
Create Stream Processing Apps with ksqlDB on Confluent Cloud
ksqlDB for Confluent Cloud
ksqlDB is fully hosted on Confluent Cloud and provides a simple, scalable, resilient, and secure event streaming platform. Sign up for Confluent Cloud to get started.
ksqlDB is a database purpose-built to help developers create stream processing applications on top of Apache Kafka®. Confluent Cloud provides a fully managed solution for creating and managing ksqlDB clusters.
You can provision ksqlDB clusters by using the Confluent Cloud Console or the Confluent CLI.
If you’d like a guided tour in the Confluent Cloud Console, click here to sign up or sign in and follow the in-product tutorial: Get started with ksqlDB.
Note
To run ksqlDB on-premises, install Confluent Platform. ksqlDB for Confluent Platform is packaged as part of Confluent Platform. This is a commercial component of Confluent Platform. ksqlDB for Confluent Platform includes enterprise features, like role-based access control. For more information, see ksqlDB for Confluent Platform.
Supported Features for ksqlDB in Confluent Cloud
Confluent Cloud Console support for managing your ksqlDB cloud environment directly from your browser that exposes all critical ksqlDB information.
SQL editor to write, develop, and execute SQL queries with auto completion directly from the Cloud Console.
Integration with Confluent Cloud Schema Registry to leverage your existing schemas to use within your SQL queries.
SQL-based Connect integration.
Available in AWS, Google Cloud, and Azure in all regions.
Private networking with PrivateLink Attachment.
Changes in ksqlDB
For the latest changes in ksqlDB, see the GitHub repo.
Limitations for ksqlDB in Confluent Cloud
User-defined functions (UDFs, UDAFs, and UDTFs) aren’t supported. For more information, see Functions.
You can have a maximum of 40 persistent queries per cluster.
You can have a maximum of 15 ksqlDB clusters per environment.
Pull queries have specific limitations in Confluent Cloud. For more information, see Pull queries in Confluent Cloud.
You can’t create more than 100 push queries.
Fully managed ksqlDB is not available on Enterprise clusters. Only self-managed ksqlDB is supported.
Schema context limitations
Common use cases with cluster linking work with ksqlDB, because cluster linking yields unique topic names. Schema Registry infers the correct context from the topic name when the context isn’t provided.
Schema contexts can be leveraged if the following are true:
Topic names are unique across Schema Registry contexts, and
TopicNameStrategyis used to look up Schema Registry subjects.
ksqlDB may not be able to discover the correct schema when contexts are used in these cases:
Topic names are not unique across Schema Registry contexts, and/or
The ksqlDB stream or table configures an explicit schema ID, using the
value_schema_idorkey_schema_idquery properties.
Global cache limit
Each ksqlDB cluster has a global cache limit of 1GB, and each query defaults to 10MB of cache usage.
If you have many queries, you may need to set the cache.max.bytes.buffering property to 1GB / number_of_queries so that all of your queries together don’t exceed the limit.
To request a limit increase, submit a support request.
Pricing for ksqlDB in Confluent Cloud
The unit of pricing in Confluent Cloud ksqlDB is the Confluent Streaming Unit. A Confluent Streaming Unit is an abstract unit that represents the linearity of performance. For example, if a workload gets a certain level of throughput with 4 CSUs, you can expect about three times the throughput with 12 CSUs.
Confluent charges you in CSUs per hour.
You select the number of CSUs for your cluster at provisioning time. You can configure CSUs as follows:
4 CSUs is the minimum.
28 CSUs is the maximum.
Cluster sizes can be 4, 8, 12, 16, 20, 24, or 28 CSUs.
For clusters with 4 CSUs or more, you can scale up to 28 CSUs in 4-CSU increments.
Clusters with 8 or more CSUs are configured automatically for high availability.
High availability cannot be enabled for clusters with less than 8 CSUs.
Note
Confluent Streaming Unit pricing varies slightly depending on cloud provider and region. Pricing is shown in the Cloud Console as part of ksqlDB provisioning so that you can see exact pricing for your cloud and region of choice.
Scaling CSUs for ksqlDB in Confluent Cloud
Scaling cluster CSUs after initial provisioning is not currently supported as a self-service option. Contact your Confluent team to scale the cluster (up or down).
Alternatively, if your cluster requires more CSUs, you can provision a new cluster with the desired number of CSUs, and migrate to your new one.
Sizing guidelines for ksqlDB in Confluent Cloud
The number of CSUs needed for your cluster depends on the workload, including the number of queries, query complexity, and throughput. The amount of resources allocated to a cluster is proportional to the number of CSUs defined for the cluster.
Four CSUs are sufficient for many workloads. In general, start with four CSUs and scale out if more capacity is needed, or scale down if less capacity is needed. To identify when more CSUs are needed, check the ksqlDB consumer lag or the CSU Saturation metric.
After your ksqlDB cluster is provisioned, you can only change the Confluent Streaming Unit cluster by migrating to a new one with the desired number of CSUs.
CSUs and storage
You get 125 GB of storage space with each CSU. For 8 CSUs and higher, clusters are configured with high availability automatically, and ksqlDB maintains replicas of your data that use half of the available storage. For 4 CSUs and 8 CSUs, you get 500 GB of user-available storage, so to expand storage past 500 GB, you must expand to at least 12 CSUs.
The following table shows how storage is provisioned for ksqlDB clusters.
Number of CSUs | Storage | User-available storage |
|---|---|---|
4 | 500 GB | 500 GB |
8 | 1000 GB | 500 GB* |
12-28 | 1500 GB | 750 GB* |
Note
* High-availability clusters with half of storage used for data replicas.
High availability
When your cluster has 8 CSUs or more, ksqlDB is configured for high availability automatically, for both processing and storage. This is done in a multi-zones way if your Kafka cluster is configured for multi-zones.
For 8 or more CSUs:
Storage is redundant (2x).
ksqlDB has multi-node deployment, with 4 CSUs per node.
When the Kafka cluster is multi-zones, ksqlDB nodes are placed in multiple zones.
For fault tolerance and faster failure recovery, standby replication is enabled for clusters with 8 CSUs or more. With standby replication, a ksqlDB server, beside being the active server for some partitions, also acts as the standby server for other partitions. In this mode, a ksqlDB server subscribes to the changelog topic partition of the active and replicates updates continuously to its own copy of the table partition. Pull queries that would otherwise fail are routed to other active or standby servers that host the same partition.
The unavailability window during failures is dominated by the table restoration time and the failure detection time. Standby replication significantly reduces the table restoration time. The failure detection time is directly related to the Kafka Streams consumer configuration, and with default settings used in managed ksqlDB, failure detection can take as long as 10–15 seconds.
For more information, see Highly Available, Fault-Tolerant Pull Queries in ksqlDB.
Exclude row data in the ksqlDB processing log
With ksqlDB, you can exclude row data in the processing log when queries error out by setting the ksql.logging.processing.rows.include config to false.
With ksqlDB in Confluent Cloud, this config is set to true by default, and row data is written to the log. You can exclude row data by using Confluent Cloud Console, or by using the Confluent CLI.
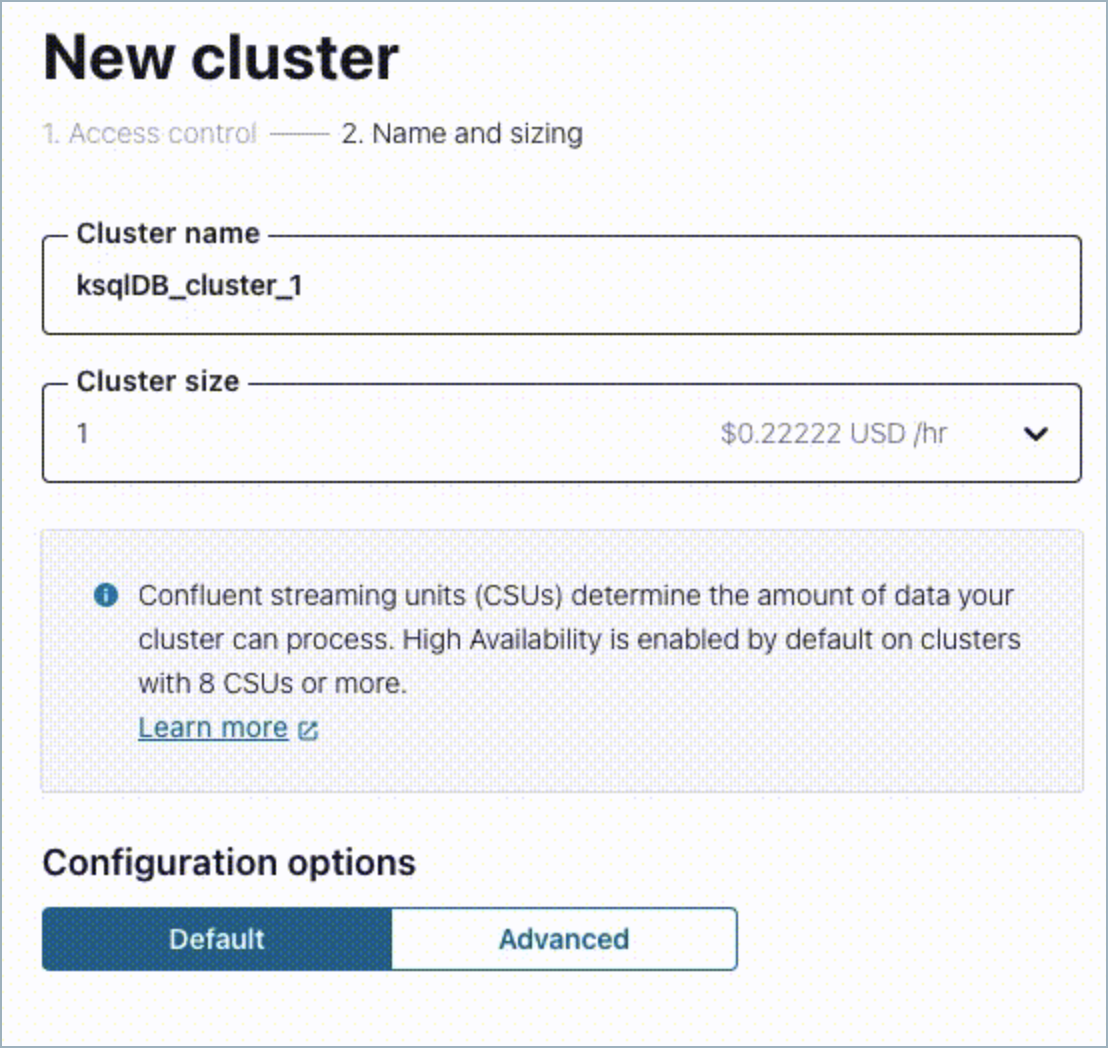
Configure with Confluent Cloud Console
When you create a new ksqlDB cluster, toggle “Hide row data in processing log” by selecting Advanced under Configuration options.
Configure with Confluent CLI
confluent ksql cluster create <cluster-name> --api-key <api-key> --api-secret <secret> --log-exclude-rows
ksqlDB REST API in Confluent Cloud
You can use the REST API to interact with your ksqlDB clusters in Confluent Cloud. For more information, see REST API Index.
For a detailed usage example, see Use the ksqlDB REST API with Postman.
ksqlDB versions
Version | Release Date |
|---|---|
8.0.0-0 | Jun 20, 2025 |
7.7.0-223 | Jul 17, 2024 |
7.7.0-184 | Jun 6, 2024 |
7.6.0-1096 | Feb 28, 2024 |
7.6.0-246 | Oct 25, 2023 |
7.6.0-137 | Sep 7, 2023 |
7.5.0-445 | Jun 26, 2023 |
7.5.0-391 | Jun 5, 2023 |
For earlier versions, see the changelog.