
Tutorial: Use Confluent Replicator to Copy Kafka Data to Confluent Cloud
Whether you are migrating from on-premises to cloud or have a persistent bridge-to-cloud strategy, you can use Confluent Replicator to copy Apache Kafka® data to Confluent Cloud. Learn the different ways to configure Replicator and Kafka Connect.

Important
Confluent Cloud examples that use actual Confluent Cloud resources might be billable. An example might create a new Confluent Cloud environment, Kafka cluster, topics, ACLs, service accounts, or resources that have hourly charges like connectors and ksqlDB applications. To avoid unexpected charges, carefully evaluate the cost of resources before you start. After you are done running a Confluent Cloud example, destroy all Confluent Cloud resources to avoid accruing hourly charges for services and verify that they have been deleted.
Concepts
Before diving into the different ways to configure Replicator, first review some basic concepts about Replicator and Kafka Connect. This helps you understand the logic for configuring Replicator because the way that the Kafka Connect cluster is configured dictates how Replicator should be configured.
Replicator is a Kafka connector and runs on Connect workers. Even the Replicator executable has a bundled Connect worker inside.
Replicator has an embedded consumer that reads data from the origin cluster, and the Connect worker has an embedded producer that copies that data to the destination cluster, which in this case is Confluent Cloud. To configure the proper connection information for Replicator to interact with the origin cluster, use the src. prefix. Replicator also has an admin client that it needs for interacting with the destination cluster, and you configure this client with the dest. prefix.
A Connect worker also has an admin client for creating Kafka topics for its own management, offset.storage.topic, config.storage.topic, and status.storage.topic, and these are in the Kafka cluster that backs the Connect worker. You can configure the Kafka Connect embedded producer directly on the Connect worker, or any connector, including Replicator, can override it.
Configuration types
The first type is where Replicator runs on a self-managed Connect cluster that is backed to the destination Confluent Cloud cluster. This allows Replicator, which is a source connector, to use the default behavior of the Connect worker’s admin client and embedded producer.
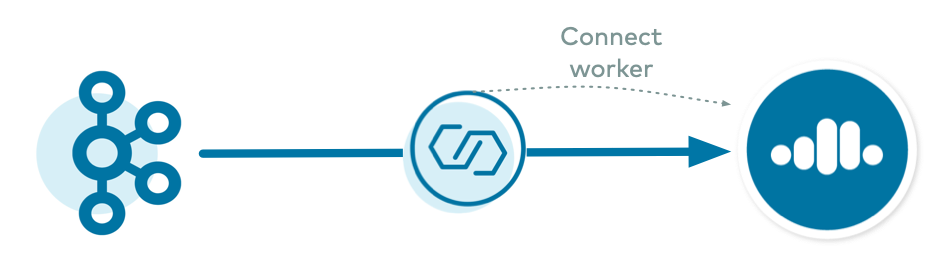
For this case where Replicator runs on a Connect cluster backed to destination, there are two configuration examples:
On-premises to Confluent Cloud with Connect backed to destination
Confluent Cloud to Confluent Cloud with Connect backed to destination
In some scenarios, you cannot back your self-managed Connect cluster to the destination Confluent Cloud cluster. For example, some highly secure clusters might block incoming network connections and only allow push connections, in which case an incoming connection from Replicator running on the destination cluster to the origin cluster fails. In this case, you can back a Connect cluster to the origin cluster instead and push the replicated data to the destination cluster. This second configuration type is more complex because there are overrides you need to configure.
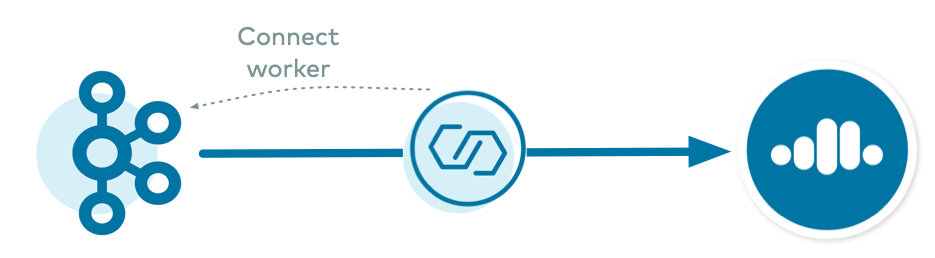
For this case where Replicator runs on a Connect cluster backed to origin, there are two configuration examples:
Connect cluster backed to destination
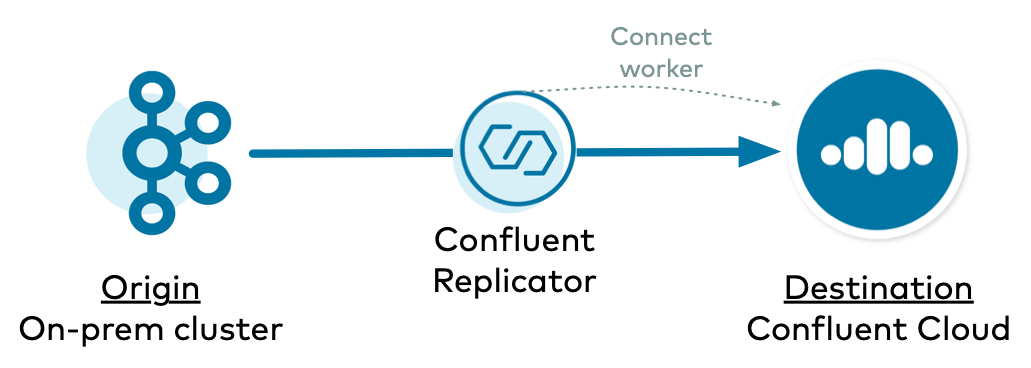
On-premises to Confluent Cloud with Connect backed to destination
In this example, Replicator copies data from an on-premises Kafka cluster to Confluent Cloud, and Replicator runs on a Connect cluster backed to the destination Confluent Cloud cluster.
Tip
These examples show only the significant configuration parameters for the Connect worker and Replicator. For an example with complete configurations, see the Connect worker backed to destination Docker configuration and the Replicator reading from an on-premises cluster configuration file.
This tutorial shows how to use Replicator to copy data across Confluent Cloud, Confluent Platform, or both deployment types, but does not describe Docker configurations. If you want to run the examples using Docker, see Confluent Replicator configuration to learn how to convert the configurations for those scenarios.
Configure Kafka Connect
Set the management topics to replication factor of 3 as required by Confluent Cloud.
replication.factor=3
config.storage.replication.factor=3
offset.storage.replication.factor=3
status.storage.replication.factor=3
The Connect worker’s admin client requires connection information to the destination Confluent Cloud.
# Configuration for embedded admin client
bootstrap.servers=<bootstrap-servers-destination>
sasl.mechanism=PLAIN
security.protocol=SASL_SSL
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
The Connect worker’s embedded producer requires connection information to the destination Confluent Cloud.
# Configuration for embedded producer
producer.sasl.mechanism=PLAIN
producer.security.protocol=SASL_SSL
producer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
If you are using Confluent Control Center (Legacy) and doing stream monitoring then the embedded producer’s monitoring interceptors require connection information to the destination Confluent Cloud.
# Configuration for embedded producer.confluent.monitoring.interceptor
producer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
producer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
producer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Configure Replicator
The origin cluster in this case is your on-premises Kafka cluster, and Replicator needs to know how to connect to this origin cluster which can be set by using the prefix src. for these configuration parameters. The origin cluster can have a varied set of security features enabled, but for simplicity this example shows no security configurations, just PLAINTEXT (see this page for more Replicator security configuration options).
src.kafka.bootstrap.servers=<bootstrap-servers-origin>
The destination cluster is your Confluent Cloud cluster, and Replicator needs to know how to connect to it. Use the prefix dest. to set these configuration parameters.
# Confluent Replicator license topic must have replication factor set to 3 for Confluent Cloud
confluent.topic.replication.factor=3
# New user topics that Confluent Replicator creates must have replication factor set to 3 for Confluent Cloud
dest.topic.replication.factor=3
If your deployment has Confluent Control Center end-to-end streams monitoring setup to gather data in Confluent Cloud, then you also need to setup the Confluent Monitoring Interceptors to send data to your Confluent Cloud cluster, which also requires appropriate connection information set for the embedded consumer with the prefix src.consumer.
src.consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
src.consumer.confluent.monitoring.interceptor.bootstrap.servers=<bootstrap-servers-destination>
src.consumer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
src.consumer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
src.consumer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Configure ACLs
Replicator must have authorization to read Kafka data from the origin cluster and write Kafka data in the destination Confluent Cloud cluster. Replicator should be run with a Confluent Cloud service account, not super user credentials, so use the Confluent CLI to configure appropriate ACLs for the service account id corresponding to Replicator in Confluent Cloud.
For details on how to configure these ACLs for Replicator, see Security and ACL Configurations.
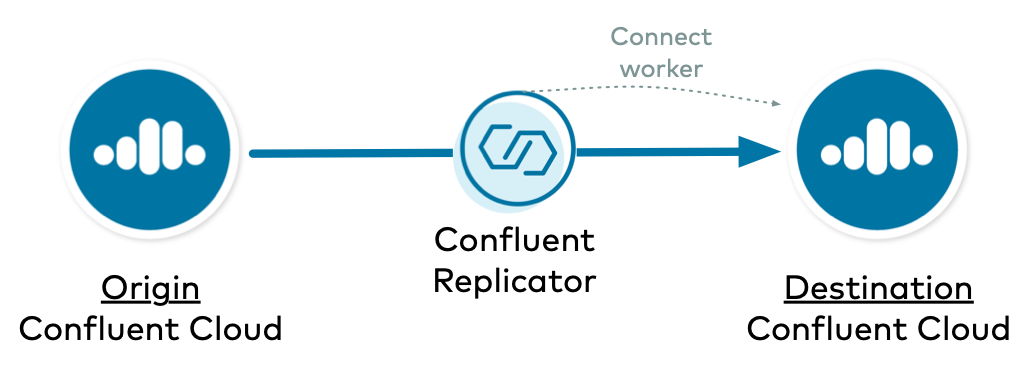
Confluent Cloud to Confluent Cloud with Connect backed to destination
In this example, Replicator copies data from one Confluent Cloud cluster to another Confluent Cloud cluster, and Replicator runs on a Connect cluster backed to the destination Confluent Cloud cluster.
Tip
These examples show only the significant configuration parameters for the Connect worker and Replicator. For an example with complete configurations, see the Connect worker backed to destination Docker configuration and the Replicator reading from Confluent Cloud configuration file.
This tutorial shows how to use Replicator to copy data across Confluent Cloud, Confluent Platform, or both deployment types, but does not describe Docker configurations. If you want to run the examples using Docker, see Confluent Replicator configuration to learn how to convert the configurations for those scenarios.
Configure Kafka Connect
Set the management topics to replication factor of 3 as required by Confluent Cloud.
replication.factor=3
config.storage.replication.factor=3
offset.storage.replication.factor=3
status.storage.replication.factor=3
The Connect worker’s admin client requires connection information to the destination Confluent Cloud.
# Configuration for embedded admin client
bootstrap.servers=<bootstrap-servers-destination>
sasl.mechanism=PLAIN
security.protocol=SASL_SSL
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
The Connect worker’s embedded producer requires connection information to the destination Confluent Cloud.
# Configuration for embedded producer
producer.sasl.mechanism=PLAIN
producer.security.protocol=SASL_SSL
producer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
If you are using Confluent Control Center (Legacy) and doing stream monitoring then the embedded producer’s monitoring interceptors require connection information to the destination Confluent Cloud.
# Configuration for embedded producer.confluent.monitoring.interceptor
producer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
producer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
producer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Configure Replicator
The origin cluster in this case is a Confluent Cloud cluster, and Replicator admin client needs to know how to connect to this origin cluster, which can be configured by using the prefix src.kafka. for these connection configuration parameters.
src.kafka.bootstrap.servers=<bootstrap-servers-origin>
src.kafka.security.protocol=SASL_SSL
src.kafka.sasl.mechanism=PLAIN
src.kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-origin>" password="<api-secret-origin>";
The destination cluster is your Confluent Cloud cluster, and Replicator needs to know how to connect to it. Use the prefix dest. to set these configuration parameters.
# Confluent Replicator license topic must have replication factor set to 3 for Confluent Cloud
confluent.topic.replication.factor=3
# New user topics that Confluent Replicator creates must have replication factor set to 3 for Confluent Cloud
dest.topic.replication.factor=3
If your deployment has Confluent Control Center end-to-end streams monitoring setup to gather data in Confluent Cloud, then you also need to setup the Confluent Monitoring Interceptors to send data to your Confluent Cloud cluster, which also requires appropriate connection information set for the embedded consumer with the prefix src.consumer.
src.consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
src.consumer.confluent.monitoring.interceptor.bootstrap.servers=<bootstrap-servers-destination>
src.consumer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
src.consumer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
src.consumer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Configure ACLs
Replicator must have authorization to read Kafka data from the origin cluster and write Kafka data in the destination Confluent Cloud cluster. Replicator should be run with a Confluent Cloud service account, not super user credentials, so use the Confluent CLI to configure appropriate ACLs for the service account id corresponding to Replicator. Since the origin cluster and destination cluster in this example are both Confluent Cloud, configure appropriate ACLs for the service account ids corresponding to Replicator in both Confluent Cloud clusters.
For details on how to configure these ACLs for Replicator, see Security and ACL Configurations.
Connect cluster backed to origin
On-premises to Confluent Cloud with Connect backed to origin
In this example, Replicator copies data from an on-premises Kafka cluster to Confluent Cloud, and Replicator runs on a Connect cluster backed to the origin on-premises cluster.
Tip
These examples show only the significant configuration parameters for the Connect worker and Replicator. For an example with complete configurations, see the Connect worker backed to origin Docker configuration and the Replicator reading from an on-premises cluster configuration file.
This tutorial shows how to use Replicator to copy data across Confluent Cloud, Confluent Platform, or both deployment types, but does not describe Docker configurations. If you want to run the examples using Docker, see Confluent Replicator configuration to learn how to convert the configurations for those scenarios.
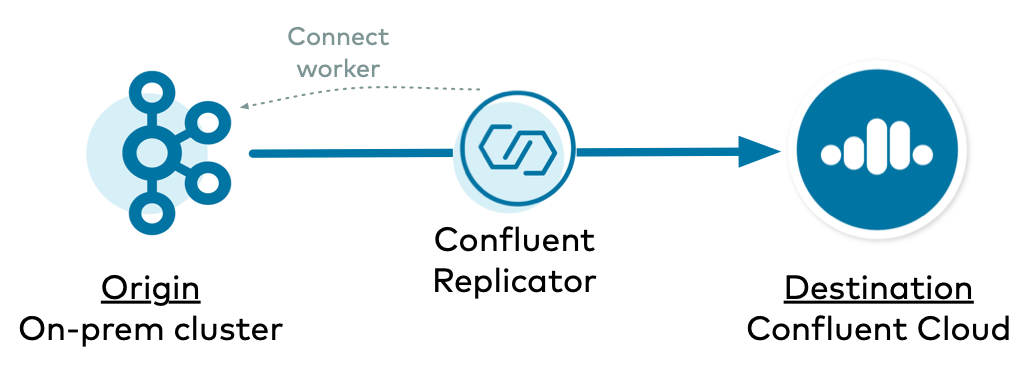
Configure Kafka Connect
The Connect worker is backed to the origin on-premises Kafka cluster, so set the replication factor required for the origin on-premises cluster:
replication.factor=<replication-factor-origin>
config.storage.replication.factor=<replication-factor-origin>
offset.storage.replication.factor=<replication-factor-origin>
status.storage.replication.factor=<replication-factor-origin>
The origin on-premises Kafka cluster can have a varied set of security features enabled, but for simplicity in this example we show no security configurations, just PLAINTEXT (see this page for more Replicator security configuration options). The Connect worker’s admin client requires connection information to the on-premises cluster.
bootstrap.servers=<bootstrap-servers-origin>
Finally, configure the Connect worker to allow overrides, because Replicator needs to override the default behavior of the Connect worker’s embedded producer.
connector.client.config.override.policy=All
Configure Replicator
The origin cluster in this case is your on-premises Kafka cluster, and Replicator needs to know how to connect to this origin cluster which can be set by using the prefix src. for these configuration parameters. The origin cluster can have a varied set of security features enabled, but for simplicity this example shows no security configurations, just PLAINTEXT (see this page for more Replicator security configuration options).
src.kafka.bootstrap.servers=<bootstrap-servers-origin>
The destination cluster is your Confluent Cloud cluster, and Replicator needs to know how to connect to it. Use the prefix dest. to set these configuration parameters.
# Confluent Replicator license topic must have replication factor set to 3 for Confluent Cloud
confluent.topic.replication.factor=3
# New user topics that Confluent Replicator creates must have replication factor set to 3 for Confluent Cloud
dest.topic.replication.factor=3
# Connection information to Confluent Cloud
dest.kafka.bootstrap.servers=<bootstrap-servers-destination>
dest.kafka.security.protocol=SASL_SSL
dest.kafka.sasl.mechanism=PLAIN
dest.kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
If your deployment has Confluent Control Center (Legacy) end-to-end streams monitoring setup to gather data in Confluent Cloud, then you also need to setup the Confluent Monitoring Interceptors to send data to your Confluent Cloud cluster, which also requires appropriate connection information set for the embedded consumer with the prefix src.consumer.
src.consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
src.consumer.confluent.monitoring.interceptor.bootstrap.servers=<bootstrap-servers-destination>
src.consumer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
src.consumer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
src.consumer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Since the Connect workers are backed to the origin cluster, its embedded producers would write to the origin cluster, which is not desired in this case. To override the embedded producers, configure Replicator to write to the destination Confluent Cloud cluster by adding connection information to Confluent Cloud with the prefix producer.override.:
producer.override.bootstrap.servers=<bootstrap-servers-destination>
producer.override.security.protocol=SASL_SSL
producer.override.sasl.mechanism=PLAIN
producer.override.sasl.login.callback.handler.class=org.apache.kafka.common.security.authenticator.AbstractLogin$DefaultLoginCallbackHandler
producer.override.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Configure ACLs
Replicator must have authorization to read Kafka data from the origin cluster and write Kafka data in the destination Confluent Cloud cluster. Replicator should be run with a Confluent Cloud service account, not super user credentials, so use the Confluent CLI to configure appropriate ACLs for the service account id corresponding to Replicator in Confluent Cloud.
For details on how to configure these ACLs for Replicator, see Security and ACL Configurations.
Confluent Cloud to Confluent Cloud with Connect backed to origin
In this example, Replicator copies data from one Confluent Cloud cluster to another Confluent Cloud cluster, and Replicator runs on a Connect cluster backed to the origin Confluent Cloud cluster.
Tip
These examples show only the significant configuration parameters for the Connect worker and Replicator. For an example with complete configurations, see the Connect worker backed to origin Docker configuration and the Replicator reading from Confluent Cloud configuration file.
This tutorial shows how to use Replicator to copy data across Confluent Cloud, Confluent Platform, or both deployment types, but does not describe Docker configurations. If you want to run the examples using Docker, see Confluent Replicator configuration to learn how to convert the configurations for those scenarios.
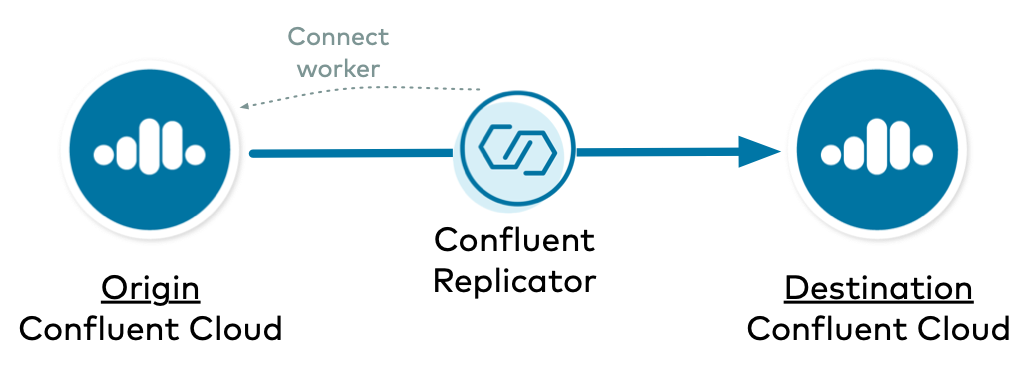
Configure Kafka Connect
Set the management topics to replication factor of 3 as required by Confluent Cloud.
replication.factor=3
config.storage.replication.factor=3
offset.storage.replication.factor=3
status.storage.replication.factor=3
The Connect worker’s admin client requires connection information to the origin Confluent Cloud.
# Configuration for embedded admin client
bootstrap.servers=<bootstrap-servers-destination>
sasl.mechanism=PLAIN
security.protocol=SASL_SSL
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-origin>" password="<api-secret-origin>";
The Connect worker’s embedded producer requires connection information to the origin Confluent Cloud.
# Configuration for embedded producer
producer.sasl.mechanism=PLAIN
producer.security.protocol=SASL_SSL
producer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-origin>" password="<api-secret-origin>";
If you are using Confluent Control Center (Legacy) and doing stream monitoring then the embedded producer’s monitoring interceptors require connection information to the origin Confluent Cloud.
# Configuration for embedded producer.confluent.monitoring.interceptor
producer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
producer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
producer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-origin>" password="<api-secret-origin>";
Finally, configure the Connect worker to allow overrides, because Replicator needs to override the default behavior of the Connect worker’s embedded producer.
connector.client.config.override.policy=All
Configure Replicator
The origin cluster in this case is a Confluent Cloud cluster, and Replicator admin client needs to know how to connect to this origin cluster, which can be configured by using the prefix src.kafka. for these connection configuration parameters.
src.kafka.bootstrap.servers=<bootstrap-servers-origin>
src.kafka.security.protocol=SASL_SSL
src.kafka.sasl.mechanism=PLAIN
src.kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-origin>" password="<api-secret-origin>";
The destination cluster is your Confluent Cloud cluster, and Replicator needs to know how to connect to it. Use the prefix dest. to set these configuration parameters.
# Confluent Replicator license topic must have replication factor set to 3 for Confluent Cloud
confluent.topic.replication.factor=3
# New user topics that Confluent Replicator creates must have replication factor set to 3 for Confluent Cloud
dest.topic.replication.factor=3
# Connection information to Confluent Cloud
dest.kafka.bootstrap.servers=<bootstrap-servers-destination>
dest.kafka.security.protocol=SASL_SSL
dest.kafka.sasl.mechanism=PLAIN
dest.kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
If your deployment has Confluent Control Center (Legacy) end-to-end streams monitoring setup to gather data in Confluent Cloud, then you also need to setup the Confluent Monitoring Interceptors to send data to your Confluent Cloud cluster, which also requires appropriate connection information set for the embedded consumer with the prefix src.consumer.
src.consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
src.consumer.confluent.monitoring.interceptor.bootstrap.servers=<bootstrap-servers-destination>
src.consumer.confluent.monitoring.interceptor.security.protocol=SASL_SSL
src.consumer.confluent.monitoring.interceptor.sasl.mechanism=PLAIN
src.consumer.confluent.monitoring.interceptor.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Since the Connect workers are backed to the origin cluster, its embedded producers would write to the origin cluster, which is not desired in this case. To override the embedded producers, configure Replicator to write to the destination Confluent Cloud cluster by adding connection information to Confluent Cloud with the prefix producer.override.:
producer.override.bootstrap.servers=<bootstrap-servers-destination>
producer.override.security.protocol=SASL_SSL
producer.override.sasl.mechanism=PLAIN
producer.override.sasl.login.callback.handler.class=org.apache.kafka.common.security.authenticator.AbstractLogin$DefaultLoginCallbackHandler
producer.override.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<api-key-destination>" password="<api-secret-destination>";
Configure ACLs
Replicator must have authorization to read Kafka data from the origin cluster and write Kafka data in the destination Confluent Cloud cluster. Replicator should be run with a Confluent Cloud service account, not super user credentials, so use the Confluent CLI to configure appropriate ACLs for the service account id corresponding to Replicator. Since the origin cluster and destination cluster in this example are both Confluent Cloud, configure appropriate ACLs for the service account ids corresponding to Replicator in both Confluent Cloud clusters.
For details on how to configure these ACLs for Replicator, see Security and ACL Configurations.
Any Confluent Cloud example uses real Confluent Cloud resources. After you are done running a Confluent Cloud example, manually verify that all Confluent Cloud resources are destroyed to avoid unexpected charges.