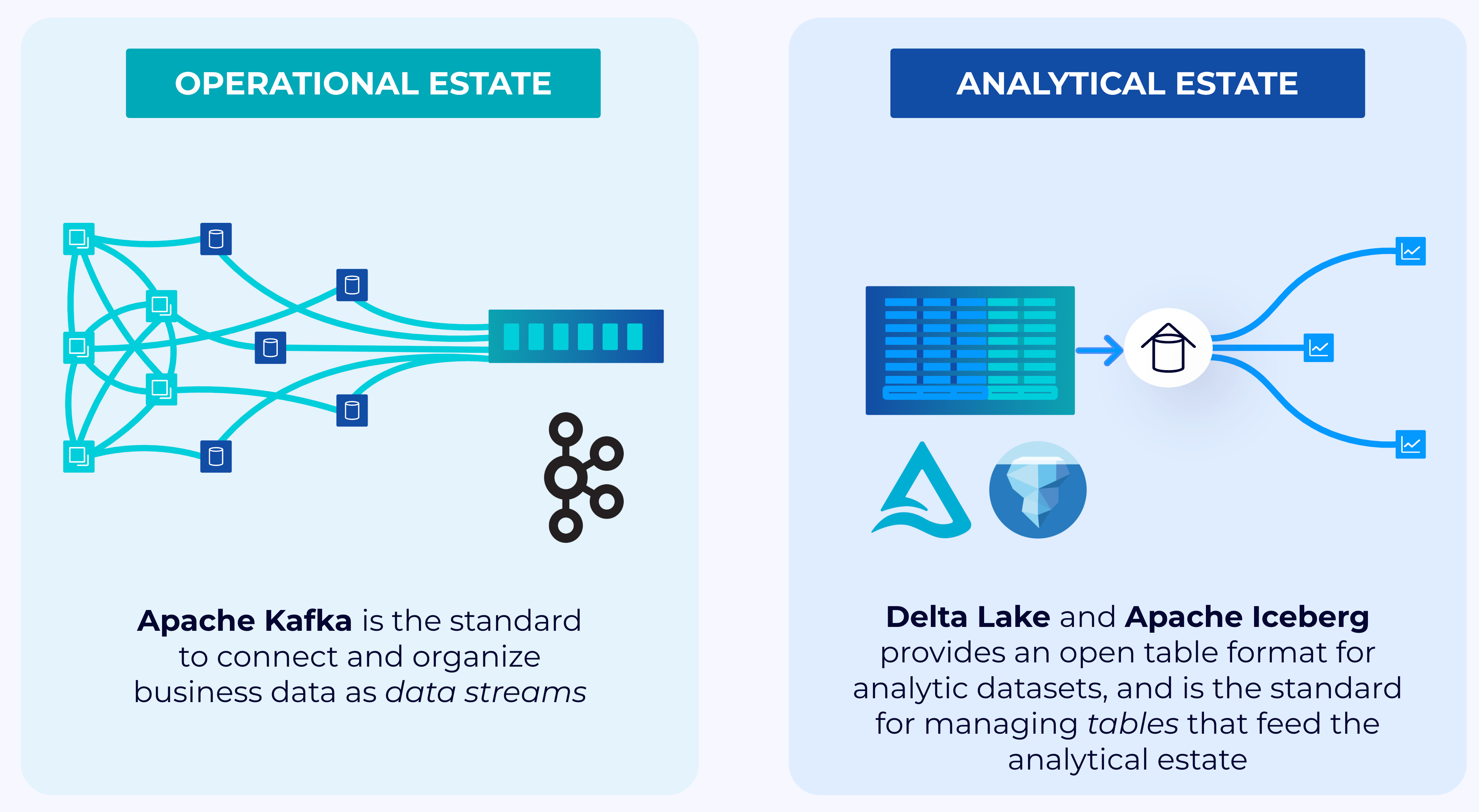
In modern enterprises, the management and utilization of data typically are organized into two distinct estates: the operational estate and the analytical estate.
The operational estate serves the needs of all the applications that runs the business. Kafka has became the de facto standard to capture, store, and organize business data as data streams on the operational side of an organization.
The analytical estate focuses on post-event analysis and reporting, leveraging data lakes and lakehouses. The analytical estate is converging to store data using open-table formats and data stored in cloud object storages, like Amazon S3. Apache Iceberg has emerged as the open-table format for storing data in both data lakes and data warehouses.
Transferring data from the operational estate to the analytical estate is essential for leveraging operational data in analytics. Typically, streaming operational data from Kafka to data lakes is accomplished through a series of complex, expensive, non-reusable, and fragile data-processing tasks.
Usually, these data pipelines are built around managing and enhancing data quality across various stages of the data pipeline. The data produced in each stage can be categorized into different quality tiers, such as bronze, silver, and gold, based on their level of refinement and suitability for analytics.
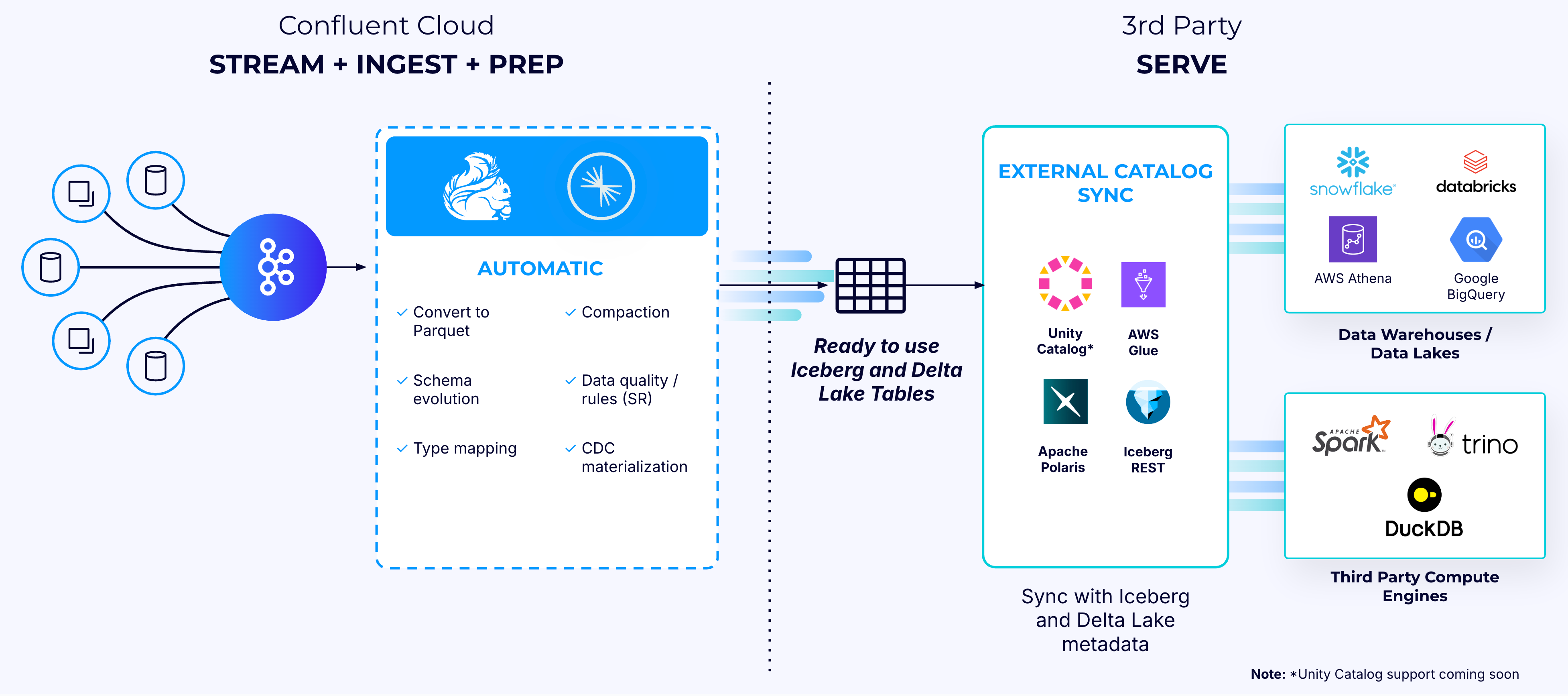
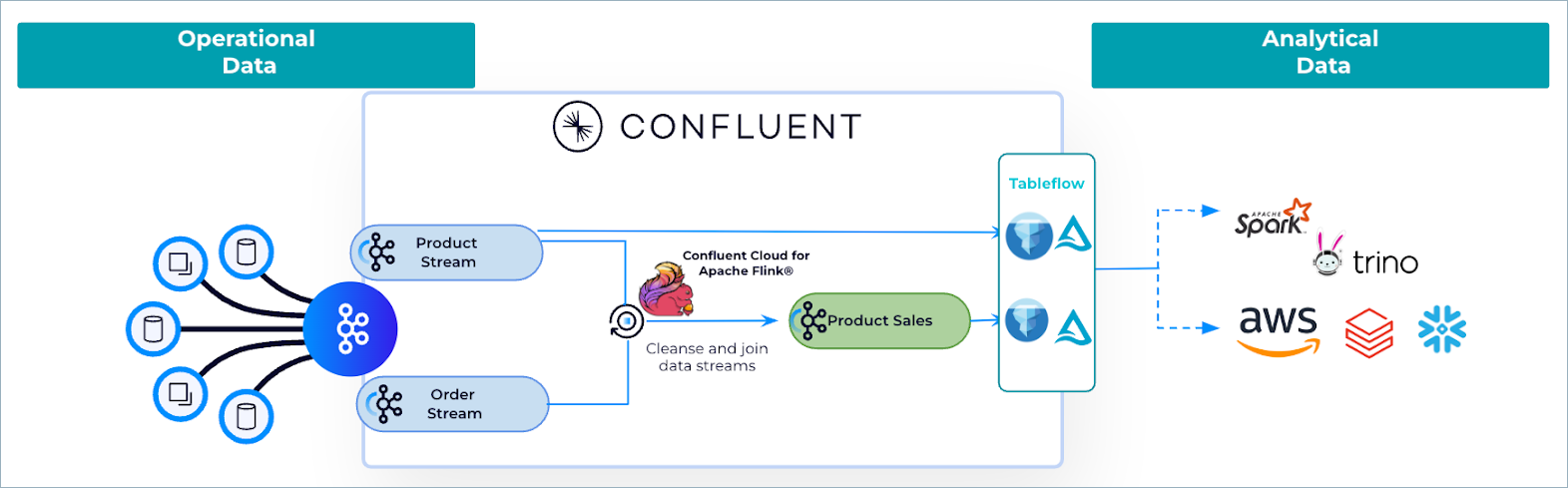
As shown in the following diagram, streaming raw operational data in Kafka topics to analytics-ready data formats like Iceberg requires building complex data-processing logic that includes data cleaning, schematization, materializing change data capture (CDC) feeds, transformation, compaction, and storing data in Parquet and Iceberg formats.
What if you could eliminate all the hassle and have your Kafka topics materialized automatically into analytics-ready Iceberg tables in your data lake or warehouse? This is precisely what Tableflow enables you to do.
Shift-left stream processing with Confluent Cloud for Apache Flink
Confluent Cloud for Apache Flink powers real-time stream processing on Kafka topics, which are subsequently materialized into tables using Tableflow. With Flink, you can implement business-specific logic such as filtering, deduplication, personally identifiable information (PII) removal, and data stream-level joining. This approach significantly minimizes the need for expensive post-processing in data lakes or data warehouses.
For instance, in the previous use case, Confluent Cloud for Apache Flink is used to execute stream processing—cleansing and joining data from multiple Kafka topics — to develop a new data product. This refined process enhances data quality and accessibility.
Tableflow and Delta Lake tables
Confluent Tableflow enables you to expose Kafka topics as Delta Lake tables. Tableflow automatically materializes Kafka topics into Delta Lake tables in your cloud storage. These tables can be consumed as external read-only Delta tables from Databricks.
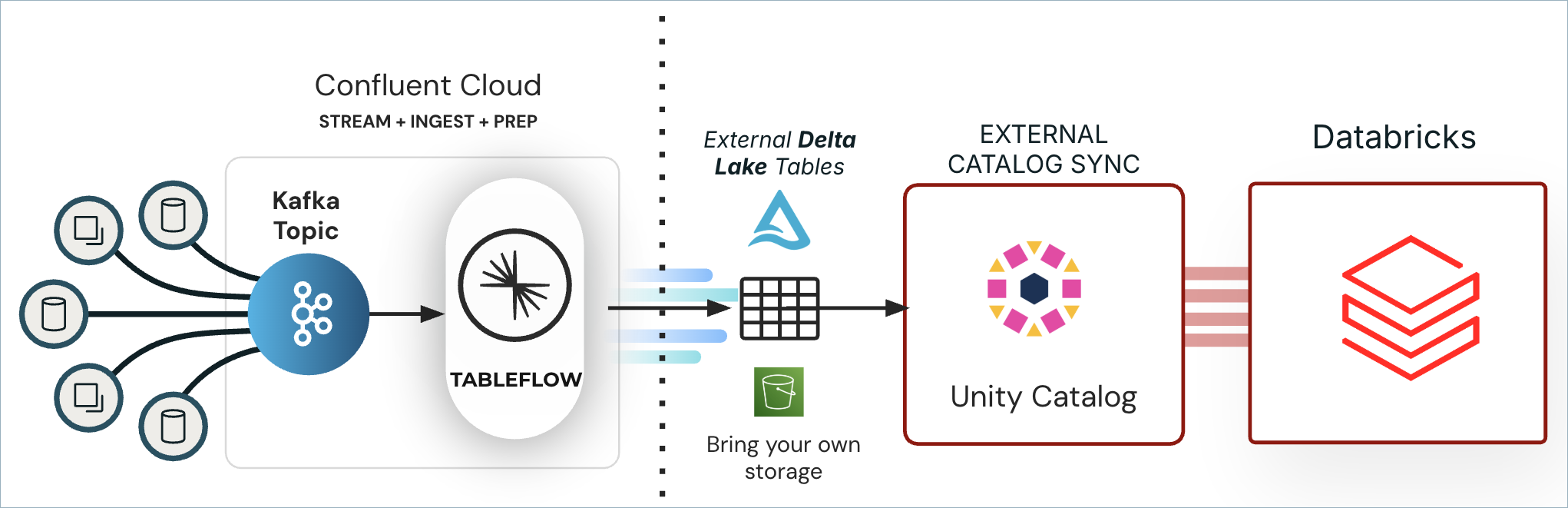
You can publish these Delta Lake tables directly to Unity Catalog through built-in Unity Catalog Integration. This enables you to register and manage table metadata, enforce access controls, and apply consistent governance across all your Delta Lake tables within Databricks.
Once registered, the tables can be accessed as external, read-only Delta Lake tables in Databricks, making it easy to query and analyze streaming data alongside your existing datasets.
Note
Tableflow Delta Lake tables support only Bring Your Own Storage (BYOS).
Supported cloud regions
For a list of available regions, see Supported Cloud Regions.
Limitations
Cluster limitations
Tableflow is not available on Confluent Cloud clusters hosted on Google Cloud.
Tableflow is not available for Confluent Platform.
Privately networked clusters do not support Tableflow-enabled topics using Confluent-managed storage. Only custom storage (“Bring Your Own Storage”) is supported with privately networked clusters.
Topic and table limitations
Tableflow does not support schemaless topics. For more info, see Using schemas without Schema Registry serializers.
Retract tables (Flink retract changelog mode) are not supported.
Iceberg data in Confluent Managed Storage can only be accessed with credentials vended by the Confluent Iceberg REST Catalog.
Tableflow automatically keeps a minimum of 10 snapshots and maximum of 100 snapshots. This setting is not user-configurable.
Storage limitations
Tableflow manages the files it writes to your storage location. Review the following limitations before you change storage settings or delete data.
Warning
Do not delete Tableflow-managed files. Altering or deleting any files manually can result in data corruption or cause Tableflow to suspend.
Automatically deleting tables in Confluent Managed Storage and custom storage (“Bring Your Own Storage”) is performed within a few days after disabling Tableflow on a topic.
Changing from custom storage to Confluent Managed Storage is not supported.
Once a topic is Tableflow-enabled with custom storage, changing the bucket is not supported.
Confluent Managed Storage files can only be accessed with vended credentials provided by the Iceberg REST Catalog.
Amazon S3 buckets or Azure Storage Accounts used for custom storage must be in the same region as your Kafka cluster.
Catalog integration
When updating an existing catalog integration, you must manually remove the metadata resources associated with the previous integration.
Only Tableflow-enabled topics using custom storage can be synced to external catalogs.
Tableflow-enabled topics using Confluent-managed storage do not sync to external catalogs.
Other limitations
Confluent Cloud for Apache Flink can’t query Iceberg tables.
Topics without a schema are not supported.
CSFLE limitations
For limitations and known behavior when materializing topics that use client-side field level encryption (CSFLE), see Limitations and known behavior.