
Stream Processing Concepts in Confluent Cloud for Apache Flink
Stream processing is the continuous computation of results over unbounded data as events arrive, in contrast to batch processing over a finite dataset. Apache Flink® SQL, a high-level API powered by Confluent Cloud for Apache Flink, expresses stream processing as SQL queries, with built-in functions, queries, and statements that filter, aggregate, route, and transform streams of data in real time.
Tip
Use Confluent MCP servers and agent skills to manage Confluent Cloud resources and build streaming applications from Claude Code and other AI assistants. For more information, see Use AI Tools with Confluent Cloud.
Stream processing
Streams are the de-facto way to create data. Whether the data comprises events from web servers, trades from a stock exchange, or sensor readings from a machine on a factory floor, data is created as part of a stream.
When you analyze data, you can either organize your processing around bounded or unbounded streams, and which of these paradigms you choose has significant consequences.
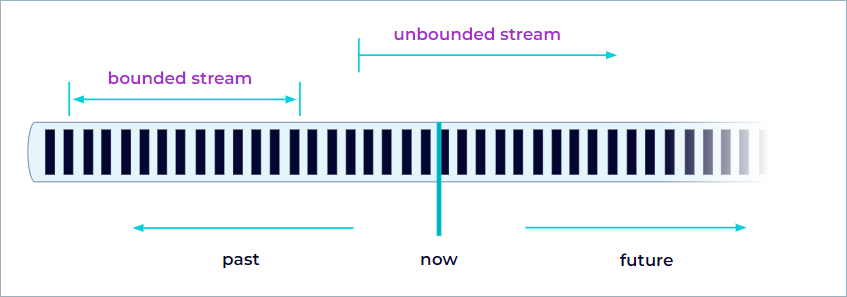
Batch processing is the paradigm at work when you process a bounded data stream. In this mode of operation, you can choose to ingest the entire dataset before producing any results, which means that it’s possible, for example, to sort the data, compute global statistics, or produce a final report that summarizes all of the input.
Snapshot queries are a type of batch processing query that enables you to process a subset of data from a Kafka topic.
Stream processing, on the other hand, involves unbounded data streams. Conceptually, at least, the input might never end, so you must process the data continuously as it arrives.
Bounded and unbounded tables
In the context of a Flink table, bounded mode refers to processing data that is finite, which means that the dataset has a clear beginning and end and does not grow continuously or update over time. This is in contrast to unbounded mode, where data arrives as a continuous stream, potentially with no end.
The scan.bounded.mode property controls how Flink consumes data from a Kafka topic.
Committed offsets in Kafka brokers of a specific consumer group, latest offsets, or a user-supplied timestamp can bound a table.
Key characteristics of bounded mode
Finite data: The table represents a static dataset, similar to a traditional table in a relational database or a file in a data lake. After Flink reads all records, no more data remains to process.
Batch processing: Flink executes operations on bounded tables in batch mode. This means Flink processes all the available data, computes the results, and then the job finishes. This is suitable for use cases such as ETL, reporting, and historical analysis.
Optimized execution: Because the system knows the data is finite, it can apply optimizations that are not possible with unbounded (streaming) data. For example, it can sort by any column, perform global aggregations, and use blocking operators.
No need for state retention: Unlike streaming mode, where Flink must keep state around to handle late or out-of-order events, batch mode can drop state as soon as the data no longer needs it, reducing resource usage.
The following table compares the characteristics of bounded and unbounded tables.
Aspect | Bounded Mode (Batch) | Unbounded Mode (Streaming) |
|---|---|---|
Data Size | Finite (static) | Infinite (dynamic, continuous) |
Processing Style | Batch processing | Real-time/continuous processing |
Query Semantics | All data available at once | Data arrives over time |
State Management | Minimal, can drop state when done | Must retain state for late/out-of-order data |
Use Cases | ETL, reporting, historical analytics | Real-time analytics, monitoring, alerting |
Parallel dataflows
Programs in Flink are inherently parallel and distributed. During execution, a stream has one or more stream partitions, and each operator has one or more operator subtasks. The operator subtasks are independent of one another, and execute in different threads and possibly on different machines or containers.
The number of operator subtasks is the parallelism of that particular operator. Different operators of the same program can have different levels of parallelism.
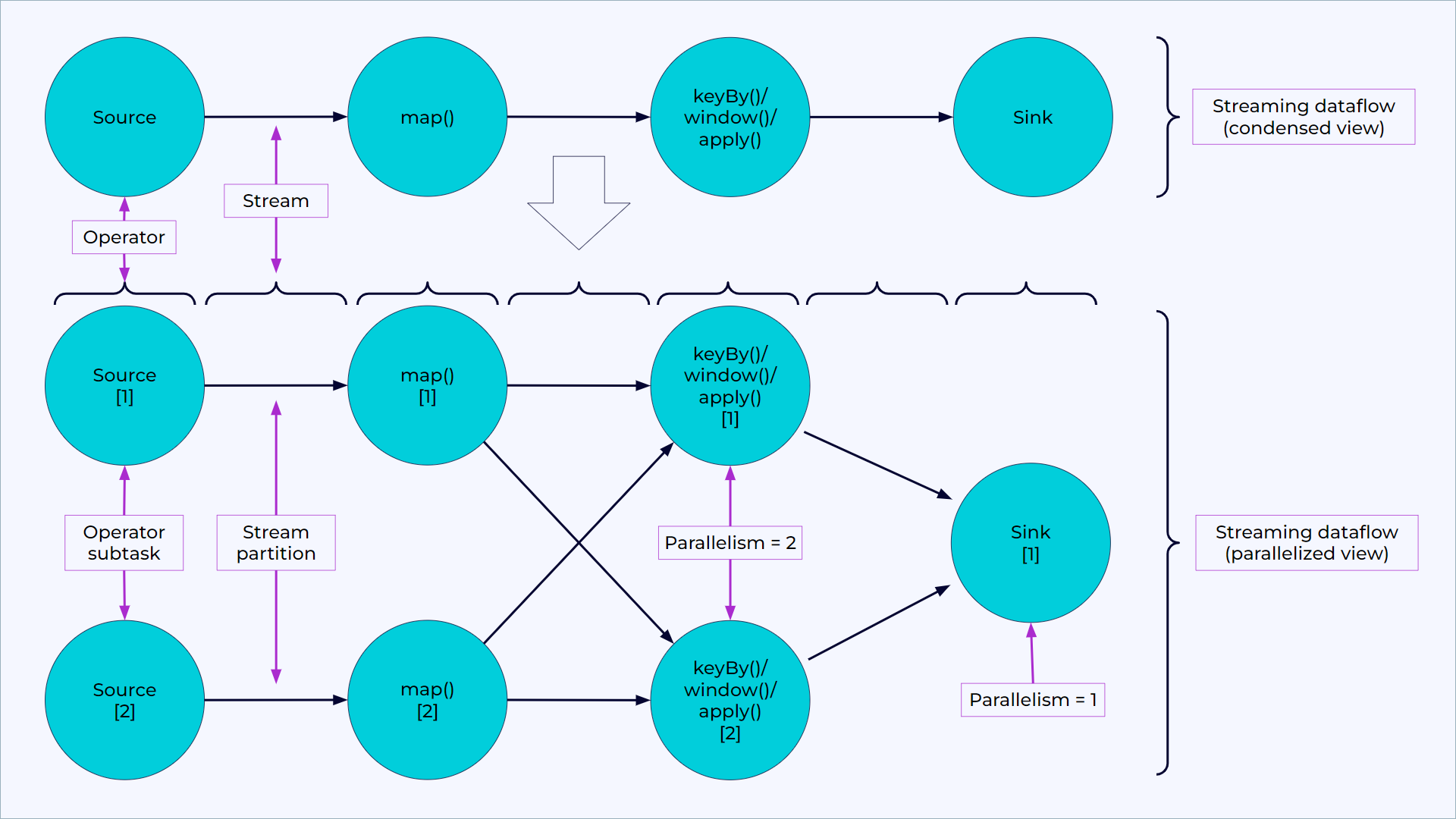
A parallel dataflow in Flink with condensed view (above) and parallelized view (below).
Streams can transport data between two operators in a one-to-one (or forwarding) pattern, or in a redistributing pattern:
One-to-one streams (for example, between the Source and the map() operators in the figure) preserve the partitioning and ordering of the elements. That means that subtask[1] of the map() operator sees the same elements in the same order that subtask[1] of the Source operator produced.
Redistributing streams (such as between map() and keyBy/window, and between keyBy/window and Sink) change the partitioning of streams. Each operator subtask sends data to different target subtasks, depending on the selected transformation. Examples are keyBy() (which re-partitions by hashing the key), broadcast(), and rebalance() (which re-partitions randomly). In a redistributing exchange, Flink preserves the ordering among the elements only within each pair of sending and receiving subtasks (for example, subtask[1] of map() and subtask[2] of keyBy/window). So, for example, the redistribution between the keyBy/window and the Sink operators shown in the figure introduces non-determinism regarding the order in which the aggregated results for different keys arrive at the Sink.
Timely stream processing
Most streaming applications benefit from being able to re-process historic data with the same code that processes live data, and from producing deterministic, consistent results in both cases.
It can also be crucial to pay attention to the order in which events occurred, rather than the order in which they arrive for processing, and to be able to reason about when a set of events is (or should be) complete. For example, consider the set of events involved in an e-commerce transaction or financial trade.
You can meet these requirements for timely stream processing by using event-time timestamps that the data stream records, rather than the clocks of the machines that process the data.
Stateful stream processing
Flink operations can be stateful. This means that how Flink handles one event can depend on the accumulated effect of all the events that came before it. You can use state for something simple, such as counting events per minute to display on a dashboard, or for something more complex, such as computing features for a fraud detection model.
A Flink application runs in parallel on a distributed cluster. The various parallel instances of a given operator execute independently, in separate threads, and generally run on different machines.
A sharded key-value store effectively represents the set of parallel instances of a stateful operator. Each parallel instance is responsible for handling events for a specific group of keys, and Flink keeps the state for those keys locally.
The following diagram shows a job running with a parallelism of two across the first three operators in the job graph, terminating in a sink that has a parallelism of one. The third operator is stateful, and a fully-connected network shuffle occurs between the second and third operators. Flink does this to partition the stream by some key, so that Flink can process together all events that must run together.
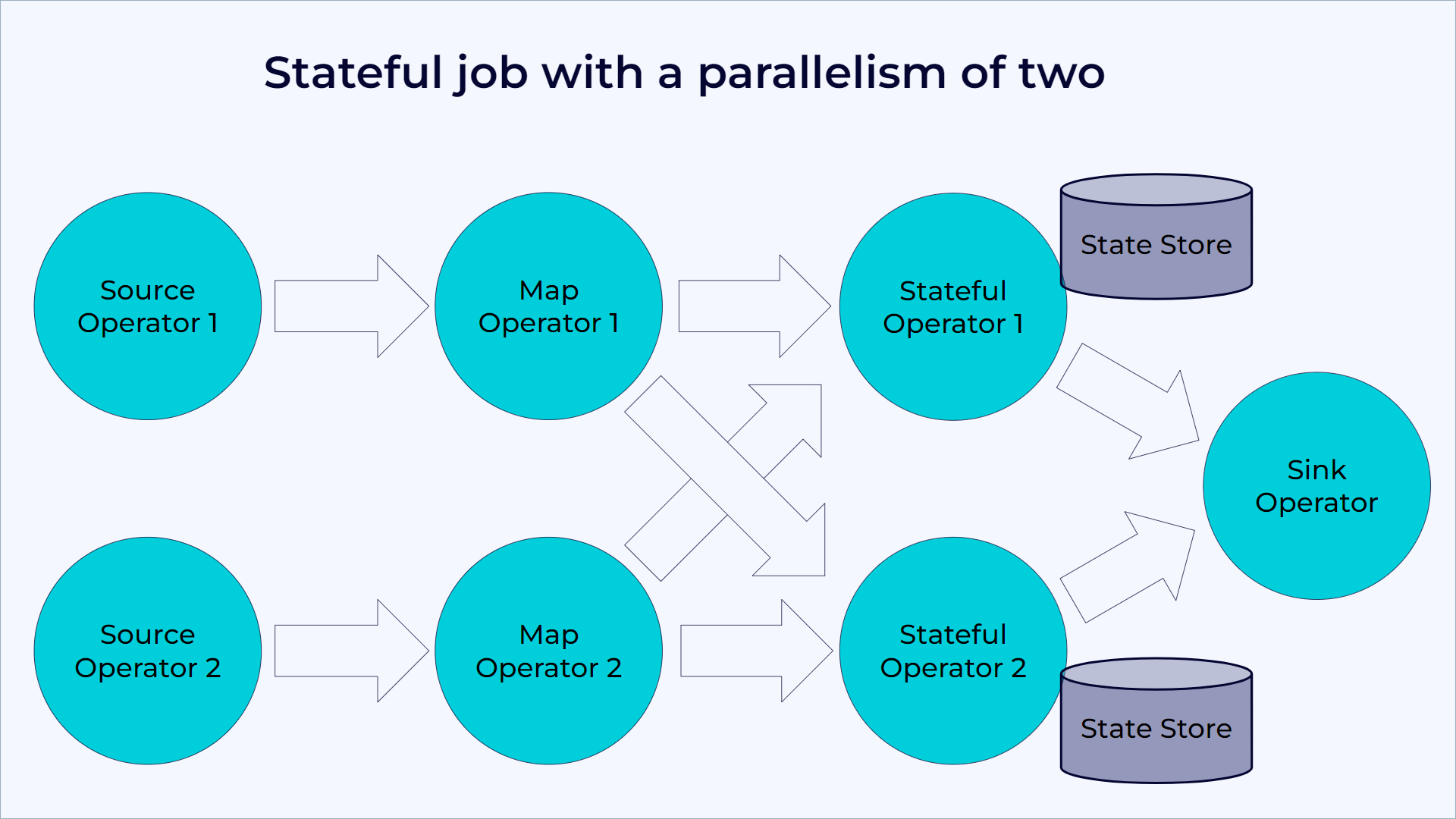
A Flink job running with a parallelism of two.
Flink always accesses state locally, which helps Flink applications achieve high throughput and low latency.
State management
Fault tolerance through state snapshots
Flink is able to provide fault-tolerant, exactly-once semantics through a combination of state snapshots and stream replay. These snapshots capture the entire state of the distributed pipeline, recording offsets into the input queues and the state throughout the job graph that results from ingesting the data up to that point. When a failure occurs, Flink rewinds the sources, restores the state, and resumes processing. Flink captures these state snapshots asynchronously, without impeding the ongoing processing.
Table programs that run in streaming mode leverage all capabilities of Flink as a stateful stream processor.
In particular, you can configure a table program with a state backend and various checkpointing options for handling different requirements regarding state size and fault tolerance.
State usage
Due to the declarative nature of Table API and SQL programs, it’s not always obvious where and how much state a pipeline uses. The planner decides whether state is necessary to compute a correct result. Flink optimizes a pipeline to claim as little state as possible given the current set of optimizer rules.
Conceptually, Flink never keeps source tables entirely in state. An implementer deals with logical tables, named dynamic tables. Their state requirements depend on the operations in use.
Queries such as SELECT ... FROM ... WHERE which consist only of field projections or filters are usually stateless pipelines. But operations such as joins, aggregations, or deduplications require keeping intermediate results in fault-tolerant storage, for which Flink uses state abstractions.
Refer to the individual operator documentation for more details about how much state Flink requires and how to limit a potentially ever-growing state size.
For example, a regular SQL join of two tables requires the operator to keep both input tables in state entirely. For correct SQL semantics, the runtime needs to assume that a match could occur at any point in time from both sides of the join. Flink provides optimized window and interval joins that aim to keep the state size small by exploiting the concept of watermark strategies.
Another example is the following query that computes the number of clicks per session.
SELECT sessionId, COUNT(*) FROM clicks GROUP BY sessionId;
The continuous query uses the sessionId attribute as a grouping key and maintains a count for each sessionId it observes. The sessionId attribute evolves over time and sessionId values are only active until the session ends, that is, for a limited period of time. However, the continuous query cannot know about this property of sessionId and expects that every sessionId value can occur at any point in time. It maintains a count for each observed sessionId value. Consequently, the total state size of the query continuously grows as the query observes more sessionId values.
Dataflow model
Flink implements many techniques from the Dataflow Model. The following articles provide a good introduction to event time and watermark strategies.
Blog post: Streaming 101 by Tyler Akidau