
Integrate Tableflow with the AWS Glue Catalog in Confluent Cloud
Tableflow enables integrating with the AWS Glue Data Catalog as an external catalog, allowing the metadata of Apache Iceberg™ tables materialized by Tableflow to be published to AWS Glue. This makes the Iceberg tables accessible to any Iceberg-compatible query or compute engine that leverages the AWS Glue Data Catalog. Integrating with AWS Glue Data Catalog is only available to clusters running in AWS.
These tables must be consumed as read-only tables.
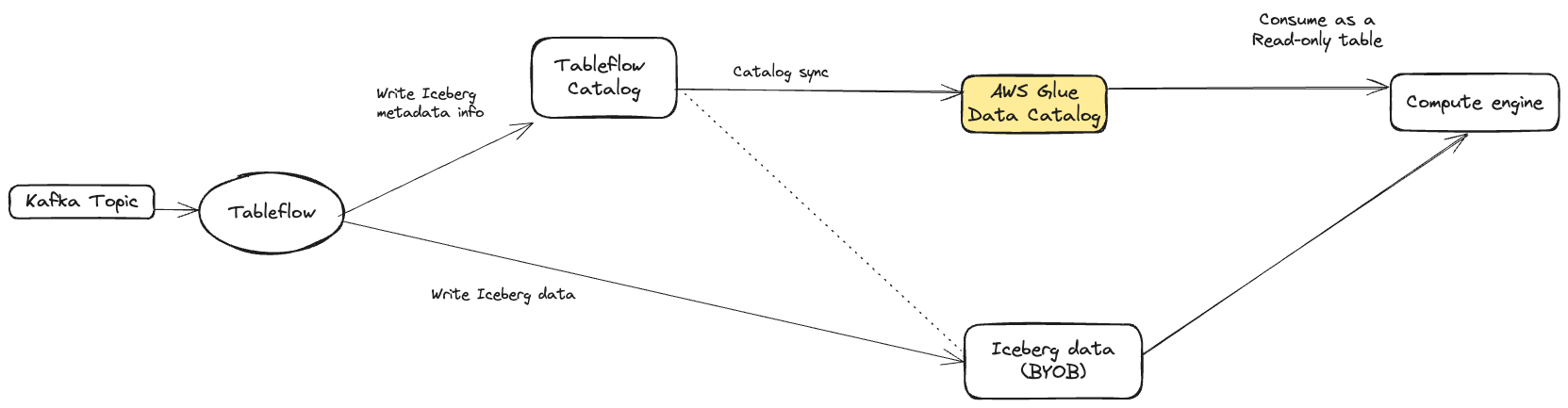
Integrating with the AWS Glue Data Catalog ensures that external catalogs maintain up-to-date and consistent metadata, while the Tableflow catalog remains the single source of truth.
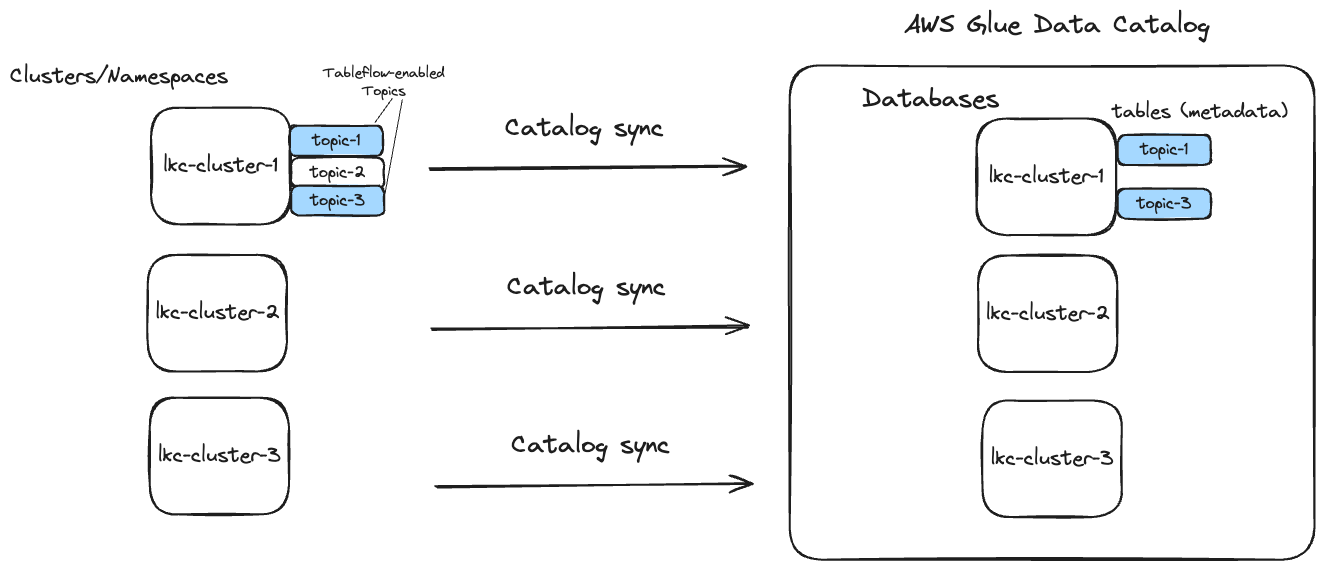
The AWS Glue Data Catalog integrates with Tableflow at the cluster level, enabling the automatic publication of all Tableflow-enabled topics as tables within Glue. As shown in the following diagram, the database and table names map directly to their corresponding cluster ID and topic name, establishing a clear relationship between these elements.
Disable Glue table optimizers and treat Tableflow tables as read-only
When using Tableflow with Iceberg tables registered in AWS Glue Catalog, do not enable Glue table optimization features, such as Compaction, Snapshot Retention, or Orphan File Deletion from the Glue or Lake Formation console. These optimizers are not required for Tableflow-managed tables and may interfere with Tableflow’s own commit, retention, and cleanup lifecycle.
By default, these optimizers are disabled for new Iceberg tables in Glue. No explicit configuration is required to ensure that they remain disabled. Tableflow automatically manages table maintenance, compaction, and cleanup across supported catalogs and table formats.
In addition:
Consider Tableflow-managed tables in Glue as read-only.
Do not modify, optimize, or alter them directly in Glue, Lake Formation, or other external tools.
Perform all write and maintenance operations through Tableflow, to ensure consistency and correctness.
Ensure sufficient Lake Formation access
If your AWS Glue Data Catalog is managed by AWS Lake Formation, ensure that Lake Formation allows Tableflow’s IAM role, which is the role you configure for the Glue catalog integration, to access both the catalog objects and the underlying S3 data.
Grant the Lake Formation pass-through permission lakeformation:GetDataAccess on the role so it can read and write underlying data.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "lakeformation:GetDataAccess",
"Resource": "*"
}
]
}
For more information, see the Lake Formation documentation.
Configure AWS Glue Catalog integration
The following steps show how to enable AWS Glue Catalog integration at the cluster level.
Important
Topics must be materialized in order for catalog synchronization to complete. Enable Tableflow on a topic before enabling your external catalog provider. Catalog sync remains in the pending state until at least one topic is enabled with Tableflow.
Open Confluent Cloud Console and navigate to the cluster that has the topics you want to sync with tables in Glue.
In the navigation menu, click Tableflow and scroll to the External Catalog Integrations section.
Click Add Integration.
Select AWS Glue as the catalog, provide a name to identify your catalog integration, and click Continue.
Click the link in Go to the Provider integration page, and in the Create new IAM Role in AWS dialog, click Confirm.
The Configure role in AWS provider integration page opens.
Select New Role and click Continue.
The Create permission policy in AWS page opens.
In the Select Confluent resource dropdown, select Tableflow Glue Catalog sync, copy the IAM Policy template, and click Continue.
The Create role in AWS and map to Confluent page opens.
Click the Create Role in AWS link to open the AWS IAM console.
Click Policies under Access Management and click Create Policy.
Using the IAM Policy template you copied previously, update the region and Glue account ID with your own, and create a new AWS IAM policy. Name the new policy, for example, tableflow-policy-glue-access.
Navigate to AWS IAM Roles and click Create Role.
Select Custom trust policy as the Trusted entity type.
Attach the permission policy you created previously, for example, tableflow-policy-glue-access, and save your new IAM role. Name the new role, for example, tableflow-catalog-role.
Copy the role ARN, which resembles
arn:aws:iam::<xxx>:role/<your-role-name>.Return to Cloud Console, and in the Map the role in Confluent section, paste the role ARN you copied previously in the AWS ARN textbox.
Enter a name for the provider integration, for example, tableflow-glue-pi.
Click Continue, and update the trust policy of the AWS IAM role using the trust policy presented in the UI.
Click Finish.
After you create the provider integration, Confluent Cloud can access your AWS Glue Catalog and publish Iceberg table metadata pointers to it.
In the catalog integration wizard, select the provider integration and proceed to the next step.
Review the configuration and launch the catalog integration.
Configure read-only access
The Iceberg tables materialized by Tableflow should be read-only tables. The following steps show how to set the required permissions to AWS Glue and S3 buckets.
Open the AWS Glue Catalog console.
Find the Iceberg table that was published in the previous steps as an AWS Glue table.
The cluster ID maps to the AWS Glue database name.
The Kafka topic name maps to the AWS Glue table name.
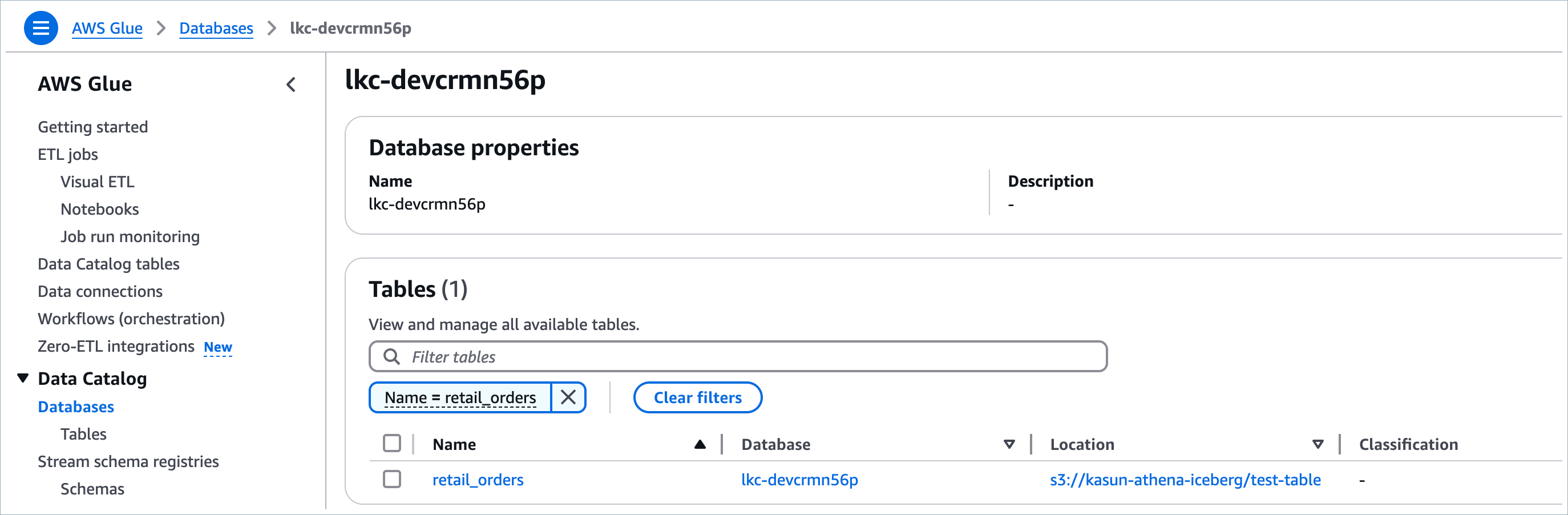
You can query these tables from any analytics or compute engine that supports AWS Glue Data Catalog. For more information, see Query Data.
You must consume Tableflow Iceberg tables as read-only, ensuring that downstream analytics engines have read-only access to them.