Query Iceberg Tables with AWS Analytics Services and Tableflow in Confluent Cloud
Tableflow integrates seamlessly with Amazon Athena by using the AWS Glue Data Catalog or the Tableflow Apache Iceberg™ REST Catalog, enabling you to query Apache Iceberg™ tables materialized by Tableflow as a read-only table.
Amazon Athena efficiently accesses and analyzes real-time streaming data managed by Tableflow, enabling powerful, serverless analytics at scale.
Use Amazon Athena with AWS Glue Data Catalog
To use Amazon Athena with AWS Glue Data Catalog, you must configure AWS Glue Catalog integration in Tableflow. When the catalog integration is complete, all materialized Iceberg tables of the Apache Kafka® cluster are discoverable in the AWS Glue Data Catalog.
With Amazon Athena, you can use Athena SQL or Amazon Athena for Spark when performing data analytics.
Amazon Athena SQL
You can use Athena SQL to query your data directly in Amazon S3 by using the AWS Glue Data Catalog.
Prerequisites
Configure AWS Glue Catalog integration in Tableflow.
Verify that Tableflow is enabled for the topic you want to materialize into a table by completing steps 1-3 in the Tableflow Quick Start.
Ensure you have the required permissions for Amazon Athena to access the table’s storage bucket.
Ensure AWS Athena has read-only access to the Glue catalog and the storage bucket.
After you configure the AWS Glue Data Catalog in Tableflow, follow these steps to query your materialized tables.
Log in to Amazon Athena and select Query your data with Trino SQL.
Start the Athena SQL query editor.
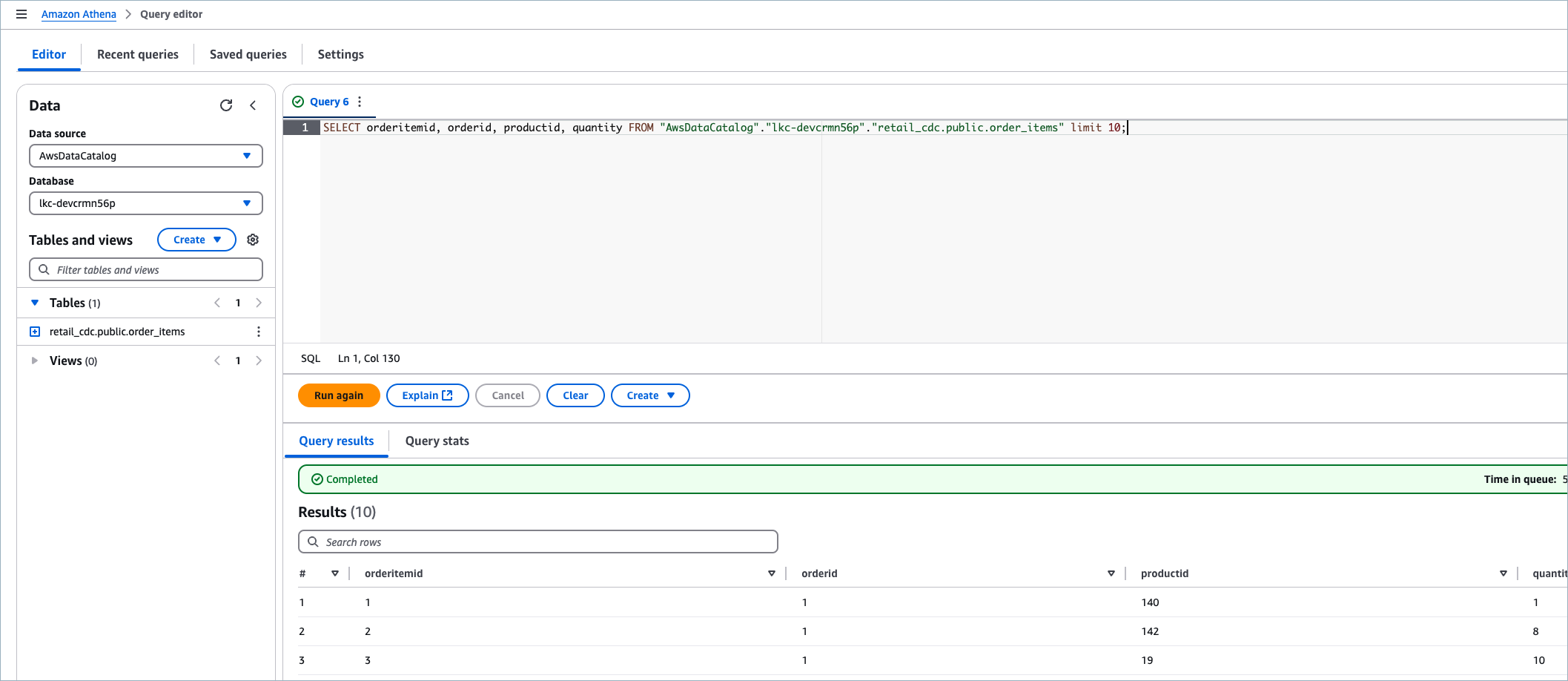
In the Data source dropdown, select AwsDataCatalog, which is the AWS Glue Data Catalog.
In the Database dropdown, select the database created based on the Kafka cluster ID in the Athena SQL Query Editor.
In the query editor, write an Athena SQL query to consume data from an Iceberg table that’s materialized by Tableflow, as shown in the following example.
SELECT orderitemid, orderid, productid, quantity FROM "AwsDataCatalog"."lkc-a1b2c3"."retail_cdc.public.order_items" LIMIT 10;
Amazon Athena for Spark (PySpark) with Tableflow Catalog
You can use Amazon Athena for Apache Spark to query Tableflow’s Iceberg tables by using AWS Glue Data Catalog as the Iceberg catalog.
Prerequisites
Configure AWS Glue Catalog integration in Tableflow.
Verify that Tableflow is enabled for the topic you want to materialize into a table by completing steps 1-3 in the Tableflow Quick Start.
Ensure you have the required permissions for Amazon Athena to access the storage bucket of the table.
Ensure AWS Athena has read-only access to the Glue catalog and the storage bucket.
Ensure that you have the values from Step 3 of the quick start.
Tableflow REST Catalog endpoint
Credentials to access the Tableflow REST Catalog
Log in to Amazon Athena and select Analyze your data using PySpark and Spark SQL.
Under the Athena workgroup, create a new notebook.
In the Workgroup textbox, enter a name, for example, “tableflow-wg”.
In the Apache Spark properties section, select Custom, which enables providing Spark properties in JSON format.
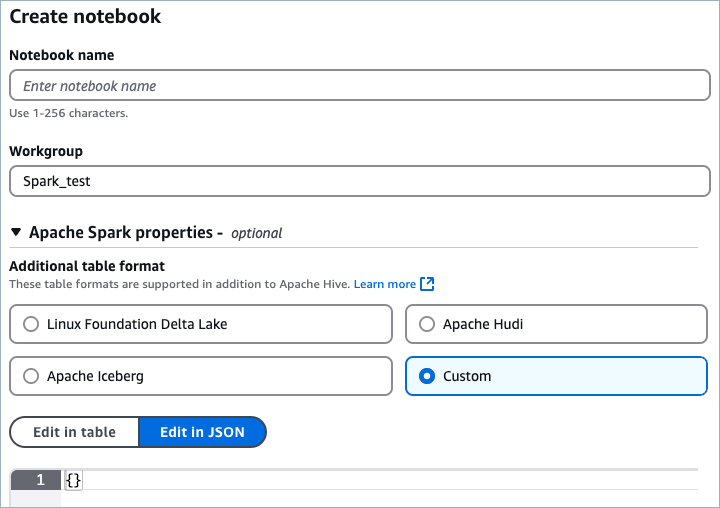
Copy the following Spark properties configuration to Athena.
Replace spark.sql.catalog.tableflow-cluster.uri and spark.sql.catalog.tableflow-cluster.credential with the values from Step 3 of the quick start.
{ "spark.sql.catalog.tableflow-cluster": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.tableflow-cluster.catalog-impl": "org.apache.iceberg.rest.RESTCatalog", "spark.sql.catalog.tableflow-cluster.credential": "<cloud-api-key>:<secret>", "spark.sql.catalog.tableflow-cluster.uri": "<Tableflow-REST-Catalog-URI>", "spark.sql.catalog.tableflowdemo.s3.remote-signing-enabled": "true", "spark.sql.defaultCatalog": "tableflow-cluster", "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" }
Replace your-glue-catalog-bucket with your value.
{ "spark.sql.catalog.glue": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.glue.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog", "spark.sql.catalog.glue.warehouse": "s3://<your-glue-catalog-bucket>/", "spark.sql.catalog.glue.io-impl": "org.apache.iceberg.aws.s3.S3FileIO", "spark.sql.catalog.glue_catalog.glue.skip-name-validation": "true", "spark.sql.defaultCatalog": "glue", "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" }
In Athena PySpark, run the following query to see the Iceberg tables in the Tableflow Catalog.
%%sql SHOW TABLES in `<your-kafka-cluster-id>`;
Select a table of your choice and query data with the following PySpark query.
%%sql SELECT * FROM `<your-kafka-cluster-id>`.`<table-name>`;
Amazon Redshift
You can use Amazon Redshift Spectrum or Redshift Serverless to query Iceberg tables registered in the AWS Glue Data Catalog as read-only tables.
Using Amazon Redshift with AWS Glue Data Catalog
Prerequisites
Configure AWS Glue Catalog integration in Tableflow.
Verify that Tableflow is enabled for the topic you want to materialize into a table by completing steps 1-3 in the Tableflow Quick Start.
To use Amazon Redshift with AWS Glue Data Catalog, you must configure AWS Glue Catalog integration in Tableflow. When the catalog integration is complete, all materialized Iceberg tables of the Kafka cluster are discoverable in the AWS Glue Data Catalog.
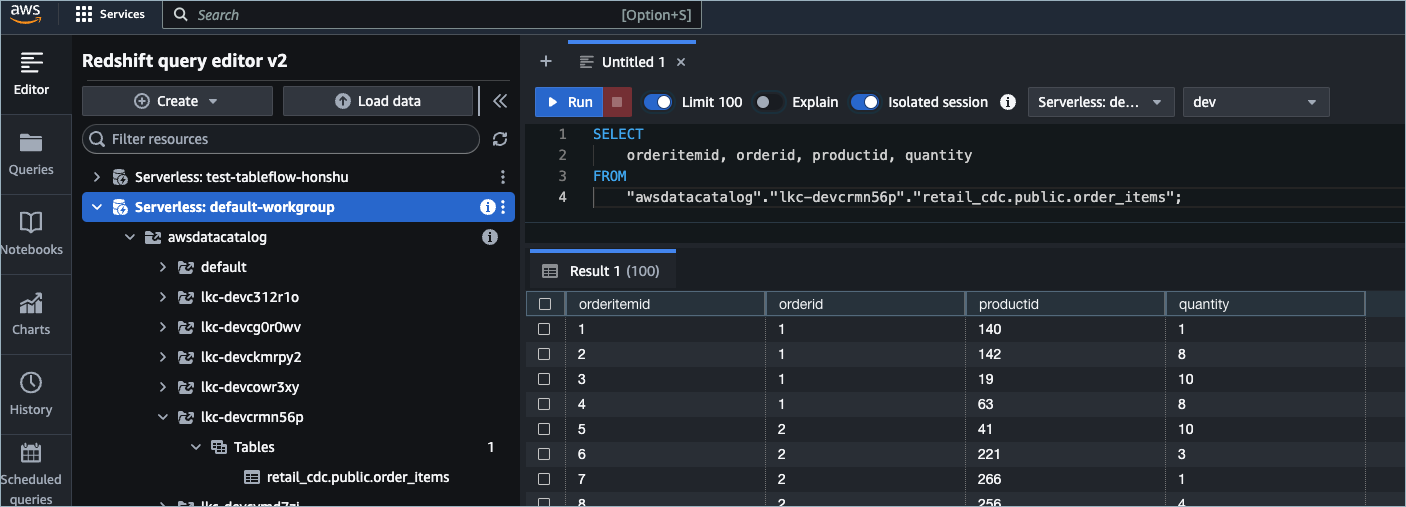
Create a new Amazon Redshift cluster and navigate to the Query Editor V2.
Navigate to the Redshift query editor and select awsdatacatalog as the catalog. Because Iceberg tables have already been published in the AWS Glue Data Catalog, you can discover and query them through awsdatacalog.
Amazon EMR
Using Amazon EMR with AWS Glue Data Catalog
Prerequisites
Configure AWS Glue Catalog integration in Tableflow.
Verify that Tableflow is enabled for the topic you want to materialize into a table by completing steps 1-3 in the Tableflow Quick Start.
Ensure you have the required permissions for Amazon Athena to access the storage bucket of the table.
Ensure AWS Athena has read-only access to the Glue catalog and the storage bucket.
To use Amazon EMR with AWS Glue Data Catalog, you must configure AWS Glue Catalog integration in Tableflow.
Log in to Amazon EMR Studio, and create a new Studio and a Spark workspace.
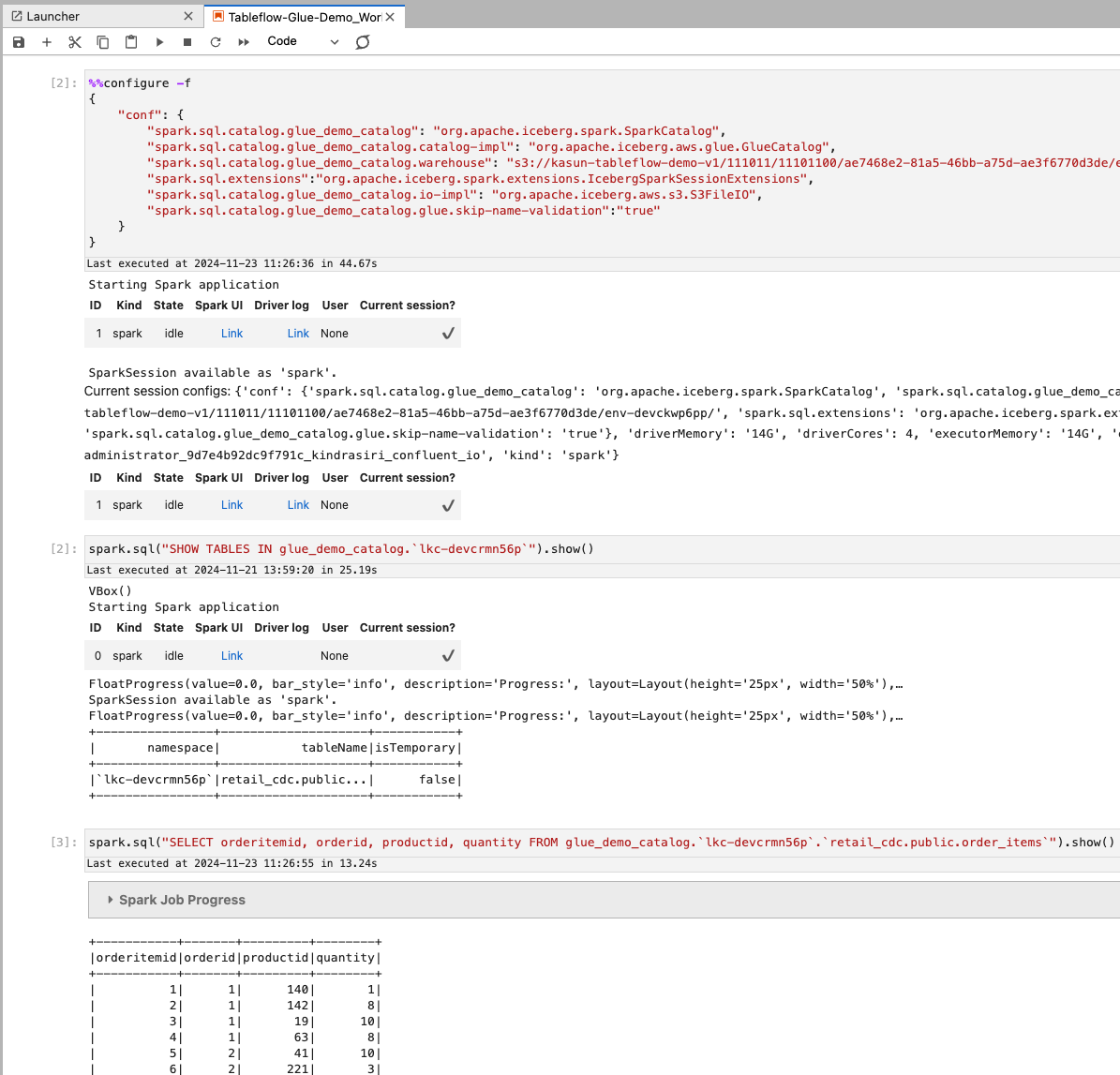
In Amazon EMR, run the
configure -fcommand with the following configuration. Replace your-warehouse with the value for your warehouse.Configure Spark to use the AWS Glue Data Catalog by providing the catalog implementation,
org.apache.iceberg.aws.glue.GlueCatalog. Replace your-warehouse with the value for your warehouse.%%configure -f { "conf": { "spark.sql.catalog.glue_demo_catalog": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.glue_demo_catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog", "spark.sql.catalog.glue_demo_catalog.warehouse": "s3://<your-warehouse>", "spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", "spark.sql.catalog.glue_demo_catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO", "spark.sql.catalog.glue_demo_catalog.glue.skip-name-validation":"true" } }Run the following Spark queries to consume the Iceberg tables created by Tableflow.
spark.sql("SHOW TABLES IN glue_demo_catalog.`lkc-devcrmn56p`").show() spark.sql("SELECT orderitemid, orderid, productid, quantity FROM glue_demo_catalog.`lkc-devcrmn56p`.`retail_cdc.public.order_items`").show()
Your output should resemble: