
Time and Watermarks in Confluent Cloud for Apache Flink
Timely stream processing is an extension of stateful stream processing that incorporates time into the computation. It’s commonly used for time series analysis, aggregations based on windows, and event processing where the time of occurrence is important.
This topic covers event time and processing time, watermarks and how they drive windowed operations, late data handling, watermark alignment, and how to define time attributes in Flink SQL.
Notions of time: event time and processing time
Event time and processing time are the two notions of time in stream processing. When you define windows, you choose which notion to use.
Processing time
Processing time refers to the system time of the machine that’s executing the operation.
When a streaming program runs on processing time, all time-based operations, like time windows, use the system clock of the machines that run the operator.
An hourly processing time window includes all records that arrived at a specific operator between the times when the system clock indicated the full hour.
For example, if an application begins running at 9:15 AM, the first hourly processing time window includes events processed between 9:15 AM and 10:00 AM, the next window includes events processed between 10:00 AM and 11:00 AM, and so on.
Processing time is the simplest notion of time and requires no coordination between streams and machines. It provides the best performance and the lowest latency. But in distributed and asynchronous environments, processing time doesn’t provide determinism, because it’s susceptible to:
The speed at which records arrive in the system, for example from a message queue.
The speed at which records flow between operators inside the system.
Outages, both scheduled and unscheduled.
Event time
Event time is the time that each individual event occurred on its producing device. The producer typically embeds this time within the records before they enter Flink, and Flink can extract this event timestamp from each record.
In event time, the progress of time depends on the data, not on any wall clocks. Event-time programs must specify how to generate event-time watermarks, which is the mechanism that signals progress in event time. The Event time and watermarks section describes this watermarking mechanism.
In a perfect world, event-time processing would yield completely consistent and deterministic results, regardless of when events arrive, or their ordering. But unless you know that events arrive in-order (by timestamp), event-time processing incurs some latency while waiting for out-of-order events. Because it’s only possible to wait for a finite period of time, this places a limit on how deterministic event-time applications can be.
Assuming all of the data has arrived, event-time operations behave as expected, and produce correct and consistent results even when working with out-of-order or late events, or when reprocessing historic data.
For example, an hourly event-time window contains all records that carry an event timestamp that falls into that hour, regardless of the order in which they arrive, or when Flink processes them. For more information, see Late-arriving events.
Sometimes when an event-time program is processing live data in real-time, it uses some processing time operations to guarantee that processing progresses in a timely fashion.

Event Time and Processing Time
Event time and watermarks
Event-time progress
Event-time progress measures how far processing has advanced through the event timestamp sequence, independent of wall-clock time. A stream processor that supports event time needs a way to measure this progress. For example, a window operator that builds hourly windows needs notification when event time has passed beyond the end of an hour, so that the operator can close the window in progress.
Event time can progress independently of processing time, as measured by wall clocks. For example, in one program, the current event time of an operator can trail slightly behind the processing time, accounting for a delay in receiving the events, while both proceed at the same speed. But another streaming program might progress through weeks of event time with only a few seconds of processing, by fast-forwarding through some historic data already buffered in an Apache Kafka® topic.
Watermarks
A watermark declares “all records up to this point in time have been seen.” Watermarks are the mechanism in Flink that measures progress in event time, determining when to advance processing or wait for more records.
Certain SQL operations, like windows, interval joins, time-versioned joins, and MATCH_RECOGNIZE require watermarks. Without watermarks, they don’t produce output.
By default, every table has a watermark strategy applied. The SOURCE_WATERMARK function provides the default watermark strategy.
A watermark is a long value that usually represents epoch milliseconds. The watermark of an operator is the minimum of received watermarks over all partitions of all inputs. It triggers the execution of time-based operations within this operator before sending the watermark downstream.
Flink can emit watermarks for every record, or it can compute and emit them on a wall-clock interval. By default, Flink emits them every 200 ms.
The built-in function, CURRENT_WATERMARK, enables printing the current watermark for the executing operator.
Providing a timestamp is a prerequisite for providing a default watermark. Without providing some timestamp, neither a watermark nor a time attribute is possible.
In Flink SQL, you can use only time attributes (timestamp columns marked with a WATERMARK clause) for time-based operations.
A time attribute must be of type TIMESTAMP(p) or TIMESTAMP_LTZ(p), with 0 <= p <= 3.
Defining a watermark over a timestamp makes it a time attribute. A DESCRIBE statement shows it as a ROWTIME.
Watermarks and timestamps
Watermarks flow as part of the data stream and carry a timestamp t. A Watermark(t) declares that event time has reached time t in that stream, meaning that there should be no more elements from the stream with a timestamp t’ <= t, that is, events with timestamps older than or equal to the watermark.
Every Kafka record has a message timestamp which is part of the message format, and not in the payload or headers.
Timestamp semantics can be CreateTime (default) or LogAppendTime.
The broker overwrites the timestamp only if you configure LogAppendTime. Otherwise, it depends on the producer, which means that the timestamp can be user-defined, or it can come from the client’s clock if the user does not define it.
In most cases, a Kafka record’s timestamp is expressed in epoch milliseconds in UTC.
The following diagram shows a stream of events with logical timestamps and watermarks flowing inline. In this example, the events are in order with respect to their timestamps, meaning that the watermarks are simply periodic markers in the stream.

A data stream with in-order events and watermarks
Watermarks are crucial for out-of-order streams, as shown in the following diagram, where the events do not arrive in timestamp order. In general, a watermark declares that by this point in the stream, all events up to a certain timestamp should have arrived. After a watermark reaches an operator, the operator can advance its internal event time clock to the value of the watermark.

A data stream with out-of-order events and watermarks
A freshly created stream element (or elements) inherits event time from either the event that produced them or from the watermark that triggered creation of these elements.
Watermarks in parallel streams
Flink generates watermarks at, or directly after, source functions. Each parallel subtask of a source function usually generates its watermarks independently. These watermarks define the event time at that particular parallel source.
As the watermarks flow through the streaming program, they advance the event time at the operators where they arrive. Whenever an operator advances its event time, it generates a new watermark downstream for its successor operators.
Some operators consume multiple input streams. For example, a union, or operators following a keyBy(…) or partition(…) function consume multiple input streams. Such an operator’s current event time is the minimum of its input streams’ event times. As its input streams update their event times, so does the operator.
The following diagram shows an example of events and watermarks flowing through parallel streams, and operators tracking event time.

Parallel data streams and operators with events and watermarks
Late-arriving events
It’s possible that certain elements violate the watermark condition, meaning that even after the Watermark(t) has occurred, more elements with timestamp t’ <= t occur.
In many real-world systems, arbitrary delays can affect certain elements, making it impossible to specify a time by which all elements of a certain event timestamp have occurred. Delaying watermarks too much causes excessive delay in event-time window evaluation, so even when you can bound lateness, excessive watermark delay is often not desirable.
For this reason, streaming programs can explicitly expect some late elements. Late elements are elements that arrive after the system’s event time clock, as the watermarks signal, has already passed the time of the late element’s timestamp.
Late data handling
Rather than relying solely on the default behavior for late elements, Confluent Cloud for Apache Flink® provides explicit control over late-arriving events through the late-handling.mode table property. Late data refers to events that arrive after the watermark has advanced past their event timestamp.
Late data behavior modes
pass-through(default): Late events flow through to downstream operators. Operators like window aggregations decide whether to process or drop them.filter: Flink filters late events immediately at the source. The main pipeline processes only on-time data, and a System Table (<table_name>$late) preserves the filtered events for inspection or reprocessing.
System Tables
System Tables are virtual views on Flink source tables. When you configure late-handling.mode = 'filter', a System Table with the $late suffix becomes available:
Does not create new physical storage.
Inherits schema from the source table automatically.
Retention follows the source Kafka topic’s retention settings.
You can query it with standard SQL (SELECT, INSERT INTO, and other operations).
For configuration details, see Handle Late-Arriving Data.
Windowing
Windows scope aggregations on streams to finite time periods or element counts. Unlike batch processing, streams are in general infinite (unbounded), so it’s impossible to count all elements. Instead, windows scope aggregates such as counts and sums, for example “count over the last 5 minutes” or “sum of the last 100 elements”.

Time windows and count windows on a data stream
Windows can be time driven, for example, “every 30 seconds”, or data driven, for example, “every 100 elements”.
There are different types of windows, for example:
Tumbling windows: no overlap.
Sliding windows: with overlap.
Session windows: separated by a gap of inactivity.
For more information, see:
Watermarks and windows
The following example shows how watermarks propagate through a partitioned source and trigger window computations.
In the following example, the source is a Kafka topic with 4 partitions.
The Flink job is running with a parallelism of 2, and each instance of the Kafka source reads from 2 partitions.
Each event has a key, shown as a letter from A to D, and a timestamp.
The events shown in bold text have already been read. The events in gray, to the left of the read position, are read next.
Flink shuffles the events that it has already read by key into the window operators, where it counts the events by key for each hour.
Example Flink job graph with windows and watermarks.
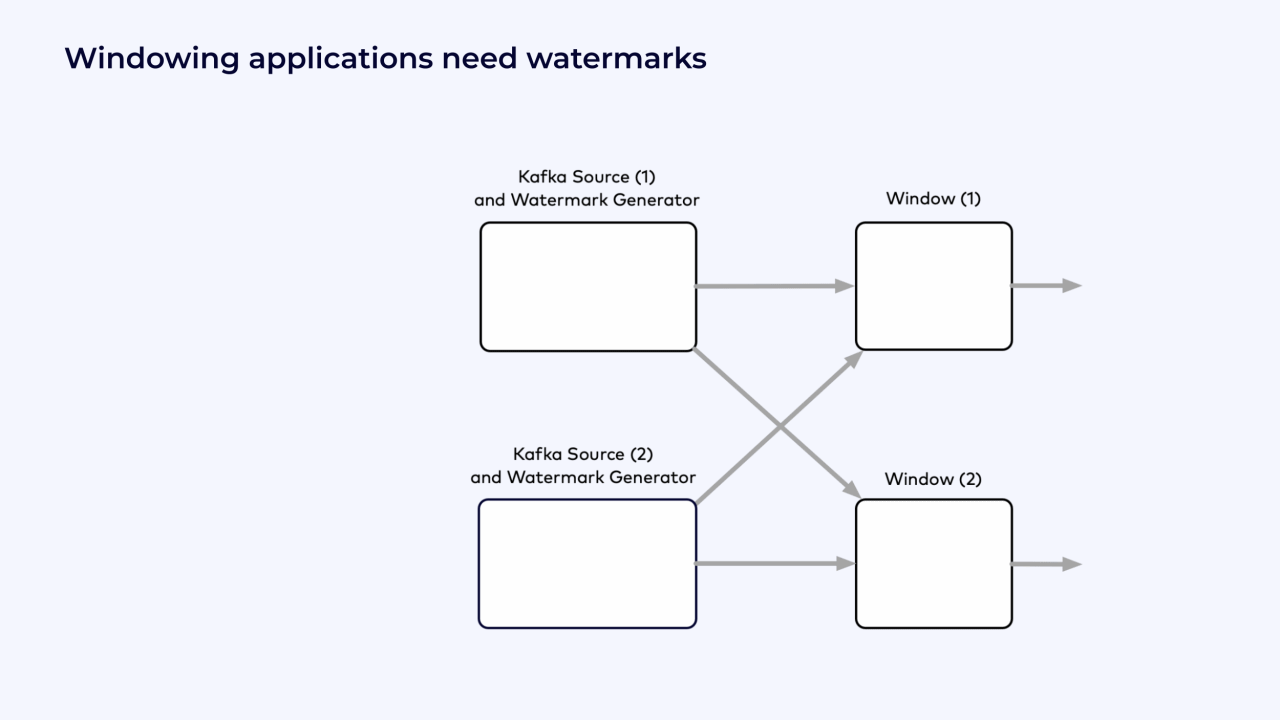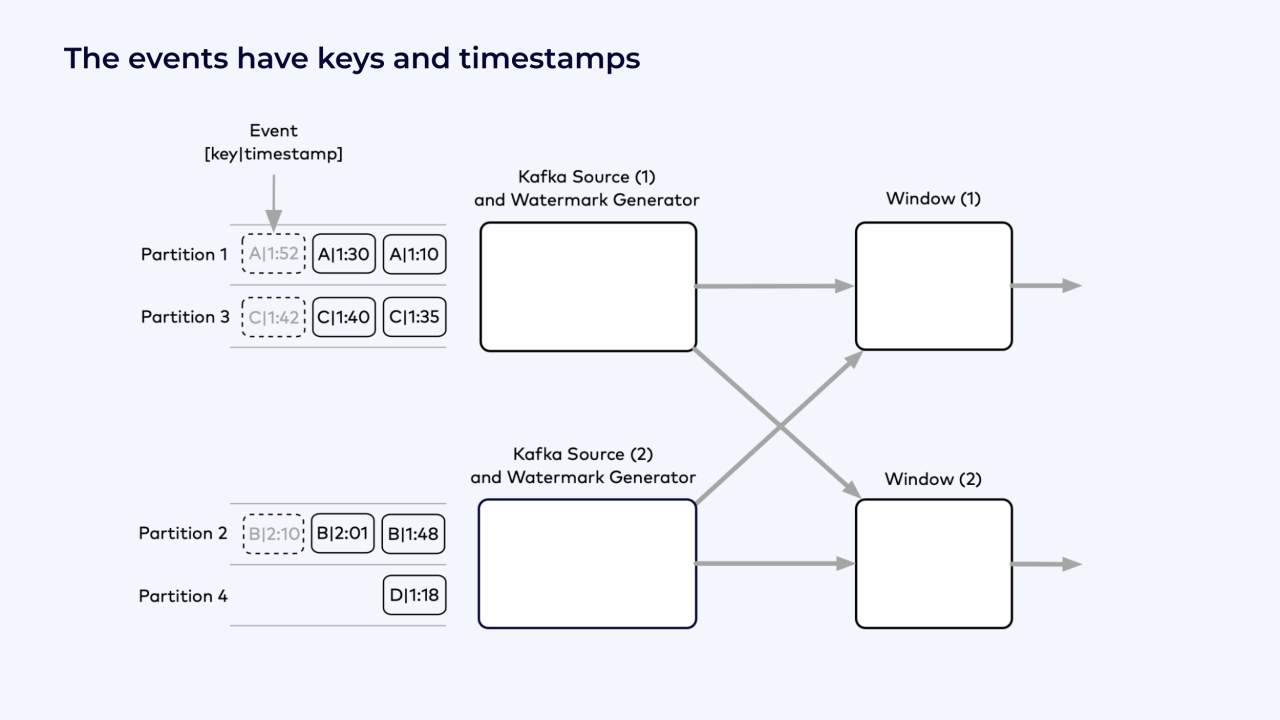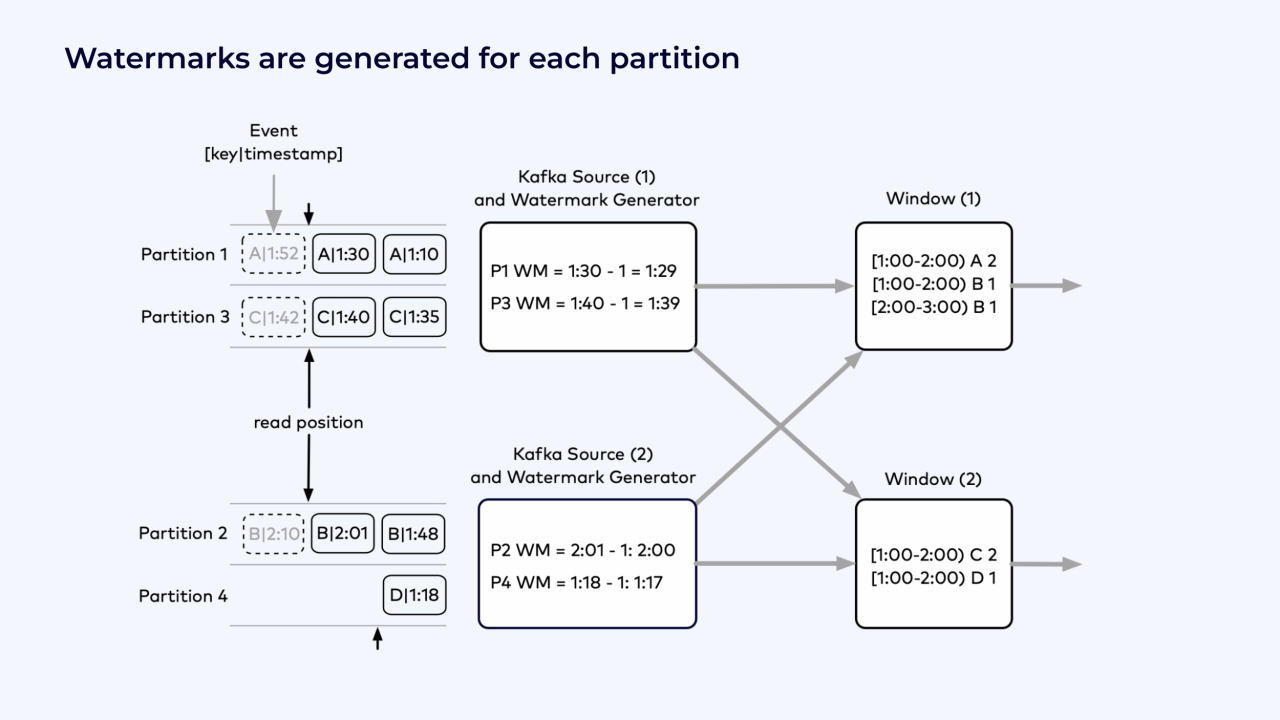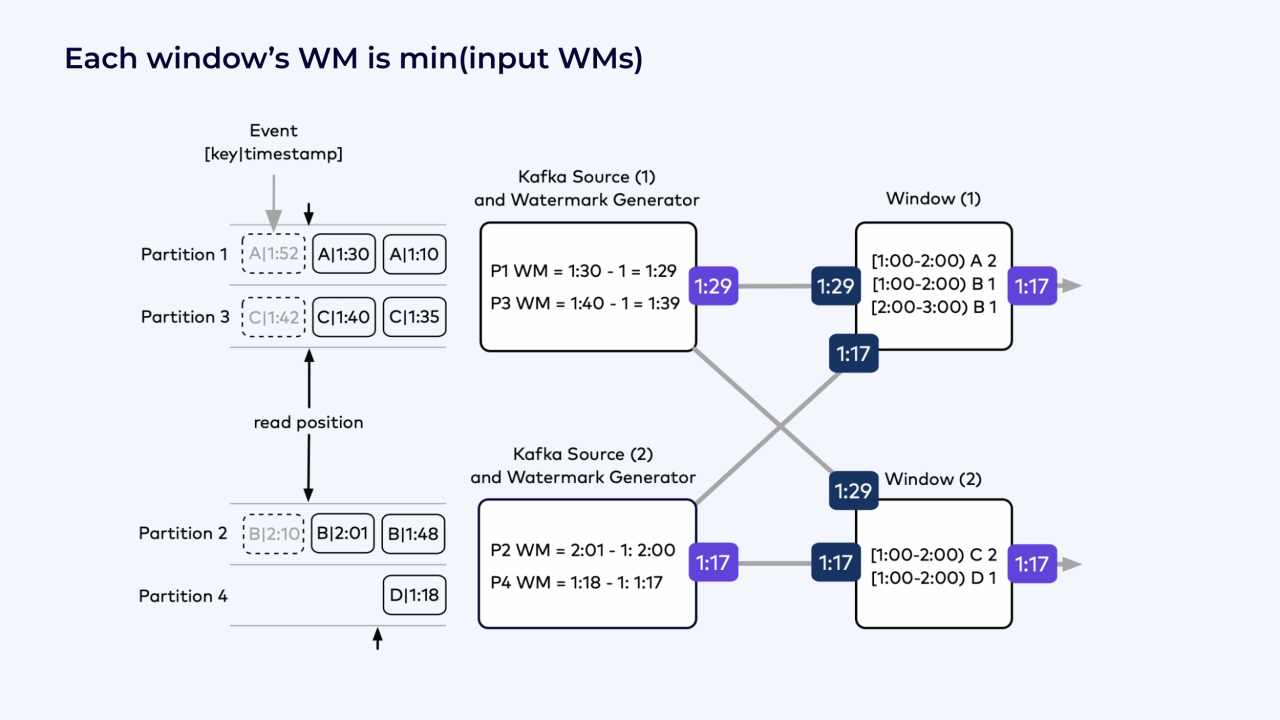
Because the hour from 1 to 2 o’clock hasn’t been finalized yet, the windows keep track of the counters for that hour. There have been two events for key A for that hour, one event for key B, and so on.
Because events for the following hour have already begun to appear, these windows also maintain counters for the hour from 2 o’clock to 3 o’clock.
These windows wait for watermarks to trigger them to produce their results. The watermarks come from the watermark generators in the Kafka source operators.
For each Kafka partition, the watermark generator keeps track of the largest timestamp seen so far, and subtracts from that an estimate of the expected out-of-orderness.
For example, for Partition 1, the largest timestamp is 1:30. Assuming that the events are at most 1 minute out of order, then the watermark for Partition 1 is 1:29.
A similar computation for Partition 3 yields a watermark of 1:30, and so on for the remaining partitions.
Each of the two Kafka source instances takes as its watermark the minimum of these per-partition watermarks.
From the point of view of the uppermost Kafka source operator, the watermark it produces should include a timestamp that reflects how complete the stream is that it is producing.
This stream from Kafka Source 1 includes events from both Partition 1 and Partition 3, so it can be no more complete than the furthest behind of these two partitions, which is Partition 1.
Although Partition 1 has seen an event with a timestamp as late as 1:30, it reports its watermark as 1:29, because it allows for its events to be up to one minute out-of-order.
The same reasoning applies as the watermarks flow downstream through the job graph. Each instance of the window operator has received watermarks from the two Kafka source instances.
The current watermark at both of the window operators is 1:17, because this is the furthest behind of the watermarks coming into the windows from the Kafka sources.
The furthest behind of all four Kafka partitions determines the overall progress of the windows.
Watermark alignment
Watermark alignment enables you to specify how tightly synchronized your streams should be, preventing any of the sources from getting too far ahead of the others. It addresses the problem of temporal joins between streams with progressively diverging timestamps.
When performing temporal joins between two streams, if one stream is significantly ahead of the other, Flink must buffer data from the leading stream while waiting for the watermark of the lagging stream to advance. As timestamps diverge further, the buffering requirements grow, potentially causing performance degradation and operational issues, such as checkpointing failures.
Watermark alignment enables you to pause reading from streams that are too far ahead, enabling lagging streams to catch up and preventing the situation from worsening. This feature is particularly valuable when joining streams that have naturally diverging timestamps, such as when one data source produces events more frequently or with different timing characteristics than another.
Watermark alignment provides these benefits:
Reduces memory buffering requirements.
Improves performance by preventing excessive data buffering.
Prevents operational problems such as checkpointing failures.
Provides control over stream synchronization.
Confluent Cloud for Apache Flink enables watermark alignment by default.
Set the sql.tables.scan.watermark-alignment.max-allowed-drift session option to change the maximum allowed deviation, or watermark drift.
The default maximum watermark drift is 5 minutes. This value matches the default maximum idleness detection timeout, which is also 5 minutes. Otherwise, watermark alignment would occur while Flink waits for a partition to switch to idle, potentially wasting CPU resources.
Only increase the watermark alignment’s maximum allowed drift to match the idleness timeout when you increase the idleness timeout. For more information, see Validate or disable idleness handling.
Decrease the maximum allowed drift when both of these conditions are true:
Record throughput, expressed as records per minute of event time, is too high for windowed or temporal operators to buffer five minutes of data.
The window length is less than five minutes.
Time attributes
Confluent Cloud for Apache Flink can process data based on different notions of time.
Event time refers to stream processing based on timestamps that are attached to each row. The timestamps can encode when an event happened.
Processing time refers to the machine’s system time that’s executing the operation. Processing time is also known as “epoch time”, for example, Java’s
System.currentTimeMillis(). Processing time is not supported in Confluent Cloud for Apache Flink.
Time attributes can be part of every table schema. You define them when you create a table from a CREATE TABLE DDL statement.
After you define a time attribute, you can reference it as a field and use it in time-based operations. As long as a query does not modify a time attribute, and simply forwards it from one part of a query to another, it remains a valid time attribute.
Time attributes behave like regular timestamps and are accessible for calculations. When used in calculations, Flink materializes time attributes and they act as standard timestamps, but you can’t use ordinary timestamps in place of, or convert them to, time attributes.
Event-time attributes
An event-time attribute is a table column marked with a WATERMARK clause that enables time-based operations on event timestamps. Event time enables a table program to produce results based on timestamps in every record, which allows for consistent results despite out-of-order or late events. Event time also ensures the replayability of the results of the table program when reading records from persistent storage.
Also, event time enables unified syntax for table programs in both batch and streaming environments. A time attribute in a streaming environment can be a regular column of a row in a batch environment.
To handle out-of-order events and to distinguish between on-time and late events in streaming, Flink must know the timestamp for each row, and it also needs regular indications of how far along in event time the processing has progressed so far, by using watermarks.
You can define event-time attributes in CREATE TABLE statements.
Define event-time attributes in DDL
You define the event-time attribute by using a WATERMARK clause in a CREATE TABLE DDL statement. A watermark statement defines a watermark generation expression on an existing event-time field, which marks the event-time field as the event-time attribute. For more information about watermark strategies, see Watermark clause.
Flink SQL supports defining an event-time attribute on TIMESTAMP and TIMESTAMP_LTZ columns. If the source represents the timestamp data as year-month-day-hour-minute-second, usually a string value without time-zone information, for example, 2020-04-15 20:13:40.564, define the event-time attribute as a TIMESTAMP column.
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time TIMESTAMP(3),
-- Declare the user_action_time column as an event-time attribute
-- and use a 5-seconds-delayed watermark strategy.
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
If the source represents the timestamp data as epoch time, which is usually a LONG value such as 1618989564564, consider defining the event-time attribute as a TIMESTAMP_LTZ column.
CREATE TABLE user_actions (
user_name STRING,
data STRING,
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
-- Declare the time_ltz column as an event-time attribute
-- and use a 5-seconds-delayed watermark strategy.
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(time_ltz, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(time_ltz, INTERVAL '10' MINUTE);
Processing-time attributes
Processing time enables a table program to produce results based on the time of the local machine. It’s the simplest notion of time, but it generates non-deterministic results. Processing time doesn’t require timestamp extraction or watermark generation.
Processing time is not supported in Confluent Cloud for Apache Flink.